文章目录
登录微信公众平台
官网链接:https://mp.weixin.qq.com/
第一次需要小伙伴们点击注册按钮,进行注册,如果有账号,直接扫描登录即可
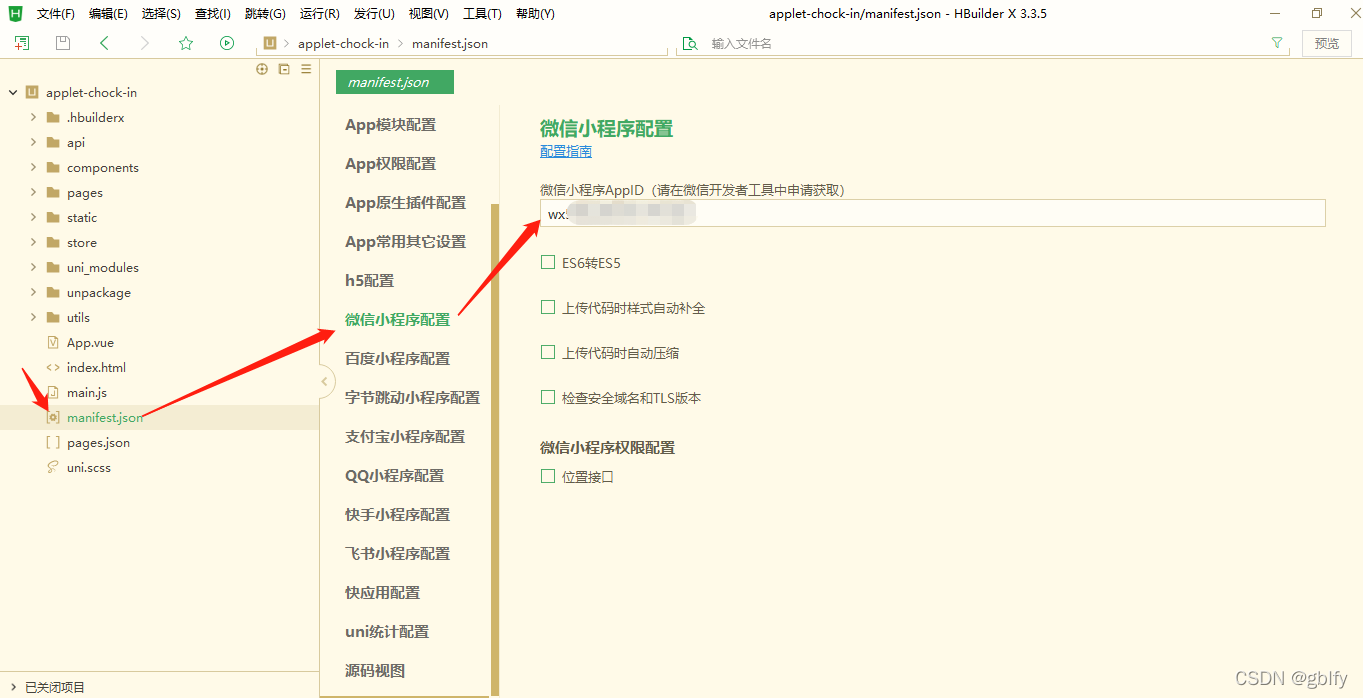
在manifest.json中输入申请的微信小程序id
这里给小伙伴们演示二种api
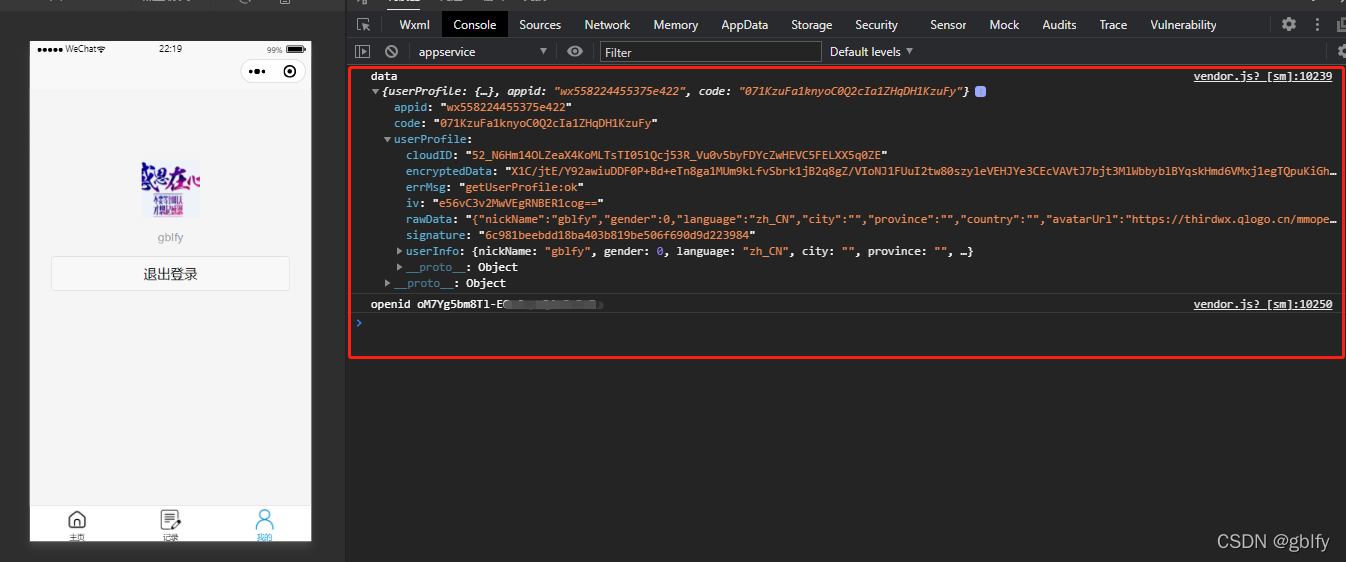
可以使用uni.getUserProfile请求用户授权获取用户信息, 也可以使用uni.getUserInfo获取
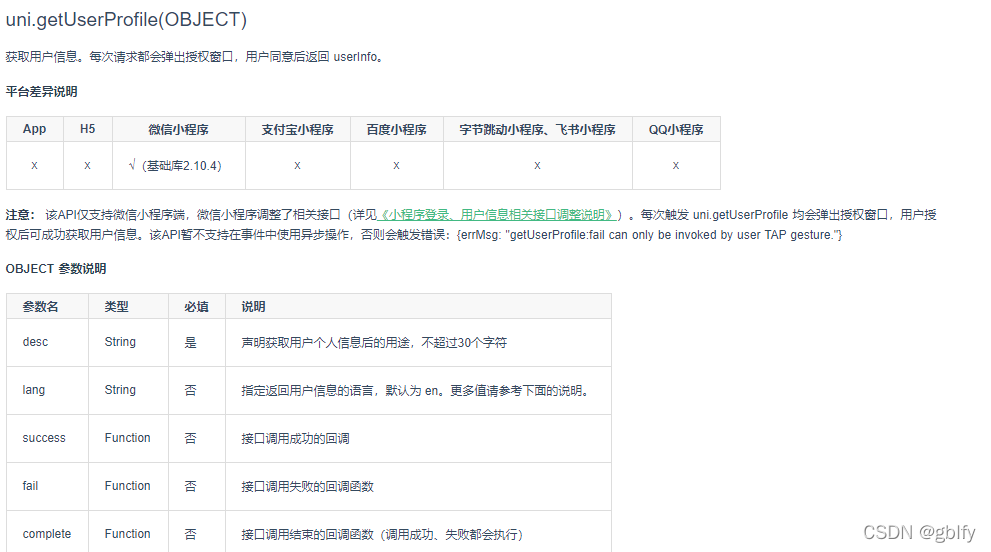
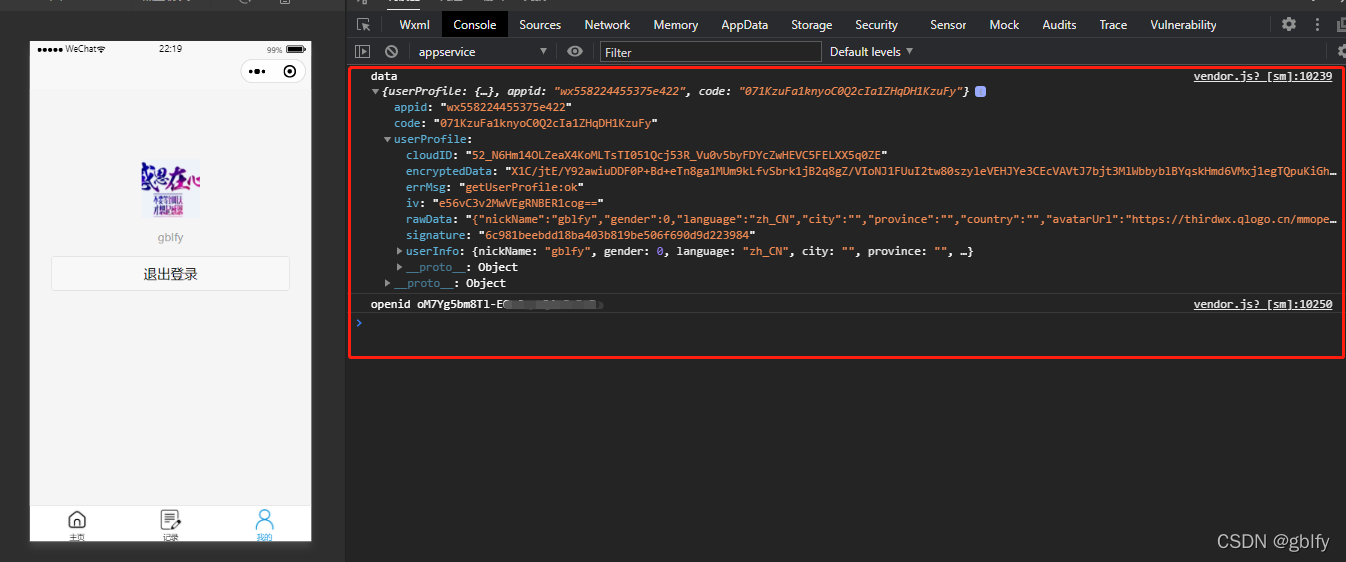
授权成功后获取到的用户信息在userInfo中:
<button class="login-btn" type="primary" @click="getUserInfo">
微信用户一键登录
</button>
methods: {
getUserInfo() {
uni.getUserInfo({
provider: 'weixin',
success: (res) => {
console.log('getUserInfo', res);
},
});
},
}
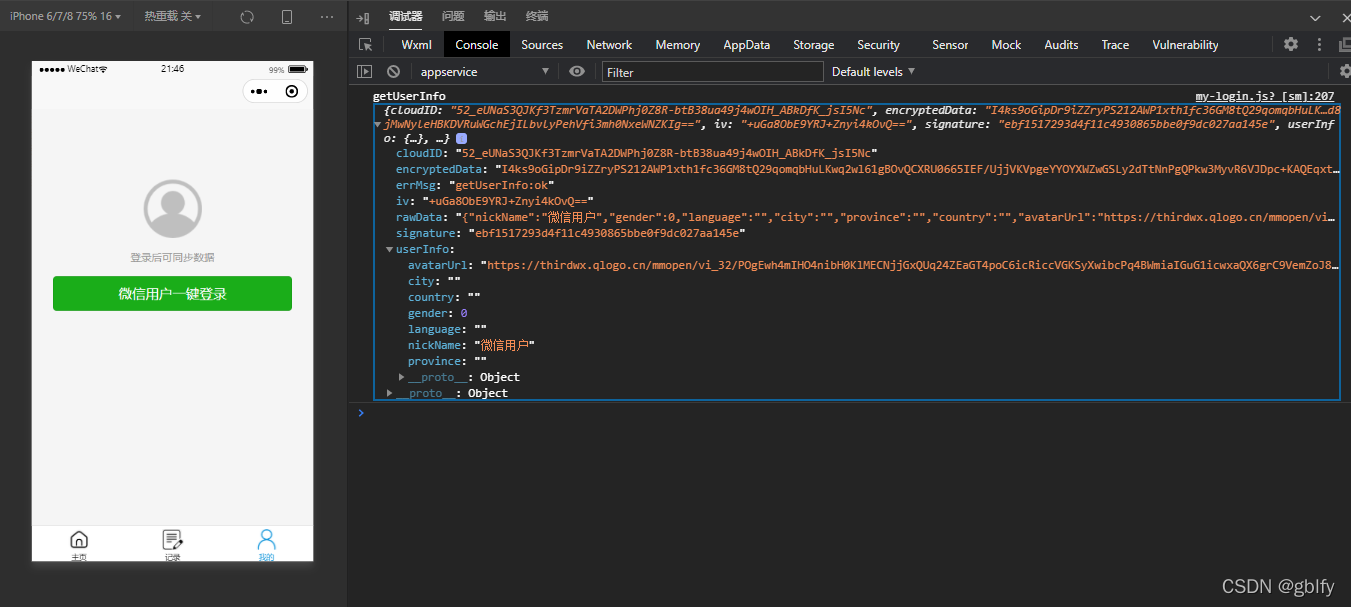
可以使用uni.getUserInfo请求用户授权获取用户信息
getUserInfo() {
uni.getUserProfile({
desc: '登录后可同步数据',
lang: 'zh_CN',
success: (res) => {
console.log('getUserProfile', res);
},
});
},
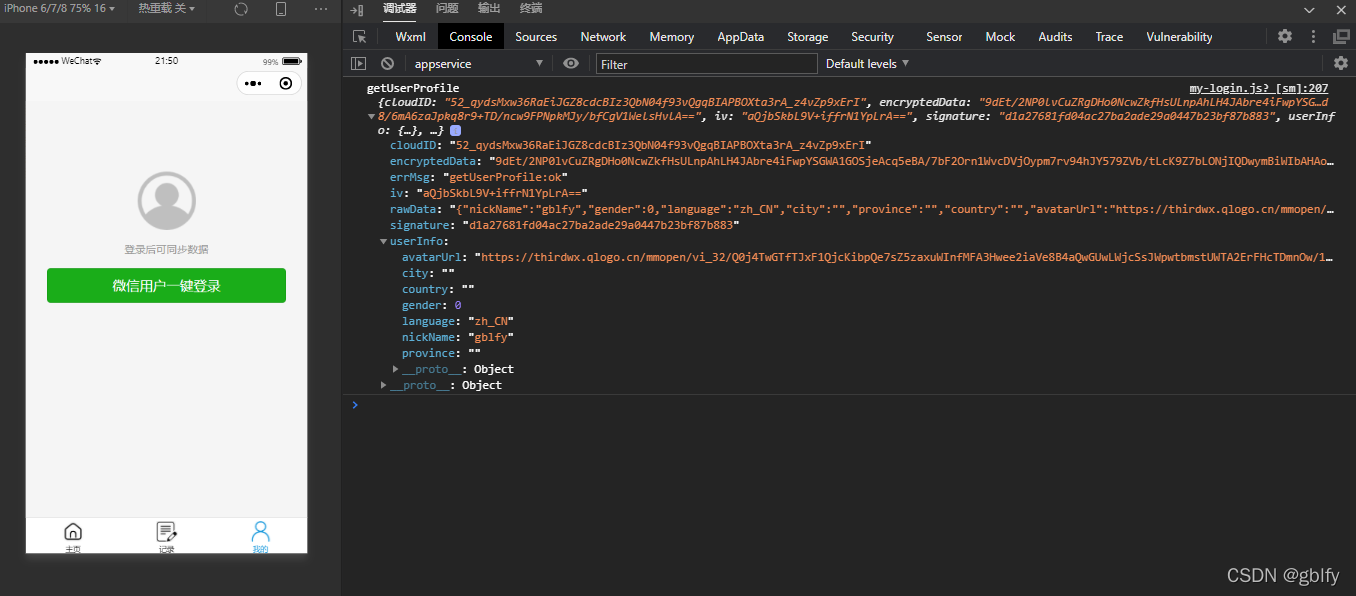
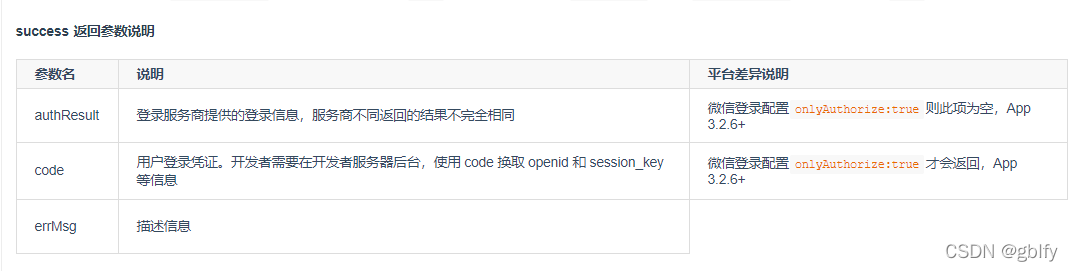
使用uni.login方法,provider参数输入’weixin’,成功的返回值中如果errMsg=“login:ok” 代表成功,
微信小程序端会返回一个code字符串
uni.login({
provider: 'weixin',
success: (res) => {
console.log('res-login', res);
this.code = res.code;
console.log('code', res.code);
if (res.errMsg == 'login:ok') {
//TODO 获取code 携带code参数调用后端接口}
官网文档
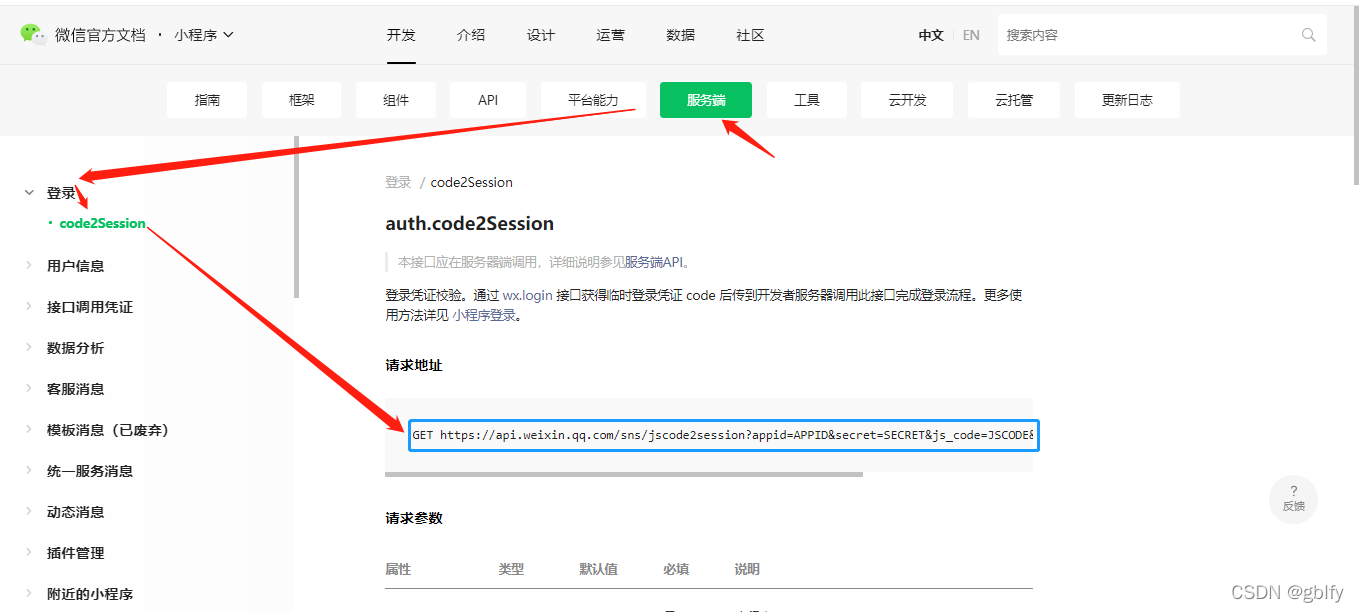
使用获取到的code请求微信登录接口,获取 openid 和 session_key

请求方式:GET
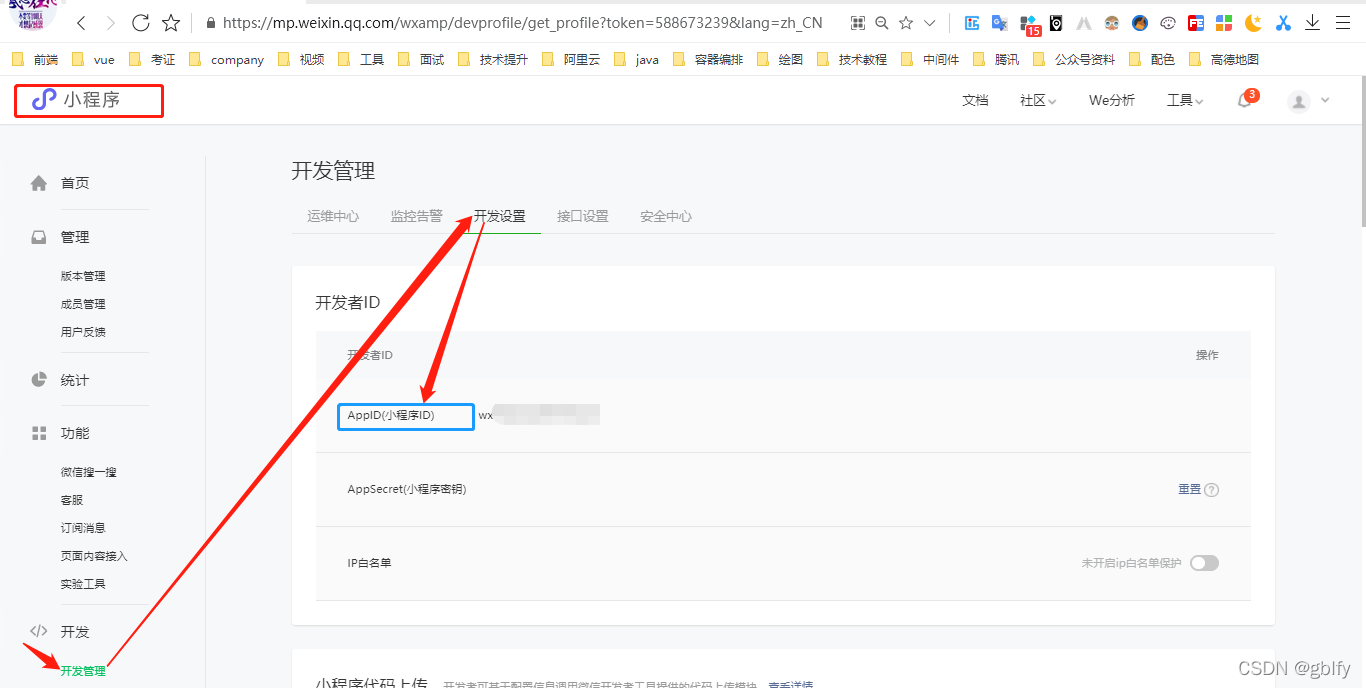
APPID:小程序唯一标识,上面有获取方式
SECRET:小程序唯一标识的秘钥,上面参考APPID获取方式,就在他的下面
JSCODE:这个前端调用 uni.login获取
GET https://api.weixin.qq.com/sns/jscode2session?appid=APPID&secret=SECRET&js_code=JSCODE&grant_type=authorization_code
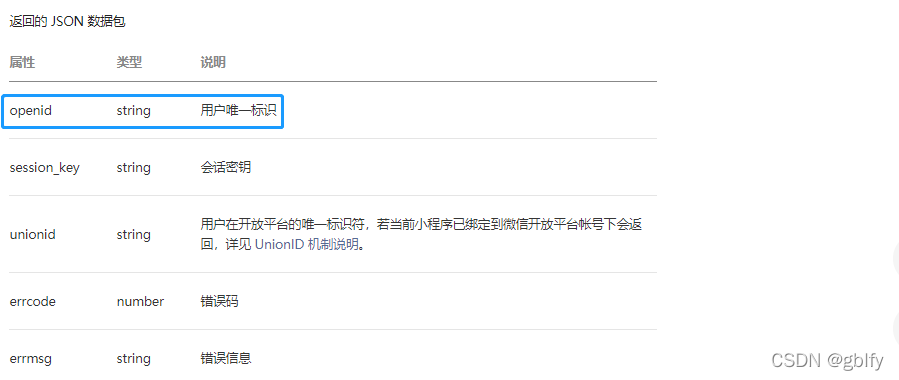
获取到微信用户的唯一id后,就可以绑定至自己系统中的用户,我的做法是在用户表中加入weixinId字段,跳转至自己的用户绑定界面,如果用户选择绑定微信,则更新该行用户数据的weixinId。下次用户使用微信登录时,如果通过openId能够查询到一条用户数据,说明已经绑定,则登录该用户
/**
*
* 获取用户信息
*/
getUserInfo() {
// 展示加载框
uni.showLoading({
title: '加载中',
});
uni.getUserProfile({
desc: '登录后可同步数据',
success: async (obj) => {
console.log('obj', obj);
// 调用 action ,请求登录接口
// await this.login(obj);
uni.login({
provider: 'weixin',
success: (res) => {
console.log('res-login', res);
this.code = res.code;
console.log('code', res.code);
if (res.errMsg == 'login:ok') {
uni
.request({
url:
'http://127.0.0.1:8080/wxh5/wx/user/' +
'wx55822xxxx75e422' +
'/login/',
data: {
code: this.code,
},
})
.then((res) => {
//获取到 openid 和 session_k后,自己的逻辑
console.log('授权登录', res[1].data);
console.log(res[1].data.openid);
console.log(res[1].data.session_key);
// DoSomeThing.................
});
console.log('res', res);
}
},
});
},
fail: () => {
uni.showToast({
title: '授权已取消',
icon: 'error',
mask: true,
});
},
complete: () => {
// 隐藏loading
uni.hideLoading();
},
});
},
@GetMapping("/login")
public String login(@PathVariable String appid, String code) {
if (StringUtils.isBlank(code)) {
return "empty jscode";
}
final WxMaService wxService = WxMaConfiguration.getMaService(appid);
try {
WxMaJscode2SessionResult session = wxService.getUserService().getSessionInfo(code);
this.logger.info(session.getSessionKey());
this.logger.info(session.getOpenid());
//TODO 可以增加自己的逻辑,关联业务相关数据
return JsonUtils.toJson(session);
} catch (WxErrorException e) {
this.logger.error(e.getMessage(), e);
return e.toString();
}
}
/**
*
* 获取用户信息
*/
getUserInfo() {
// 展示加载框
uni.showLoading({
title: '加载中',
});
uni.getUserProfile({
desc: '登录后可同步数据',
success: async (obj) => {
// this.userInfo = obj.userInfo;
// 调用 action ,请求登录接口
uni.login({
provider: 'weixin',
success: async (res) => {
this.code = res.code;
// console.log('登录获取code', res.code);
if (res.errMsg == 'login:ok') {
await this.loginAuth({
userProfile: obj,
appid: 'wx558xxxxxxxxxxxxxxx2',
code: this.code,
});
}
},
});
},
fail: () => {
uni.showToast({
title: '授权已取消',
icon: 'error',
mask: true,
});
},
complete: () => {
// 隐藏loading
uni.hideLoading();
},
});
},
},
user.js
/**
* 微信用户授权登录,携带appid和code参数,调用后端接口获取Openid
*/
export function loginAuth(data) {
return request({
url: '/wx/user/' + data.appid + '/login/',
data: {
code: data.code,
},
});
}
vuex user模块(user.js)
// 微信用户授权登录,携带appid和code参数,调用后端接口获取Openid
async loginAuth(context, data) {
console.log('data', data);
const userInfo = data.userProfile;
const { content: res } = await loginAuth({
appid: data.appid,
code: data.code,
});
// 解析后端传送过来的json对象
const userAuthInfo = JSON.parse(res);
const openid = userAuthInfo.openid;
// console.log('sessionKey', userAuthInfo.sessionKey);
console.log('openid', openid);
// 保存到vuex中,通过commit
this.commit('user/setOpenid', userAuthInfo.openid);
this.commit('user/setUserInfo', JSON.parse(userInfo.rawData));
},
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
我正在使用Postgres.app在OSX(10.8.3)上。我已经修改了我的PATH,以便应用程序的bin文件夹位于所有其他文件夹之前。Rammy:~phrogz$whichpg_config/Applications/Postgres.app/Contents/MacOS/bin/pg_config我已经安装了rvm并且可以毫无错误地安装pggem,但是当我需要它时我得到一个错误:Rammy:~phrogz$gem-v1.8.25Rammy:~phrogz$geminstallpgFetching:pg-0.15.1.gem(100%)Buildingnativeextension
前言一般来说,前端根据后台返回code码展示对应内容只需要在前台判断code值展示对应的内容即可,但要是匹配的code码比较多或者多个页面用到时,为了便于后期维护,后台就会使用字典表让前端匹配,下面我将在微信小程序中通过wxs的方法实现这个操作。为什么要使用wxs?{{method(a,b)}}可以看到,上述代码是一个调用方法传值的操作,在vue中很常见,多用于数据之间的转换,但由于微信小程序诸多限制的原因,你并不能优雅的这样操作,可能有人会说,为什么不用if判断实现呢?但是if判断的局限性在于如果存在数据量过大时,大量重复性操作和if判断会让你的代码显得异常冗余。wxswxs相当于是一个独立
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
我需要从站点抓取数据,但它需要我先登录。我一直在使用hpricot成功地抓取其他网站,但我是使用mechanize的新手,我真的对如何使用它感到困惑。我看到这个例子经常被引用:require'rubygems'require'mechanize'a=Mechanize.newa.get('http://rubyforge.org/')do|page|#Clicktheloginlinklogin_page=a.click(page.link_with(:text=>/LogIn/))#Submittheloginformmy_page=login_page.form_with(:act
Doorkeeper中Token和Grant的区别我搞不清楚。Doorkeeper在哪个时刻创建访问授权,何时创建访问token?文档似乎对此什么也没说,现在我正在阅读代码,但不是十几行。 最佳答案 我还建议阅读documentationofoauth2据我了解,Doorkeeper也是基于该文档中描述的协议(protocol)。在doorkeeper中,你会先获得accessgrant,然后是accesstoken。访问授权通常只存在很短的时间(doorkeeper中的默认值为10分钟)。您将通过向api-url/oauth/au
我的测试尝试访问网页并验证页面上是否存在某些元素。例如,它访问http://foo.com/homepage.html并检查Logo图像,然后访问http://bar.com/store/blah.html并检查页面上是否出现了某些文本。我的目标是访问经过Kerberos身份验证的网页。我发现Kerberos代码如下:主文件uri=URI.parse(Capybara.app_host)kerberos=Kerberos.new(uri.host)@kerberos_token=kerberos.encoded_tokenkerberos.rb文件classKerberosdefini