前短时间,为了验证公司的验证码功能存在安全漏洞,写了一个爬虫程序抓取官网图库,然后通过二值分析,破解验证码进入系统刷单。 其中,整个环节里关键的第一步就是拿到数据 -- Python 爬虫技。
今天,我打算把爬虫经验分享一下,因为不能泄露公司核心信息,所以我随便找了一个第三方网站——《懂车帝》做演示。为了展示Selenium效果,网站需满足:需要动态加载(下拉)才能获取完整(或更多)数据的网页,如:淘宝,京东,拼多多的商品也都可以。
通过本篇,你将学会通过Selenium自动化加载HTML的技巧,并利用 BeautifulSoup 解析静态的HTML页面,还有使用 xlwt 插件操作 Excel。
本文仅教学使用,无任何攻击行为或意向。
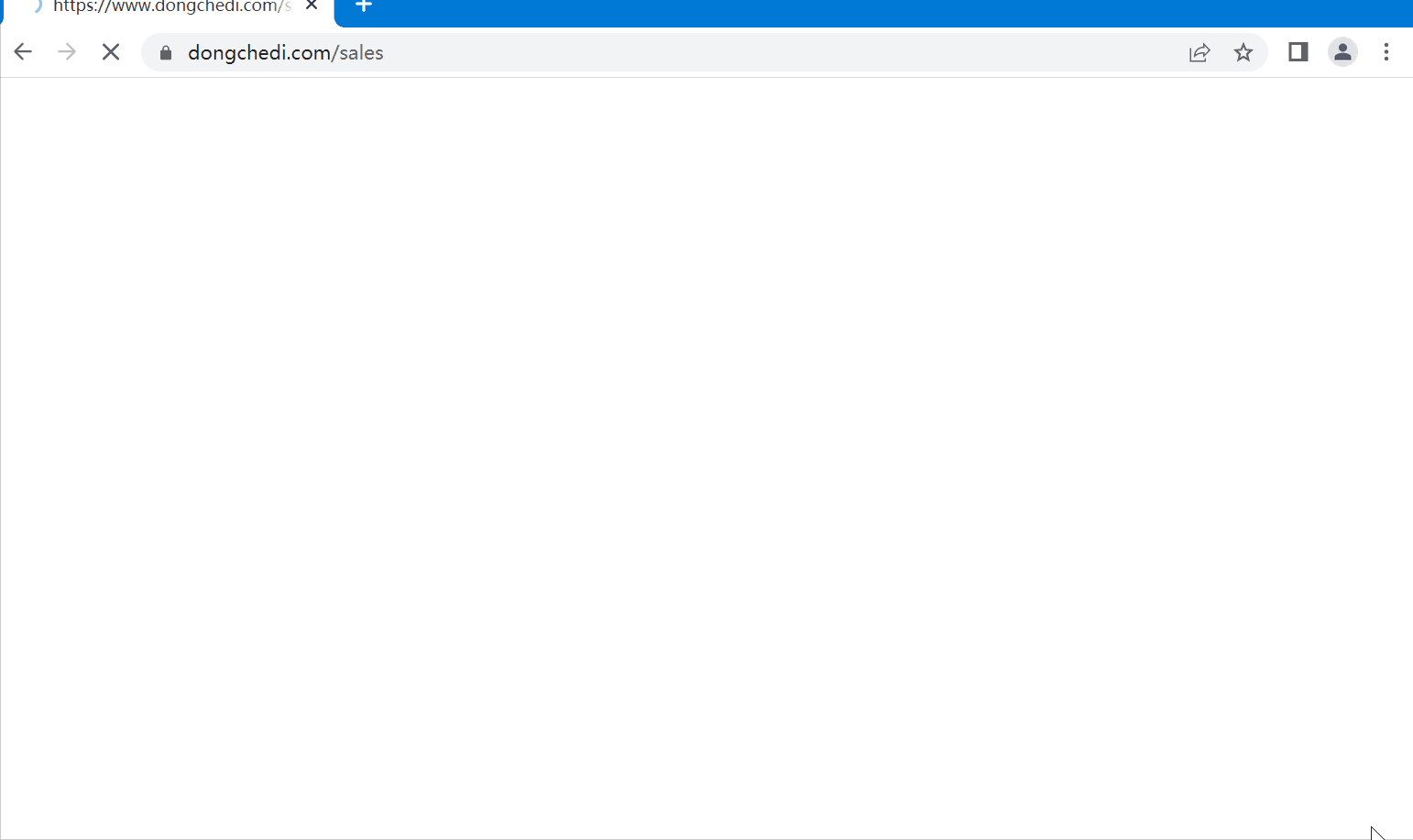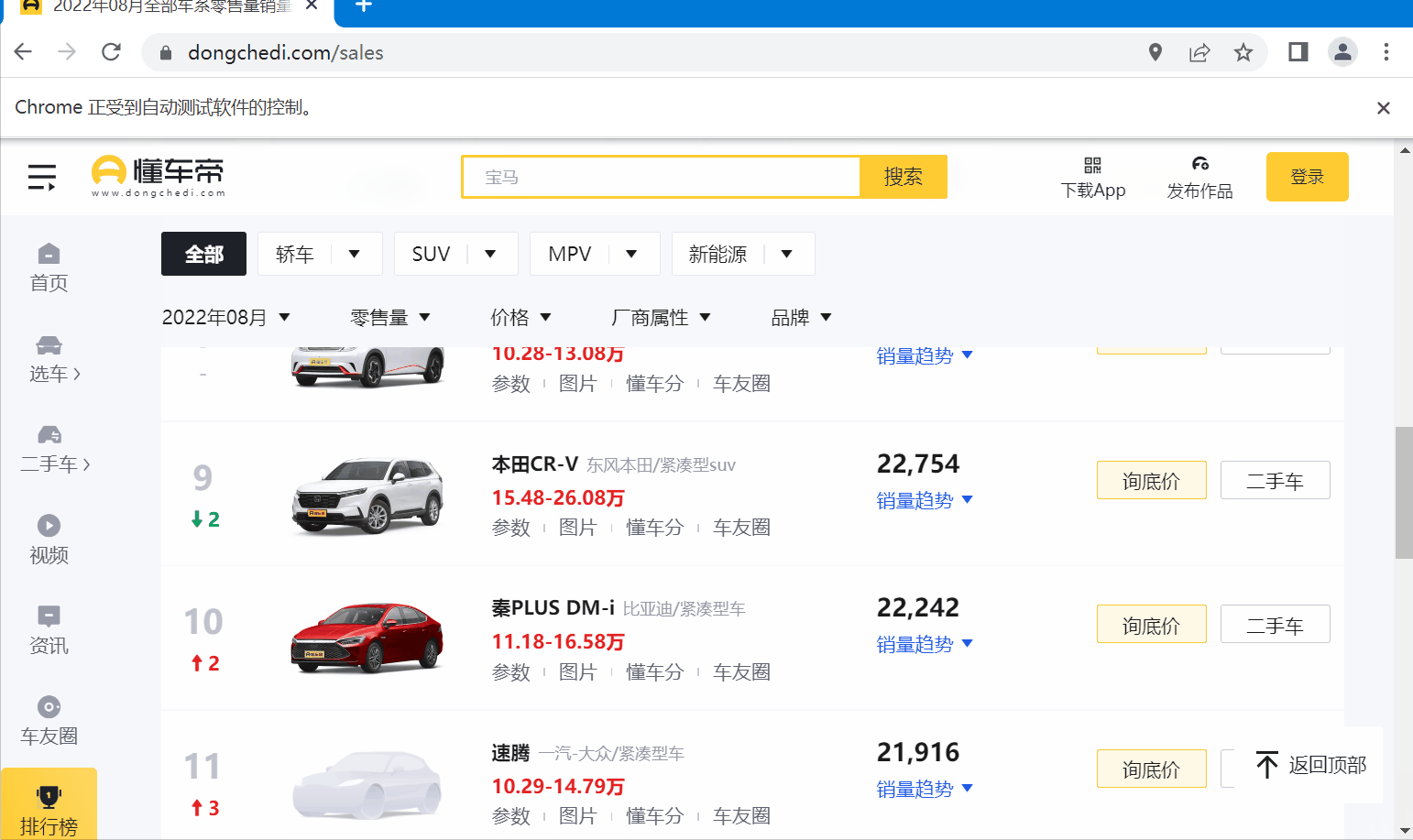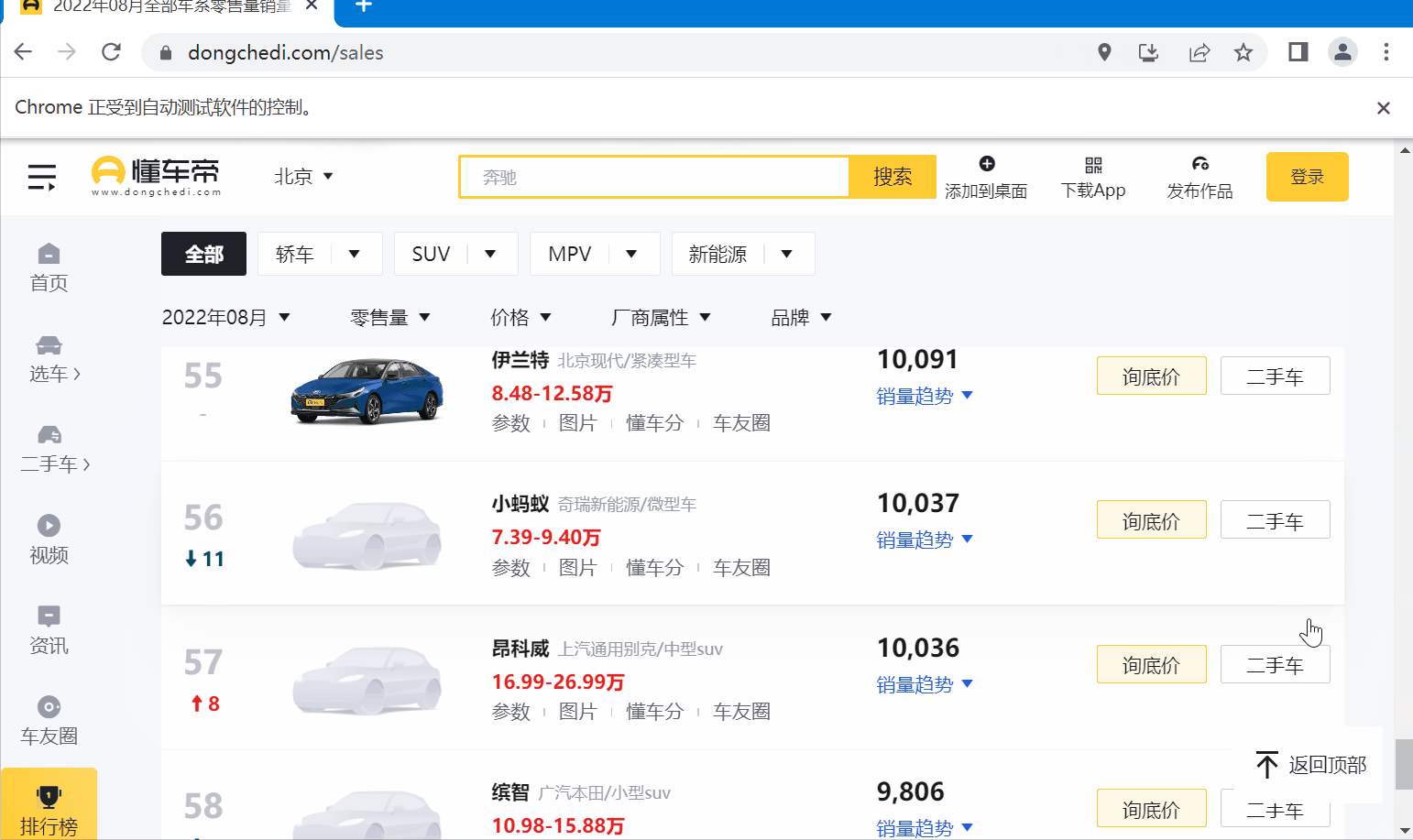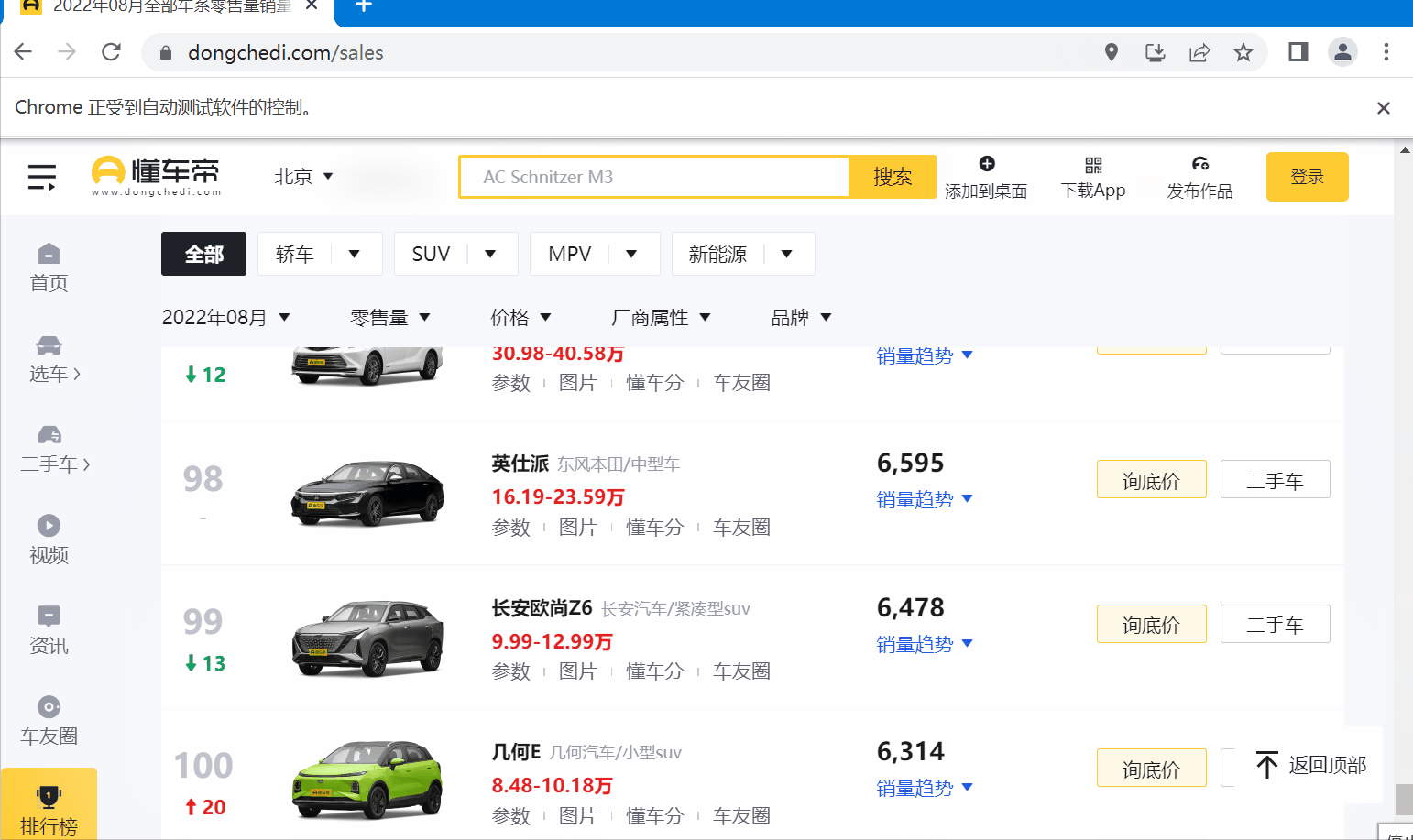
首先,打开“某瓣电影一周新片榜”的页面:https://www.dongchedi.com/sales,截图省略了下面列表部分。
然后,提取榜单里的关键信息,如:当前月份,汽车排名,图片链接,汽车名称,汽车品牌,评论数等,这是我们需要爬取的数据,接下来就需要弄清楚他们在 Html 中的位置。

Chrome浏览器 - 【F12】检查下 Html 页面结构,找到排行榜数据的具体位置,这对我们后续利用 Selenium 和 BeautifulSoup 解析至关重要。
下面图片里可以看到,月份信息在 “<div class="more_more__z2kQC"></div>” 标签里(篇幅原因,没有展示全),而当月的榜单信息在"<li class="list_item__3gOKl">"的标签里,10条 “<tr></tr> ”标签形成一个List集合。
注意:当前页面第一次进来页面只会加载出10条记录,如果想要获取全量的排行榜数据,我们需要用到 Selenium 技术动态加载页面,直到数据全部加载出来为止。

以我当前的时间为例——“2022年8月”,一共有“TOP542”条数据。

import time # time函数
import xlwt # 进行excel操作
import os.path # os读写
from bs4 import BeautifulSoup # 解析html的
from selenium import webdriver # selenium 驱动
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 模仿键盘
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件因为当前页面没有明显的元素用来判断拉到什么位置就是底部,所以我的规则是:一直循环,直到连续5次 Keys.PAGE_DOWN(下拉),<li> 标签数量不再增加,就认为已经到底了。为了避免程序计算太快,每次下拉还停顿了0.2秒,实际效果不错。
while (flag):
_input.send_keys(Keys.PAGE_DOWN)
driver.implicitly_wait(2)
elem = driver.find_elements(By.CLASS_NAME, "list_item__3gOKl")
len_cur = len(elem)
print(len_now, len_cur)
if (len_now != len_cur):
len_now = len_cur
num = 0
elif (len_now == len_cur and num <= 5):
num = num + 1
time.sleep(0.5)
else:
time.sleep(2)
break根据小编的开发经验,selenium 很擅长模拟和测试,它动态加载的特性是 BeautifulSoup不 具备的。但是,对于取值操作,简单的还好,复杂点的比如:循环<li>标签这种操作,我还是觉得BeautifulSoup更方便。
在爬虫的世界里,大量有价值的数据都是循环展现的,比如:某排行榜,某商品列表等...所以,Selenium + BeautifulSoup的操作必不可少。
核心代码也非常简单,直接传入 Selenium 驱动 driver,用 page_source() 就可以啦。
# 获取完整渲染的网页源代码
pageSource = driver.page_source
soup = BeautifulSoup(pageSource, 'html.parser')
soup.prettify() # 创建workbook对象
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
# 创建工作表
sheet = book.add_sheet('懂车帝想月销量排行榜', cell_overwrite_ok=True)
col = ("排名", "图片链接", "名称", "品牌", "指导价", "销量")
book.save("销量排行榜.xls") 细节有待提高,下面的代码大家装好插件,直接拖到本地运行就可以了。
如果遇到环境问题,未知异常等,请参照博文:关于:Python基础,爬虫,常见异常和面试【篇】(专题汇总)
# -*- codeing = utf-8 -*-
import time # time函数
import xlwt # 进行excel操作
import os.path # os读写
from bs4 import BeautifulSoup # 解析html的
from selenium import webdriver # selenium 驱动
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 模仿键盘
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
# 获取全量数据的 selenium 驱动
def readHtml(baseurl, flag):
print("—————————— Read Html ——————————")
# 打开浏览器
driver = webdriver.Chrome()
driver.get(baseurl)
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "tw-mt-12")))
# 动态加载排行榜数据
# 我的规则:一直循环,直到连续5次下拉,<li>标签数量不再增加,则认为已经到底了
num, len_now = 0, 0
_input = driver.find_element(By.CLASS_NAME, "body")
while (flag):
_input.send_keys(Keys.PAGE_DOWN)
driver.implicitly_wait(2)
elem = driver.find_elements(By.CLASS_NAME, "list_item__3gOKl")
len_cur = len(elem)
print(len_now, len_cur)
if (len_now != len_cur):
len_now = len_cur
num = 0
elif (len_now == len_cur and num <= 5):
num = num + 1
time.sleep(0.5)
else:
time.sleep(2)
break
return driver
# 将 selenium 驱动转 bs 形式的 html 页面
def getHtml(driver):
print("—————————— Get Html ——————————")
# 获取完整渲染的网页源代码
pageSource = driver.page_source
soup = BeautifulSoup(pageSource, 'html.parser')
soup.prettify()
return soup
# 从 html 页面爬取数据
def getData(soup):
print("—————————— Get Data ——————————")
# 1. 时间
dataTime = soup.find('div', class_="more_more__z2kQC").span.text
# 2. 数据,查找符合要求的字符串
index = 0 # 排行
datalist = [] # 用来存储爬取的网页信息
try:
for item in soup.find_all('li', class_="list_item__3gOKl"):
data = [] # 保存一条数据用
print(item)
# 2.1 生成一条记录
index = index + 1
data.append(index)
data.append(item.find('div', class_='tw-p-12').div.div.img["src"])
dd = item.find('div', class_='tw-py-16 tw-pr-12')
data.append(dd.div.a.text)
data.append(dd.div.span.text)
data.append(dd.p.text)
data.append(item.find('div', class_='tw-py-16 tw-text-center').div.p.text)
# 2.2 存入list
datalist.append(data)
except Exception as e:
print(e)
pass
return dataTime, datalist
# 保存数据到表格
def saveData(datalist, savepath):
print("—————————— save ——————————")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workbook对象
sheet = book.add_sheet(dataTime, cell_overwrite_ok=True) # 创建工作表。sheet页名为dataTime
col = ("排名", "图片链接", "名称", "品牌", "指导价", "销量")
for i in range(0, len(col)):
sheet.write(0, i, col[i]) # 列名
for i in range(0, len(datalist)):
# print("第%d条" %(i+1)) # 输出语句,用来测试
data = datalist[i]
for j in range(0, len(col)):
sheet.write(i+1, j, data[j]) # 数据
if os.path.exists(savepath): # 清空路径
os.remove(savepath)
book.save(savepath) # 保存
pass
if __name__ == "__main__":
print("—————————— 开始执行 ——————————")
# 1. 读取url
html = readHtml("https://www.dongchedi.com/sales", True)
# 2. selenium转BeautifulSoup
soup = getHtml(html)
# 3. 处理Html数据
dataTime, dataList = getData(soup)
# 4. 保存数据
saveData(dataList, dataTime + "汽车销量排行总榜.xls")
print("—————————— 爬取完毕 ——————————")
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru