最近一个多月跟着师哥和同学们一起做了一个酒旅项目,这个项目是依托微信小程序提供线上预定酒店和旅游的互联网产品。希望解决的用户的痛点如下:
以下是项目架构图:
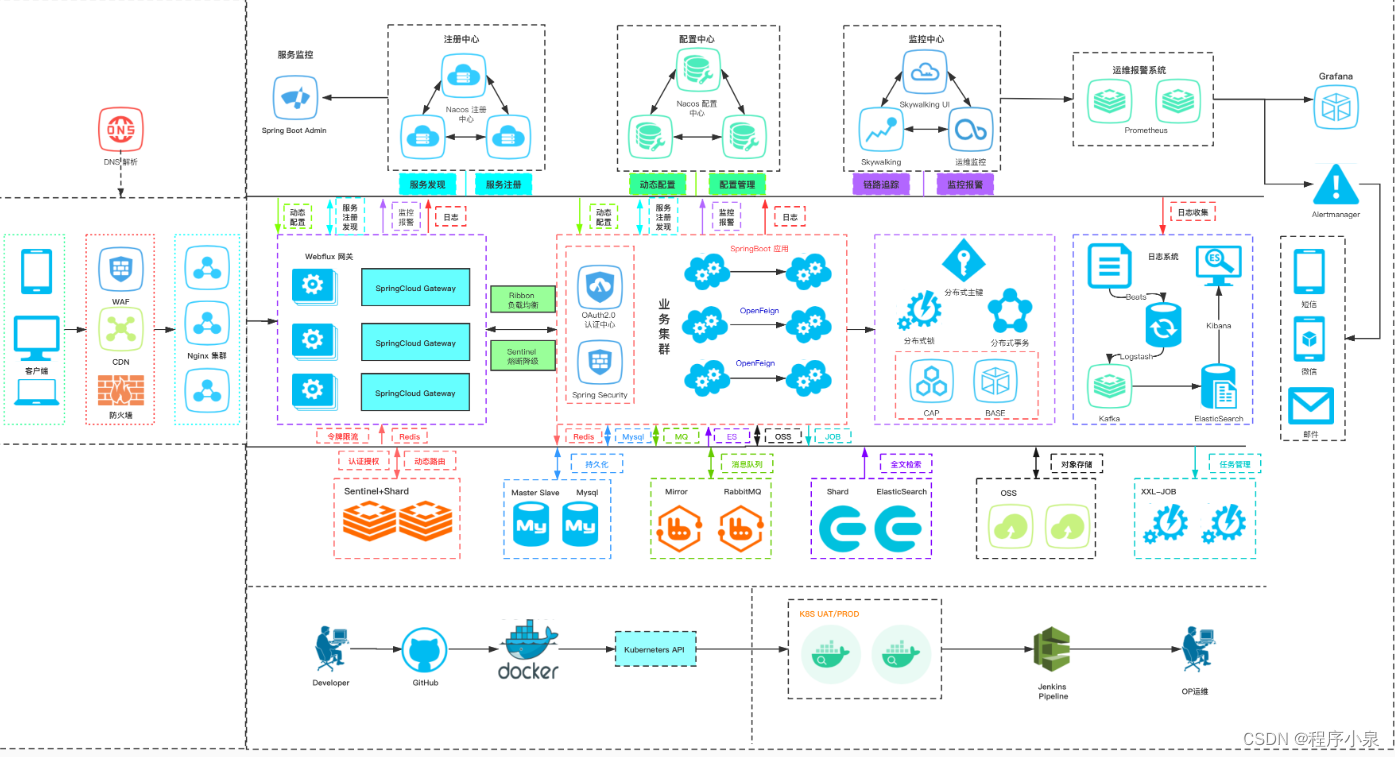
在任务分工中,我被分配到了编写基于 Elasticsearch 实现酒店列表的搜索功能。期望根据不同的查询条件实现酒店列表的快速搜索展示,由于之前没有使用过 Elasticsearch 整合 Spring Boot ,因此需要通过边学习,边尝试的方式去完成这个功能。以下介绍本次项目所学习到的 Elasticsearch 知识和我本人编写的复杂查询功能。
ElasticSearch是一款非常强大的、基于Lucene的开源搜索及分析引擎;它是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。
主要功能:
1)海量数据的分布式存储以及集群管理,达到了服务与数据的高可用以及水平扩展;
2)近实时搜索,性能卓越。对结构化、全文、地理位置等类型数据的处理;
3)海量数据的近实时分析(聚合功能)
应用场景:
1)网站搜索、垂直搜索、代码搜索;
2)日志管理与分析、安全指标监控、应用性能监控、Web抓取舆情分析;
在本次项目中主要使用 Elasticsearch 整合 Spring Boot 的方式,通过 ElasticsearchTemplate 完成多条件复合查询。
在本次项目中主要使用了 布尔查询、分页查询、过滤查询、地理位置查询等。
bool查询包含四种操作符,分别是must,should,must_not,filter。他们均是一种数组,数组里面是对应的判断条件。
must: 必须匹配。贡献算分must_not:过滤子句,必须不能匹配,但不贡献算分should: 选择性匹配,至少满足一条。贡献算分filter: 过滤子句,必须匹配,但不贡献算分我们可以通过组合过滤器 filter 使用多条件等值查询。
query 和 filter 的区别:query 查询的时候,会先比较查询条件,然后计算分值,最后返回文档结果;而 filter 是先判断是否满足查询条件,如果不满足会缓存查询结果(记录该文档不满足结果),满足的话,就直接缓存结果,filter 不会对结果进行评分,能够提高查询效率。
例1 整合过滤查询、分页查询、布尔查询
查询书籍中 name 词项匹配计算机,价格大于等于 40 并且小于等于 100 的书籍,按价格升序,分页条件为第一页前 10 个。
DSL 查询语句:
GET books/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": {
"value":"计算机"
}
}
}
],
"filter": [
{
"range": {
"price": {
"gte": 40,
"lte": 100
}
}
}
]
}
},
"sort": [
{
"price": {
"order": "asc"
}
}
],
"size": 10,
"from": 0
}
Java 代码:
@Test
void contextLoads() {
// 复杂查询编写
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
// 1. bool 查询 (过滤型查询 builder)
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
// 1.2 范围查询 builder
RangeQueryBuilder range = new RangeQueryBuilder("price");
range.gte(40).lte(100);
TermQueryBuilder term = new TermQueryBuilder("name","计算机");
boolQueryBuilder.must(term);
boolQueryBuilder.filter(range);
// 2. 分页查询
PageRequest pageRequest = PageRequest.of(0, 10);
// 3. 按价格升序排序
FieldSortBuilder priceSortBuilder = SortBuilders.fieldSort("price");
priceSortBuilder.order(SortOrder.ASC);
// 整合复杂搜索
NativeSearchQuery searchQuery = nativeSearchQueryBuilder.withFilter(boolQueryBuilder).withPageable(pageRequest).withSort(priceSortBuilder).build();
//搜索获取结果集
SearchHits<Books> booksSearchHits = restTemplate.search(searchQuery, Books.class);
ArrayList<Books> bookList = new ArrayList<>();
for (SearchHit<Books> booksSearchHit : booksSearchHits) {
Books book = booksSearchHit.getContent();
bookList.add(book);
}
for (Books books : bookList) {
System.out.println(books.getAuthor() + "==>" + books.getName() + "==>" + books.getPrice());
}
}
使用 geo_distance query 实现给出一个中心点,查询距离该中心点指定范围内的文档的功能。
DSL 例子如下:
GET geo/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_distance": {
"distance": "600km",
"location": {
"lat": 34.288991865037524,
"lon": 108.9404296875
}
}
}
]
}
}
}
Java 代码:
@Data
@EqualsAndHashCode(callSuper = false)
@Document(indexName = "geo",shards = 1,replicas = 1)
public class Geo {
private static final long serialVersionUID = -2L;
@Id
private Long id;
@Field(type = FieldType.Keyword, analyzer = "ik_max_word")
private String name;
@GeoPointField
private GeoPoint location;
}
public SearchHits<Geo> getDistanceQuery(@RequestParam double lat, @RequestParam double lon, @RequestParam int distance){
PageRequest page = PageRequest.of(0, 5);
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
GeoDistanceQueryBuilder geoDistanceQueryBuilder = new GeoDistanceQueryBuilder("location");
boolean validLatitude = GeoUtils.isValidLatitude(lat);
boolean validLongitude = GeoUtils.isValidLongitude(lon);
geoDistanceQueryBuilder.distance(distance, DistanceUnit.KILOMETERS).point(new GeoPoint(lat, lon));
NativeSearchQuery searchQuery = nativeSearchQueryBuilder.withPageable(page).withQuery(new MatchAllQueryBuilder()).withFilter(geoDistanceQueryBuilder).build();
SearchHits<Geo> geoSearchHits = elasticsearchRestTemplate.search(searchQuery, Geo.class);
for (SearchHit<Geo> geoSearchHit : geoSearchHits) {
System.out.println(geoSearchHit.getContent());
}
return geoSearchHits;
}
@Test
public void matchQuery(){
ArrayList<FunctionScoreQueryBuilder.FilterFunctionBuilder> filterFunctionBuilders = new ArrayList<>();
filterFunctionBuilders.add(new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchQuery("name","计算机"),
ScoreFunctionBuilders.weightFactorFunction(5)));
filterFunctionBuilders.add(new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchQuery("info","计算机"),
ScoreFunctionBuilders.weightFactorFunction(1)));
FunctionScoreQueryBuilder.FilterFunctionBuilder[] builders = new FunctionScoreQueryBuilder.FilterFunctionBuilder[filterFunctionBuilders.size()];
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(builders).scoreMode(FunctionScoreQuery.ScoreMode.SUM).setMinScore(1);
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
builder.withQuery(functionScoreQueryBuilder);
}
根据对 ES 功能和查询 API 的学习,再根据项目需求编写代码如下:
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
// 分页
PageRequest page = PageRequest.of(vo.getPageIndex(), vo.getPageSize());
nativeSearchQueryBuilder.withPageable(page);
// 通过改变权重影响关键字查询:名称 > 品牌 > 地址 搜索
FunctionScoreQueryBuilder functionScoreQuery = getFunctionScoreQuery(vo);
if(ObjectUtil.isNotNull(functionScoreQuery)){
nativeSearchQueryBuilder.withQuery(functionScoreQuery);
}else{
nativeSearchQueryBuilder.withQuery(new MatchAllQueryBuilder());
}
// bool查询过滤 主要通过城市名,附近地标,星级,价格范围进行过滤
BoolQueryBuilder boolQuery = getBoolQuery(vo);
nativeSearchQueryBuilder.withFilter(boolQuery);
// 排序
Integer sort = vo.getSort();
SortBuilder sortQuery = getSortQuery(sort, vo);
nativeSearchQueryBuilder.withSort(sortQuery);
// 构造总查询
NativeSearchQuery searchQuery = nativeSearchQueryBuilder.build();
SearchHits<EsHotel> hotelSearchHits = elasticsearchRestTemplate.search(searchQuery, EsHotel.class);
// 封装统一分页返回类
return getCommonPageResult(hotelSearchHits,vo);
以上代码基本满足了项目需求,我也学习到了 ES 知识和相关 API 使用,更重要的是收获了整个项目流程开发的经验,为我以后更好地学习打下了坚实地基础。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear