摘要:MindStudio是一套基于华为昇腾AI处理器开发的AI全栈开发平台
本文分享自华为云社区《MindStudio模型训练场景精度比对全流程和结果分析》,作者:yd_247302088 。
MindStudio是一套基于华为昇腾AI处理器开发的AI全栈开发平台,包括基于芯片的算子开发、以及自定义算子开发,同时还包括网络层的网络移植、优化和分析,另外在业务引擎层提供了可视化的AI引擎拖拽式编程服务,极大的降低了AI引擎的开发门槛。MindStudio工具中的功能框架如图1所示:

图1 MindStudio功能框架
MindStudio工具中的主要几个功能特性如下:
自有实现的算子在昇腾AI处理器上的运算结果与业界标准算子(如Caffe、ONNX、TensorFlow、PyTorch)的运算结果可能存在差异:
为了帮助开发人员快速解决算子精度问题,需要提供比对自有实现的算子运算结果与业界标准算子运算结果之间差距的工具。精度比对工具提供Vector比对能力,包含余弦相似度、最大绝对误差、累积相对误差、欧氏相对距离、KL散度、标准差、平均绝对误差、均方根误差、最大相对误差、平均相对误差的算法比对维度。
在进行实验之前需要配置好远端Linux服务器并下载安装MindStudio。
首先在Linux服务器上安装部署好Ascend-cann-toolkit开发套件包、Ascend-cann-tfplugin框架插件包和TensorFlow 1.15.0深度学习框架。之后在Windows上安装MindStudio,安装完成后通过配置远程连接的方式建立MindStudio所在的Windows服务器与Ascend-cann-toolkit开发套件包所在的Linux服务器的连接,实现全流程开发功能。
接下来配置环境变量,以运行用户登录服务器,在任意目录下执行vi ~/.bashrc命令,打开.bashrc文件,在文件最后一行后面添加以下内容(以非root用户的默认安装路径为例)。

然后执行:wq!命令保存文件并退出。
最后执行source ~/.bashrc命令使其立即生效。
关于MindStudio的具体安装流程可以参考Windows安装MindStudio(点我跳转),MindStudio环境搭建指导视频(点我跳转)。MindStudio官方下载地址:点我跳转。
本文教程基于MindStudio5.0.RC2 x64,CANN版本5.1.RC2实现。
本样例选择resnet50模型,利用git克隆代码(git clone -b r1.13.0 https://github.com/tensorflow/models.git),下载成功后如下图所示:

数据比对前,需要先检查并去除训练脚本内部使用到的随机处理,避免由于输入数据不一致导致数据比对结果不可用。
编辑resnet_run_loop.py文件,修改如下(以下行数仅为示例,请以实际为准):
注释掉第83、85行
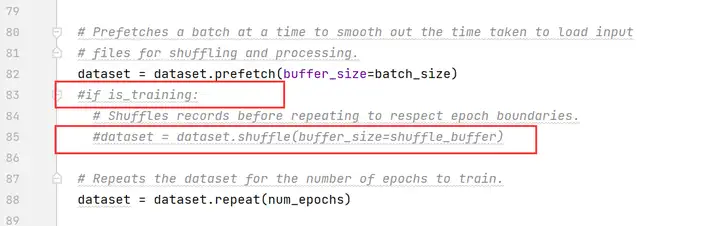
注释掉第587~594行

第607行,修改为“return None”
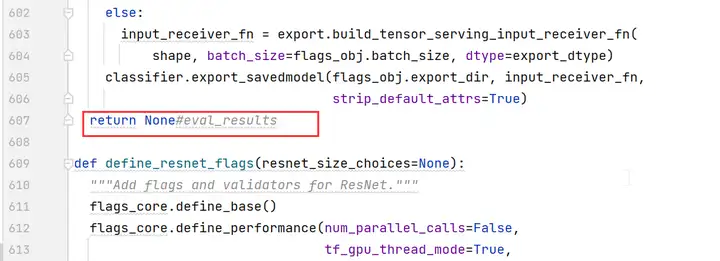
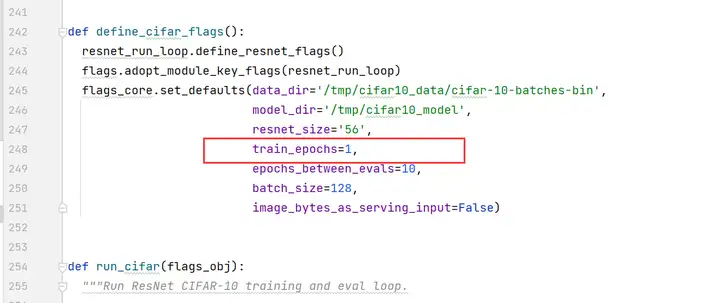
编辑cifar10_main.py文件,将train_epochs的值改为1。
进入训练脚本所在目录(如“~/models/official/resnet”),修改训练脚本,添加tfdbg的hook。编辑resnet_run_loop.py文件,添加如下加粗字体的信息。
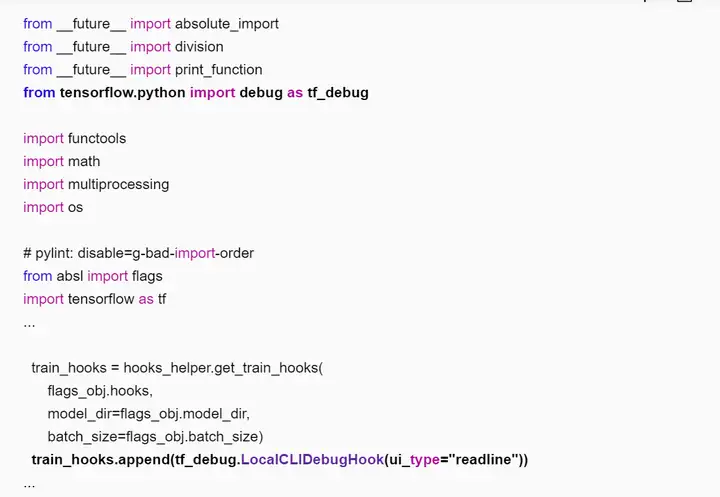
配置环境变量

执行训练脚本

训练任务停止后,在命令行输入run,训练会往下执行一个step。
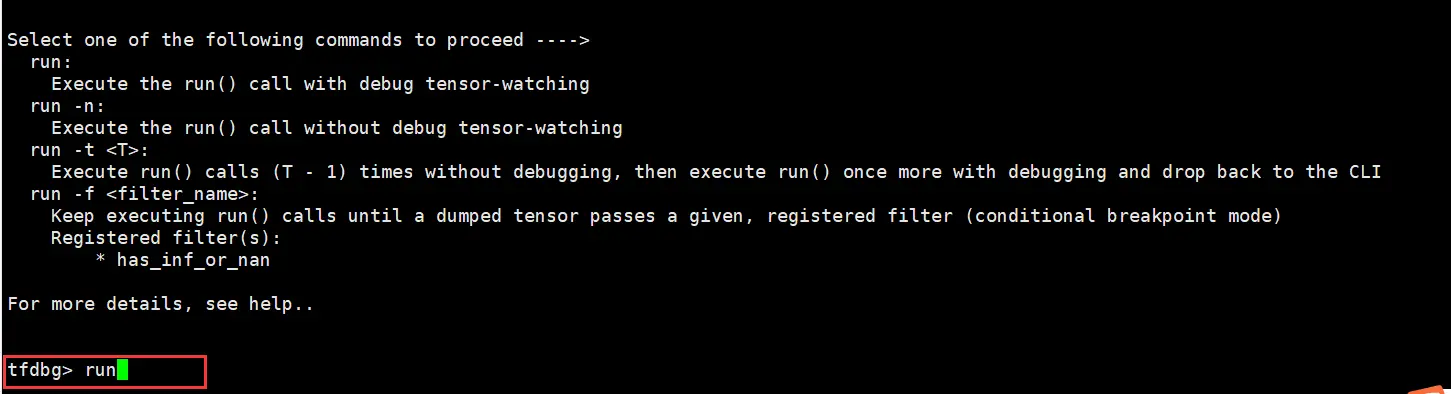
执行lt>gpu_dump命令将所有tensor的名称暂存到自定义名称的gpu_dump文件里。命令行中会有如下回显。

另外开启一个终端,在linux命令行下进入gpu_dump文件所在目录,执行下述命令,用以生成在tfdbg命令行执行的命令。
timestamp=$[$(date +%s%N)/1000] ; cat gpu_dump | awk '{print "pt",$4,$4}' | awk '{gsub("/", "_", $3);gsub(":", ".", $3);print($1,$2,"-n 0 -w "$3".""'$timestamp'"".npy")}'>dump.txt
将上一步生成的dump.txt文件中所有tensor存储的命令复制(所有以“pt”开头的命令),然后回到tfdbg命令行(刚才执行训练脚本的控制台)粘贴执行,即可存储所有的npy文件,存储路径为训练脚本所在目录。

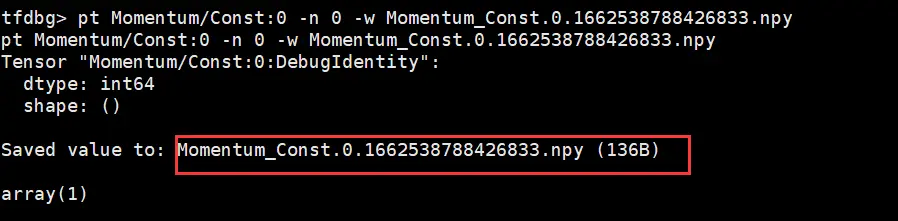
退出tfdbg命令行,将生成的npy文件保存到tf_resnet50_gpu_dump_data(用户可自定义)目录下。

单击菜单栏“File > New > Project...”弹出“New Project”窗口。
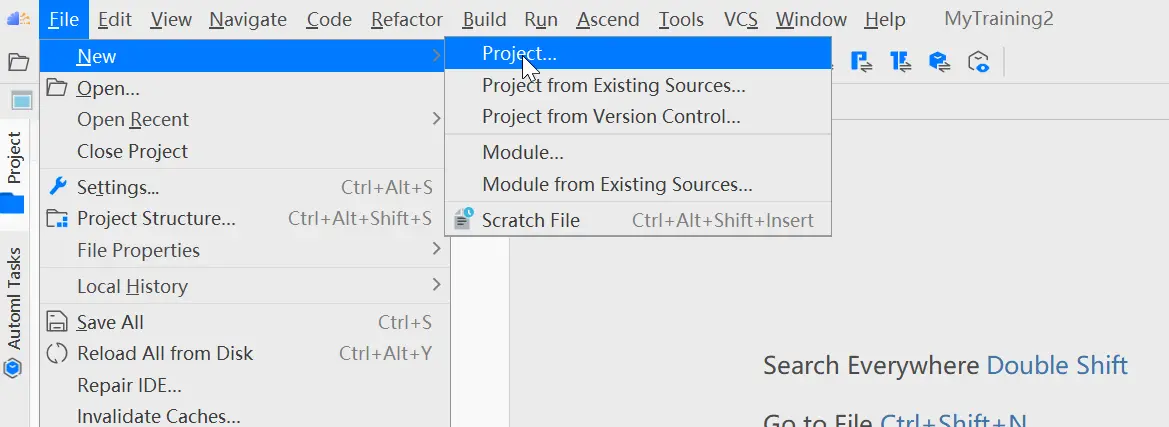
在New Project窗口中,选择Ascend Training。输入项目的名称、CANN远程地址以及本地地址。点击Change配置CANN,如下图所示:
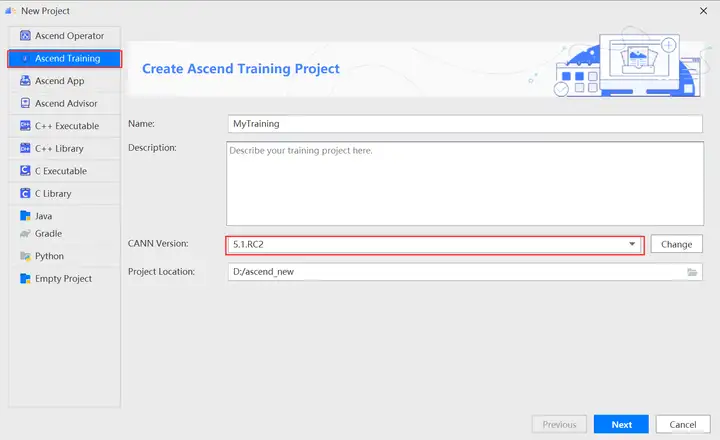
点击右侧 + 进行配置远程服务器,如下图所示:

在出现的信息配置框输入相关配置信息,如下图所示:
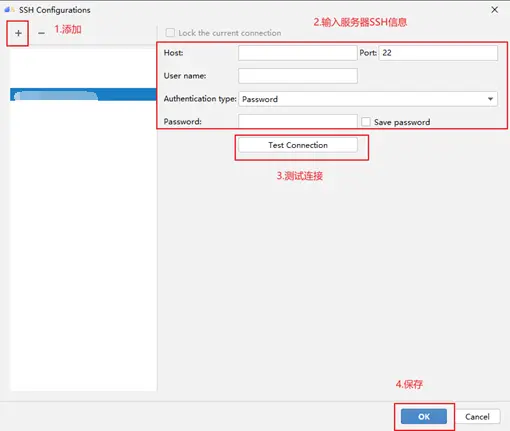
输入服务器的SSH信息,如果测试连接失败,建议使用CMD或XShell等工具进行排查。
选择远程 CANN 安装位置,如下图所示:
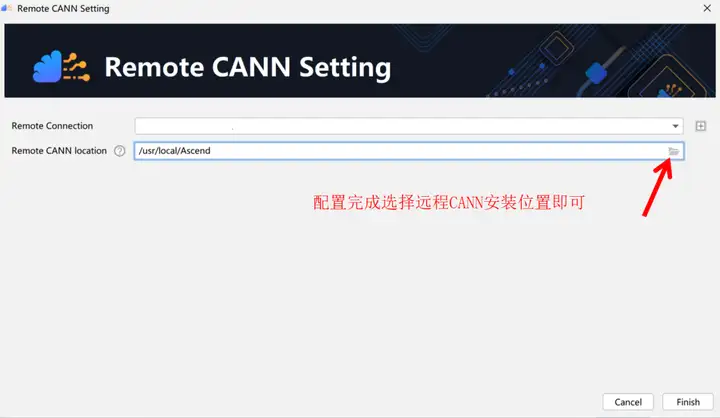
在Remote CANN location中选择CANN的路径,需要注意的是必须选择到CANN的版本号目录,这里选择的是5.1.RC2版本,如下图所示:
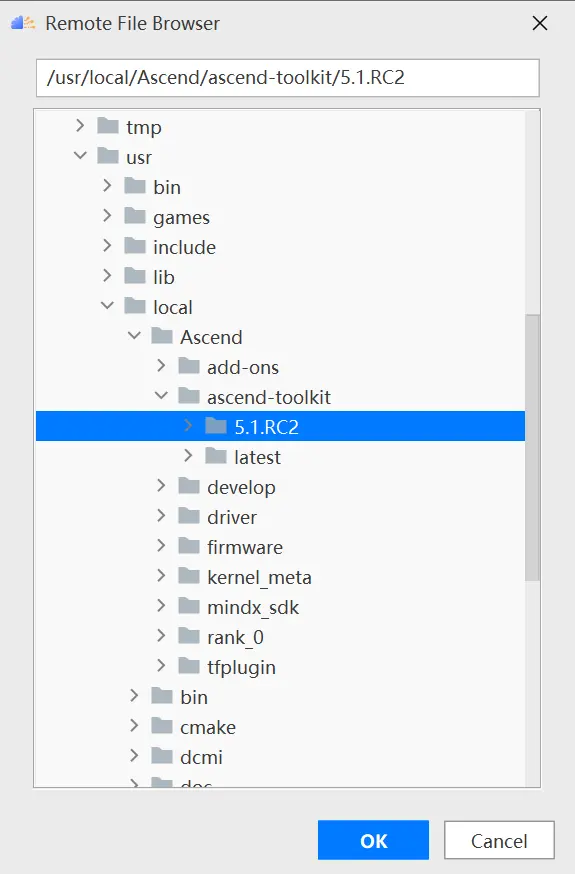
点击确定后,需要等待MindStudio进行文件同步操作,这个过程会持续数分钟,期间如果遇到Sync remote CANN files error.错误,考虑是否无服务器root权限。

配置完成CANN点击下一步
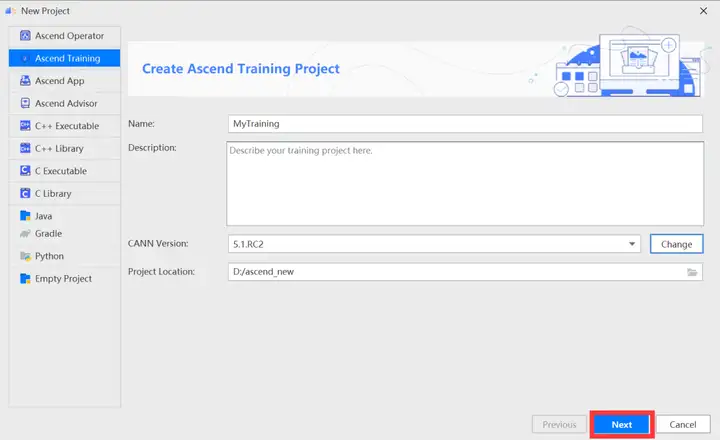
在训练工程选择界面,选择“TensorFlow Project”,单击“Finish”。
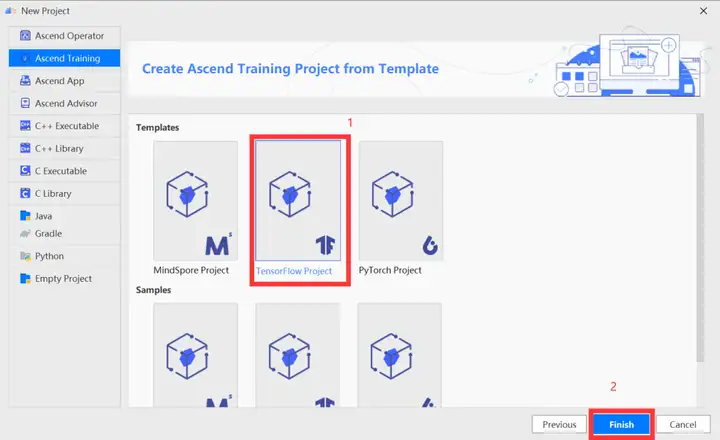
进入工程界面,单击工具栏中

按钮( TensorFlow GPU2Ascend工具)。
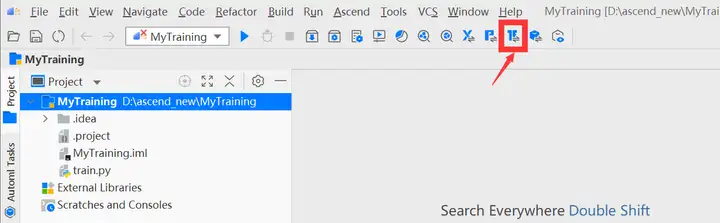
进入“TensorFlow GPU2Ascend”参数配置页,配置command file
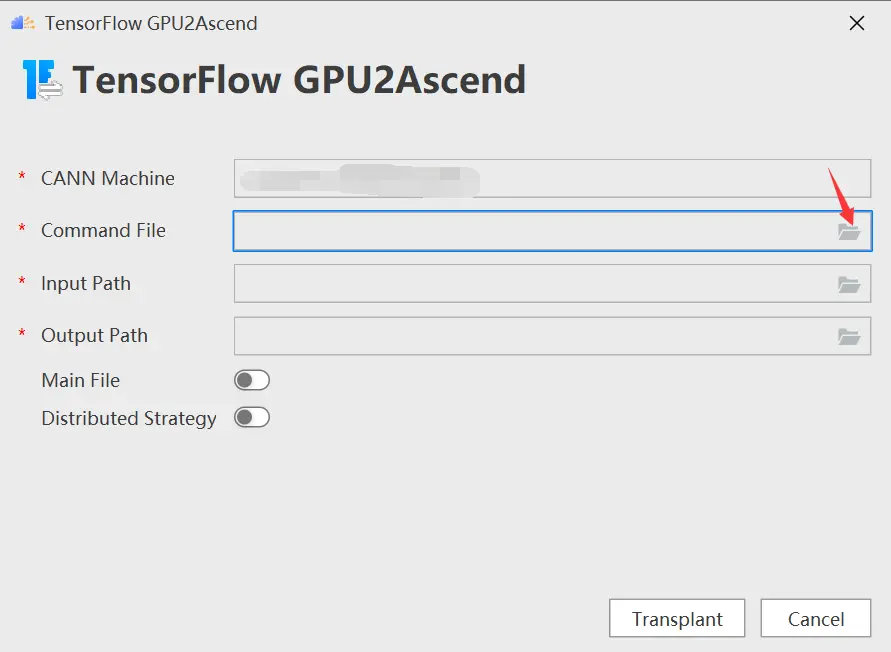
根据tfplugin文件所在路径选择/Ascend/tfplugin/5.1.RC2/python/site-packages/npu_bridge/convert_tf2npu/main.py,如下图所示
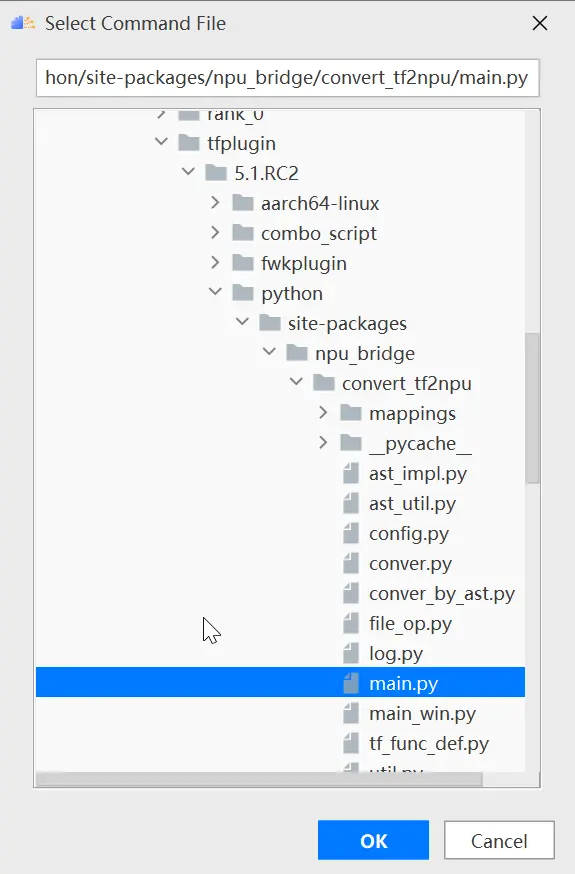
同样的,选择下载的代码路径作为input path,并选择输出路径,如下图所示:
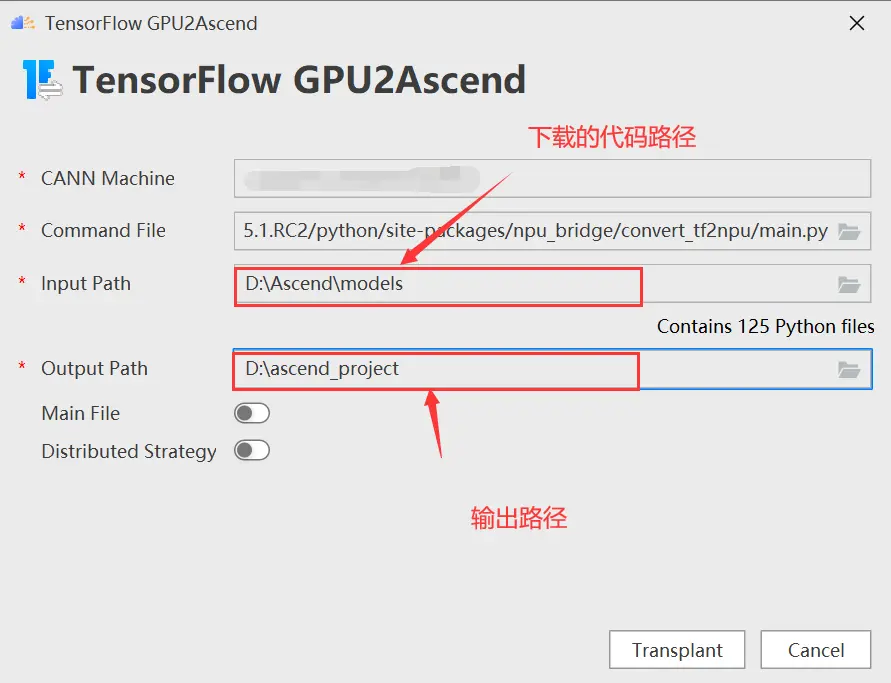
点击Transplant进行转换,如下图所示:
出现“Transplant success!”的回显信息,即转换成功。如下图所示:

步骤一 dump前准备。
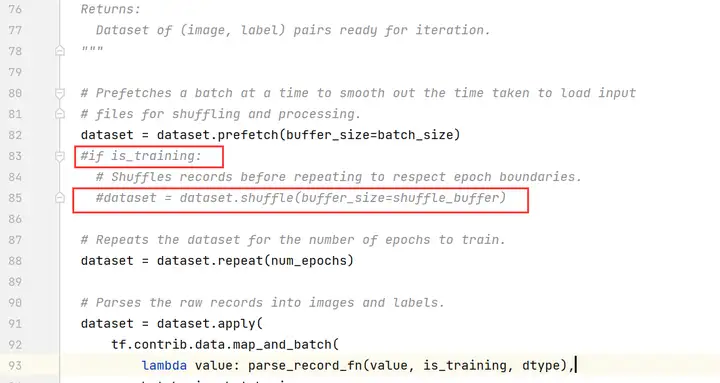
编辑resnet_run_loop.py文件,修改如下(以下行数仅为示例,请以实际为准):
注释掉第83、85行
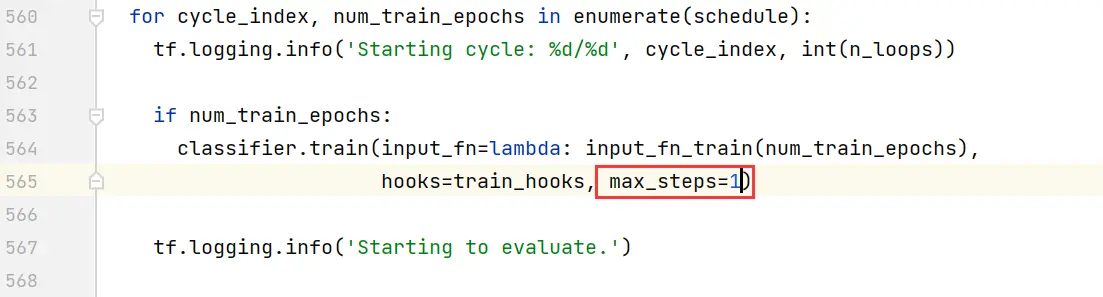
把max_steps设置为1。
注释掉第575~582行
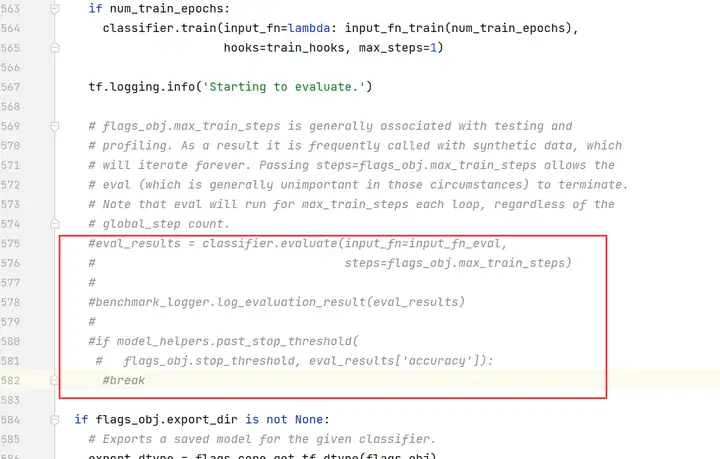
注释掉第595行,修改为“return None”。
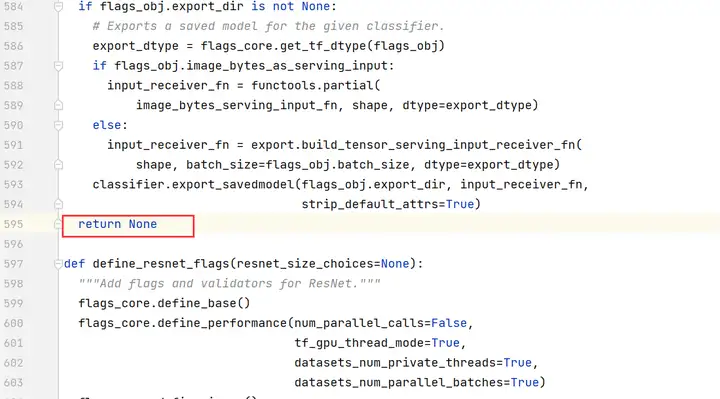
编辑cifar10_main.py文件,将train_epochs的值改为1。
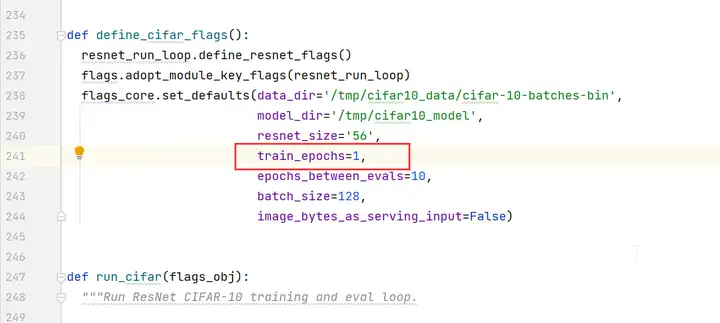
步骤二 dump参数配置。
为了让训练脚本能够dump出计算图,我们在训练脚本中的包引用区域引入os,并在构建模型前设置DUMP_GE_GRAPH参数。配置完成后,在训练过程中,计算图文件会保存在训练脚本所在目录中。
编辑cifar10_main.py,添加如下方框中的信息。

修改训练脚本(resnet_run_loop.py),开启dump功能。在相应代码中,增加如下方框中的信息。
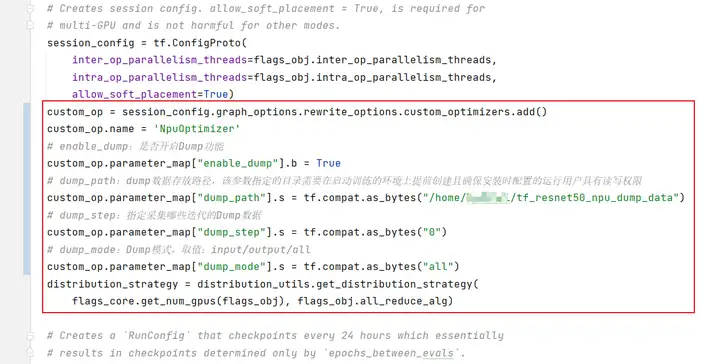
步骤三 环境配置。
单击MindStudio菜单栏“Run > Edit Configurations...”。
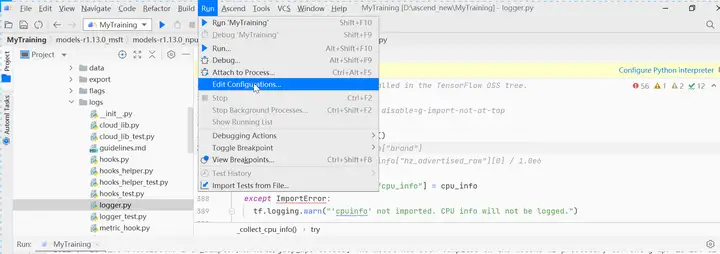
进入运行配置界面,选择迁移后的训练脚本。
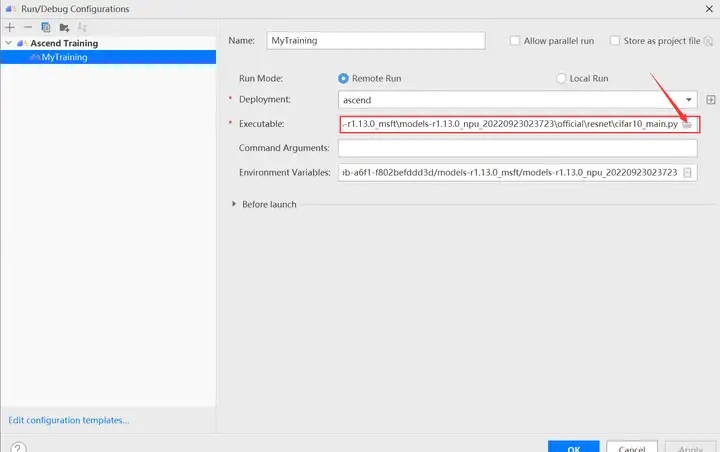
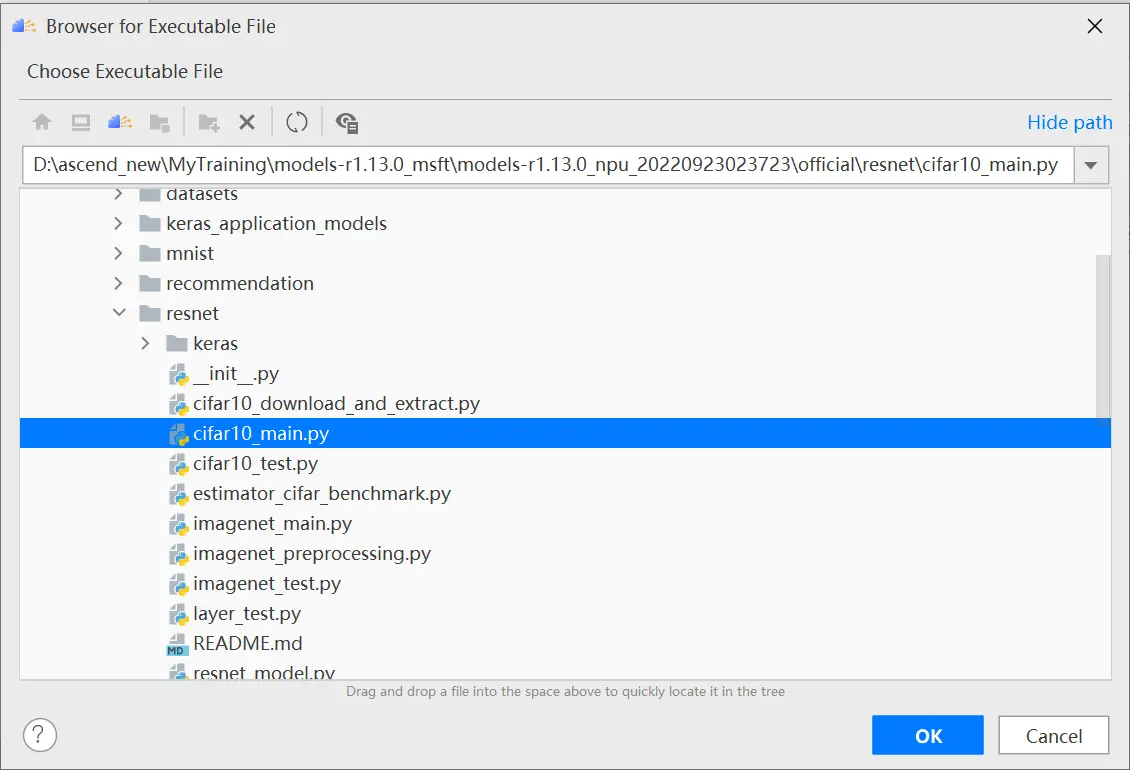
配置环境变量,打开下图所示界面,配置训练进程启动依赖的环境变量,参数设置完成后,单击“OK”,环境变量配置说明请参见下表。
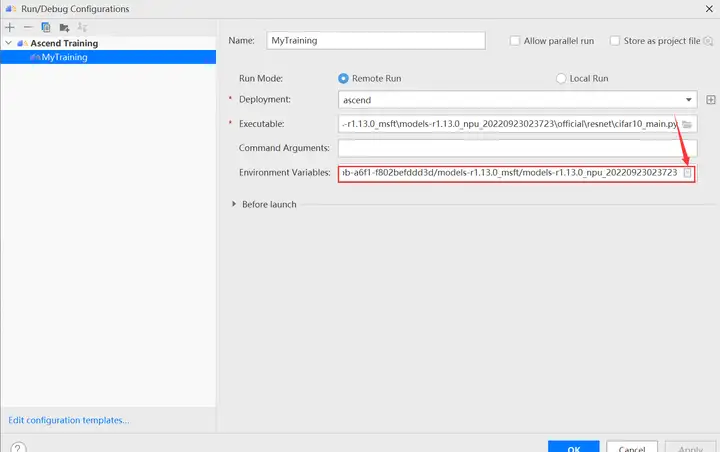
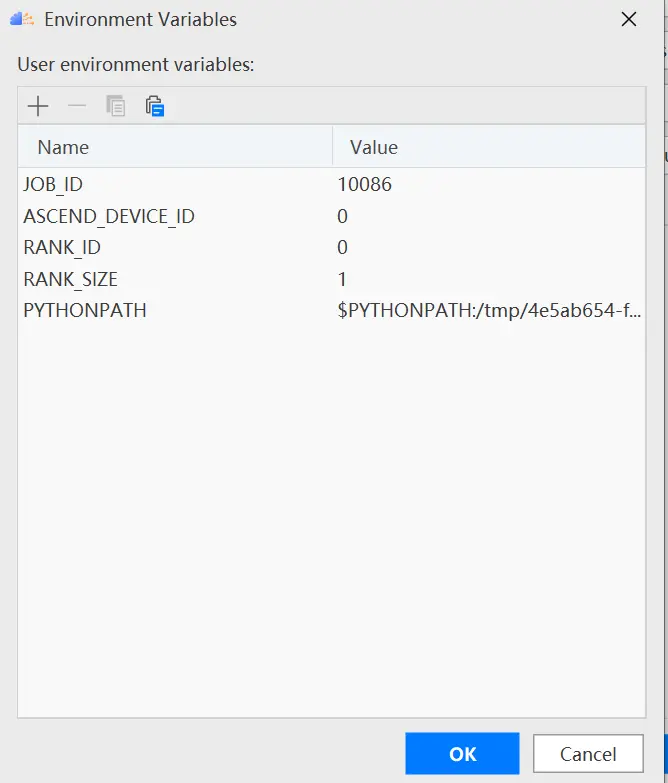
环境变量的解释如下表所示:
步骤四 执行训练生成dump数据。
点击按钮开始训练
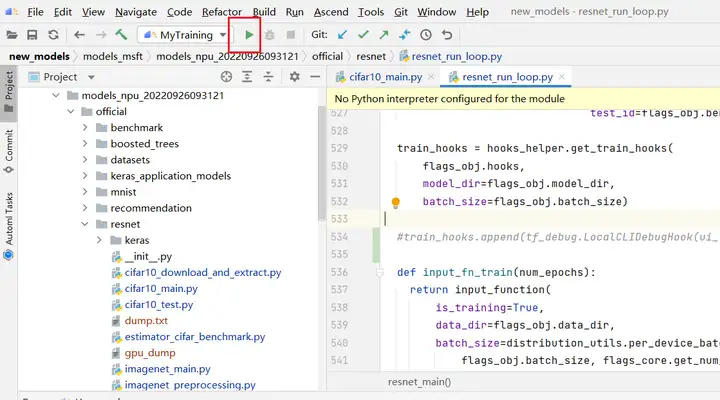
训练时控制台输出如下所示:
resnet目录下生成的数据文件展示如下:

在所有以“_Build.txt”为结尾的dump图文件中,查找“Iterator”这个关键词。记住查找出的计算图文件名称,用于后续精度比对。

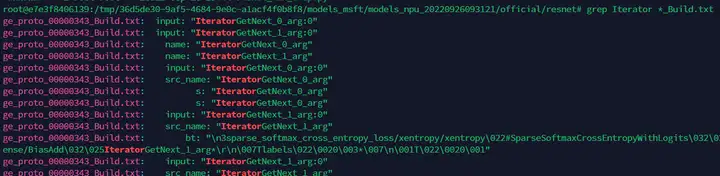
如上图所示,“ge_proto_00000343_Build.txt”文件即是我们需要找到的计算图文件。将此文件拷贝至用户家目录下,便于在执行比对操作时选择。
打开上面找到的计算图文件,记录下第一个graph中的name字段值。如下示例中,记录下“ge_default_20220926160231_NPU_61”。
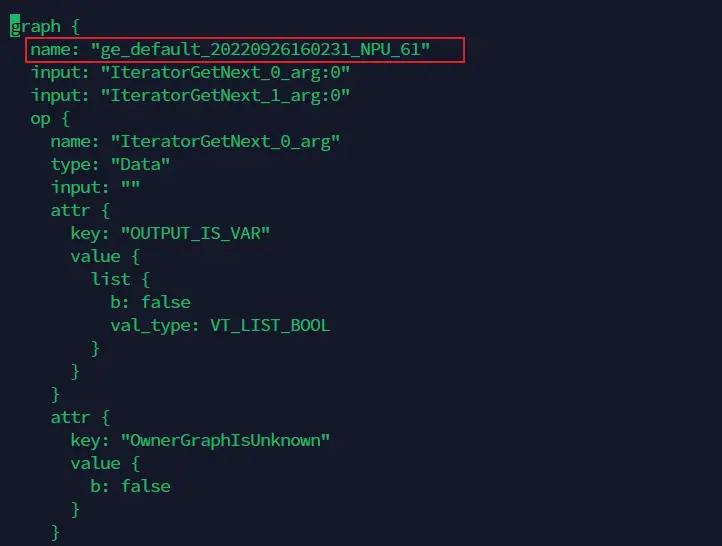
进入以时间戳命名的dump文件存放路径下,找到刚记录的名称为name值的文件夹,例如ge_default_20220926160231_NPU_61,则下图目录下的文件即为需要的dump数据文件:

在MindStudio菜单栏选择“Ascend > Model Accuracy Analyzer > New Task”,进入精度比对参数配置界面。
配置tookit path,点击文件标识,如下图所示:
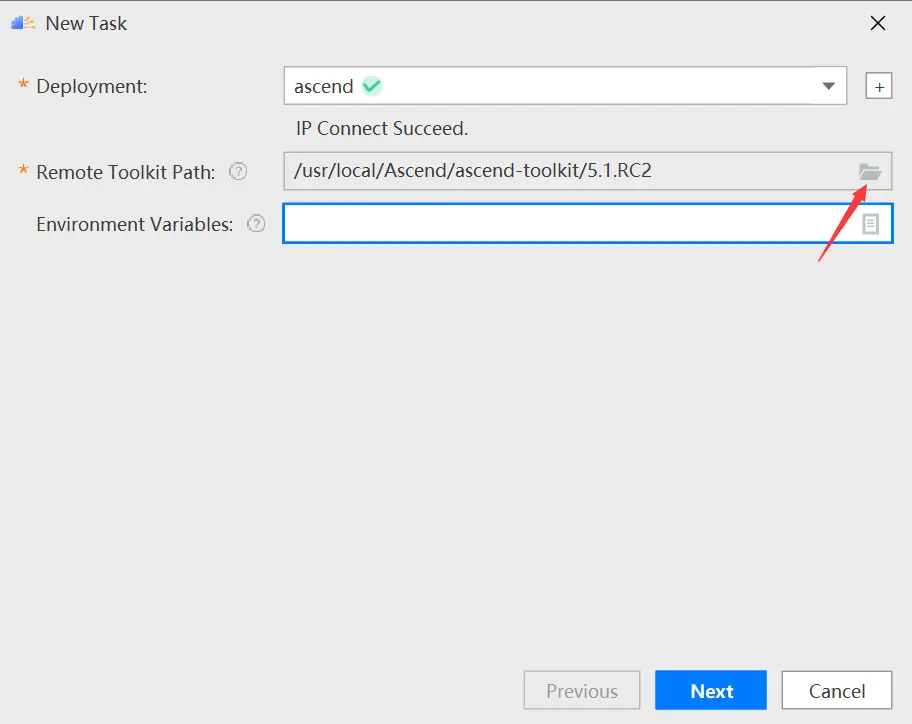
选择对应的版本,如5.1.RC2版本,单击ok:
单击next进入参数配置页面:
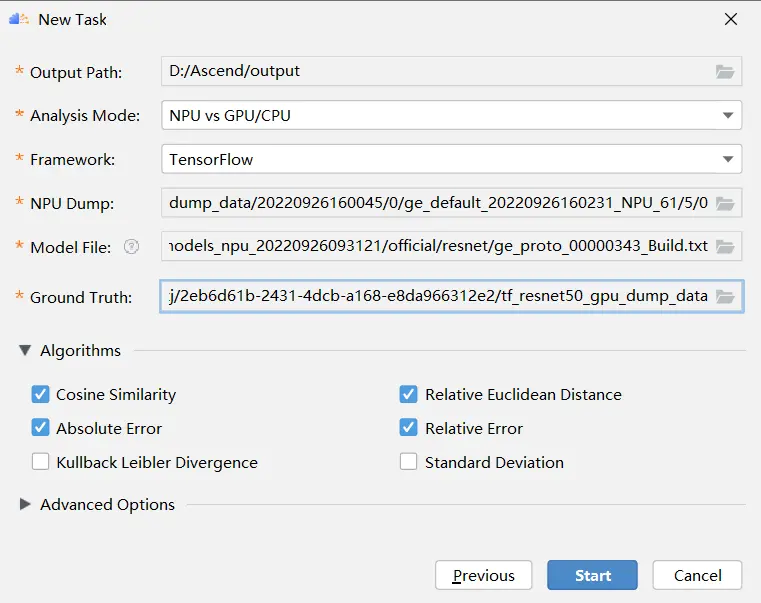
接着填写gpu和npu的数据的相关信息,如下图所示:
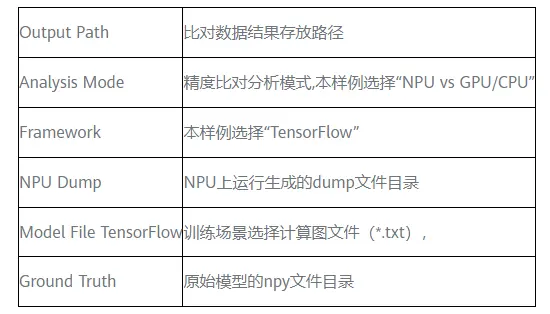
参数解释如下所示:
点击start:
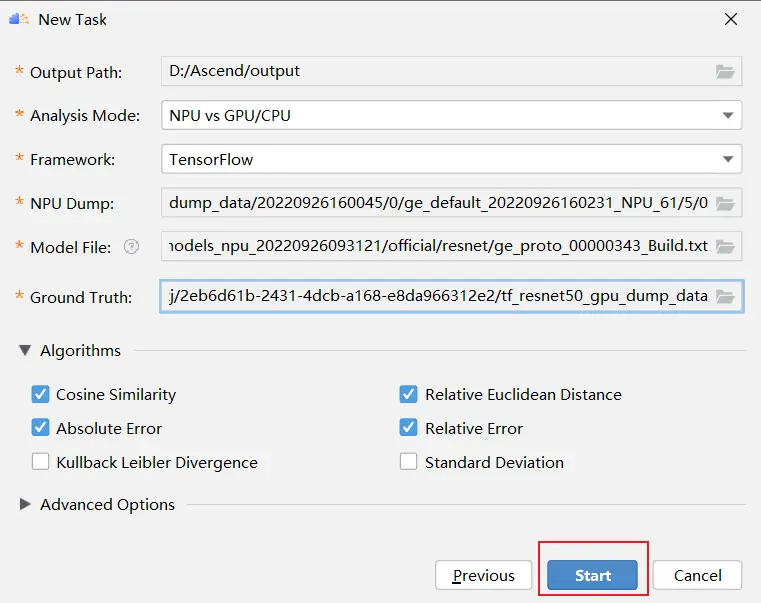

结果展示:
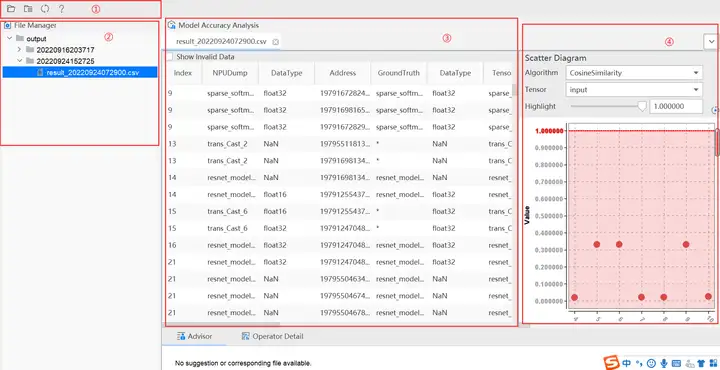
如上图所示将Vector比对结果界面分为四个区域分别进行介绍。
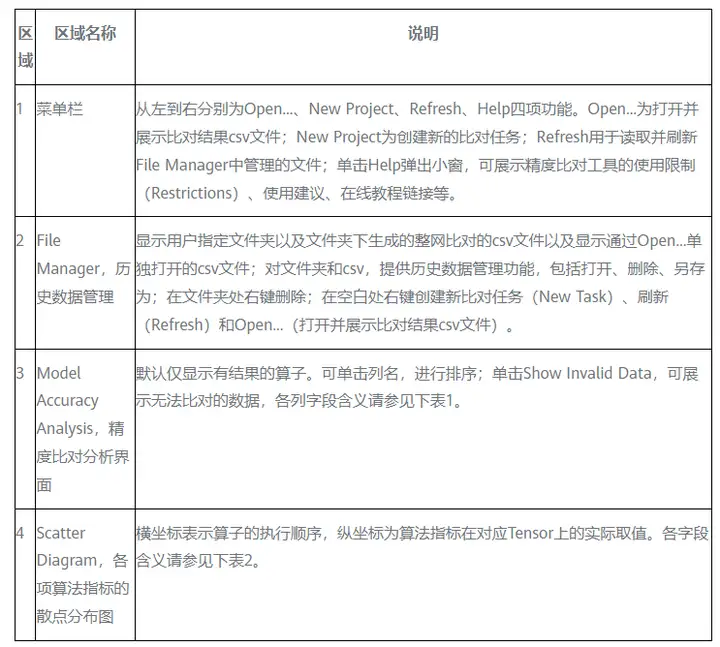
表1 精度比对分析界面字段说明
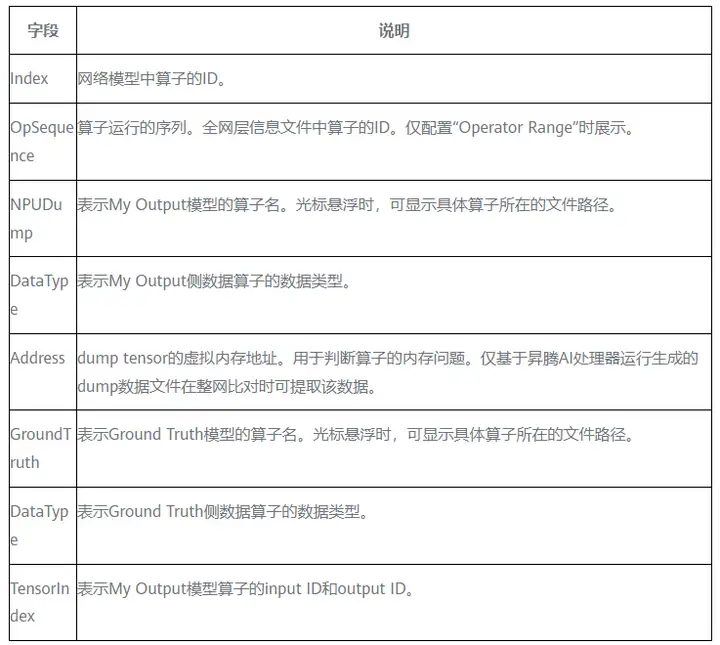
表2 散点分布图字段说明

Q:tfdbg复制pt命令时执行出错
A:由于tfdbg将多行的pt命令识别为了单个命令,使得命令执行失败。解决办法如下:
import pexpect
import sys
cmd_line = 'python3 -u ./cifar10_main.py'
tfdbg = pexpect.spawn(cmd_line)
tfdbg.logfile = sys.stdout.buffer
tfdbg.expect('tfdbg>')
tfdbg.sendline('run')
pt_list = []
with open('dump.txt', 'r') as f:
for line in f:
pt_list.append(line.strip('\n'))
for pt in pt_list:
tfdbg.expect('tfdbg>')
tfdbg.sendline(pt)
tfdbg.expect('tfdbg>')
tfdbg.sendline('exit')6.保存退出vim,执行python auto_run.py
更多的疑问和信息可以在昇腾论坛进行讨论和交流:https://bbs.huaweicloud.com/forum/forum-726-1.html
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#