本内容分为两部分
- 1. waymo数据集转KITTI格式
- 2. FCOS3D训练KITTI格式的waymo数据集
waymo数据集v1.2.0可以从这里下载。其中,train(32个压缩包),test(8个压缩包),val(8个压缩包)。这里的文件都是压缩包,每个都有20个G左右。
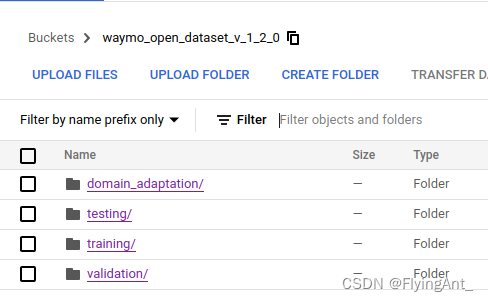
如果不想下载压缩包,可以下载解压好individual的segments。
waymo数据集的解析代码在这里,可以按照demo进行解析与可视化。GitHub - waymo-research/waymo-open-dataset: Waymo Open Dataset
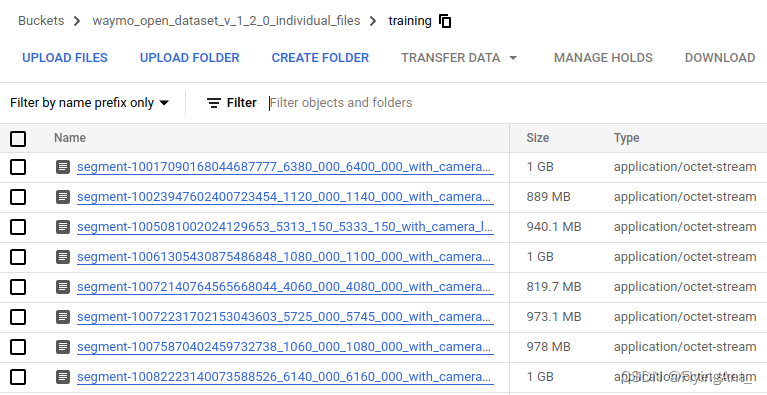
waymo(v1.2.0)数据集包含train(32个压缩包),test(8个压缩包),val(8个压缩包)。每个压缩包解压得到24个左右的tfrecord文件。一个tfrecord文件中包含20s的连续驾驶画面,具有199帧数据,是连续时间段的数据帧,一帧中包含了车上所有传感器的数据以及相应的label,连续镜头内容可以使得研究人员开发模型来跟踪和预测其他道路使用者的行为。
下图是一帧5个相机的画面:

解析指导参考这里:Waymo数据集解析_waymo筛选前向雷达标签_ARIC_TXB的博客-CSDN博客
我这里使用的是mmdetection3d的master分支,
准备工作
1. 创建waymo-kitti/kitti_format文件夹,用于将waymo数据集转到kitti数据集。
2. 将 ImageSets 放到waymo-kitti2/kitti_format/文件夹下
step1.
pip install waymo-open-dataset-tf-2-5-0
step2 run create_data.py
内参|原点_Waymo dataset+mmdet3d的坐标系问题
问1 :frame_based、mv_image_based、fov_image_based分别是什么意思?
答:frame_based会使用周视的雷达数据,mv_image_based使用多个视角的camera图像,fov_image_based只是用一个默认视角的图像,可以理解为使用前视角
问2:报错内容“ BaseMono3DDenseHead.loss() - bboxes (:obj:`BaseInstance3DBoxes`): Contains a tensor with shape (num_instances, C), the last dimension C of a 3D box is (x, y, z, x_size, y_size, z_size, yaw, ...), where C >= 7. C = 7 for kitti and C = 9 for nuscenes with extra 2 dims of velocity.
答:nuscenes数据集的label有9个项目,最后两个是速度,而kitti和waymo是没有的,所以需要将初始化数据集类属性为7
问3:报错的原因在于 instances[0].keys() 中没有 attr_label ,这是不对的,框没有类别!这个attr_label标识的是nuscence数据集中,目标的运动属性,运动、停止、等。kitti和waymo是没有的,所以,将代码屏蔽,同时关闭属性预测功能。
train_pipeline = [ dict(type='LoadImageFromFileMono3D'), dict( type='LoadAnnotations3D', with_bbox=True, with_label=True, with_attr_label=False, with_bbox_3d=True, with_label_3d=True, with_bbox_depth=True),这样,就不会执行这一句【】
# mmdet3d/datasets/pipeline/loading.LoadAnnotations3D.__call__() if self.with_attr_label: results = self._load_attr_labels(results)
在按照官方指导安装mmdetection3d的时候,经常出现mmcv版本不对的问题,其实安装mmcv有3种方式。
方式一:mim install mmcv-full
方式二:
Installation — mmcv 1.7.1 documentation
方式三:本地编译安装对应版本 Releases · open-mmlab/mmcv · GitHub
1. mmdet3d纯视觉baseline之数据准备:处理waymo dataset v1.3.1_ZLTJohn的博客-CSDN博客
2. mmdet3d读入waymo dataset:from file to input tensor-CSDN博客
3. mmdet3d training 流程_mmdet dist_train.sh_ZLTJohn的博客-CSDN博客
4. https://github.com/open-mmlab/mmdetection3d/issues/865
5. 关于Reszie3D · Issue #5 · Tai-Wang/Depth-from-Motion · GitHub
6. https://github.com/open-mmlab/mmdetection3d/issues/857
7. https://github.com/open-mmlab/mmdetection3d/pull/964
8. 各种 attention 改进YOLOv5系列:19.添加SEAttention注意力机制_改进yolov5系列19添加seattention注意力机制_芒果汁没有芒果的博客-CSDN博客
9. mmdet3d纯视觉baseline之数据准备:处理waymo dataset v1.3.1_ZLTJohn的博客-CSDN博客
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion是否有适用于这些的3d游戏引擎?
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我正在尝试训练一个前馈网络来使用Ruby库AI4R执行异或运算。然而,当我在训练后评估XOR时。我没有得到正确的输出。有没有人以前使用过这个库并得到它来学习异或运算。我使用了两个输入神经元,一个隐藏层中的三个神经元,一个输出层,正如我看到的预计算XOR前馈神经网络就像这样。require"rubygems"require"ai4r"#Createthenetworkwith:#2inputs#1hiddenlayerwith3neurons#1outputsnet=Ai4r::NeuralNetwork::Backpropagation.new([2,3,1])example=[[0,
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S