MATLAB 支持向量机(SVM)详细解释(含代码)
简单来讲就是如何将两个数据用点、直线、平面分开。。。。。

二维空间中,要分开两个线性可分的点集合,我们需要找到一条分类直线即可,
通俗来讲,在这个二维平面中,可以把两类点的分开的直线有很多条,那么这些直线中,哪一条才是最好的呢?也就是如何选择出一条最好的直线呢?
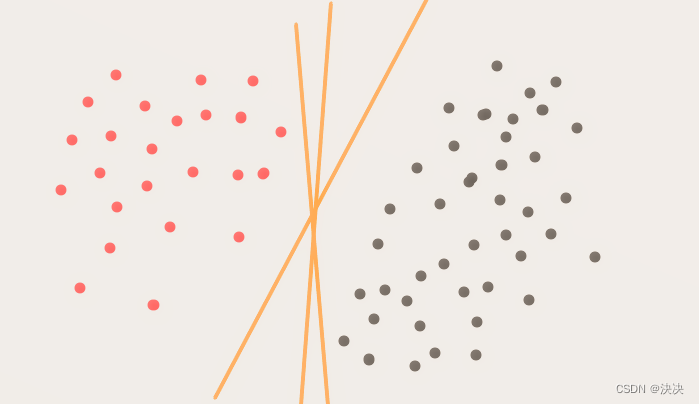
先看橙色的点,如果这些点到分类直线的距离越大,分类直线也就越远离橙色的点,那么再来一个新的点,如果这个点是依照橙色点集合的特性产生的(也就是它不是一个相对于橙色点集合很奇异的点),那么这个点也很可能和橙色的点集合一样,分布在直线的同一侧。分布在同一侧,表明它和橙色集合点属于同一个类别。用同样的思想,图4中,对于灰色的集合点,这条分类直线离它们的距离也要越远越好。所以找最优分类线,就是要找到这条一条直线,使它到两个类别点的距离越大越好。
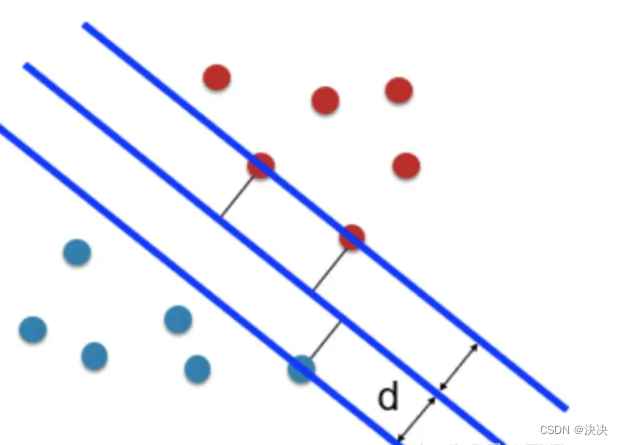
因此便可得到某根距离离两边都累计最远的直线,即最大分隔超平面。
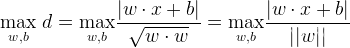
上述也叫硬间隔最最大化,能够用直线将两者分开。
工具:1、MATLAB 2020a;2、fitcsvm
fitcsvm:fitcsvm训练或交叉验证支持向量机(SVM)模型在低维或中维预测数据集上的一类和二类(binary)分类。fitcsvm支持使用核函数映射预测数据,并支持通过二次规划实现目标函数最小化的顺序最小优化(SMO,sequential minimal optimization)、迭代单数据算法(ISDA,iterative single data algorithm)或L1软边界最小化。
代码:
clc
clear all
%设置两类不同数据
A = [3,7;6,6;4,6;5,6.5];
B = [1,2;3,5;7,3;3,4;6,2.7;4,3;2,7];
C = [A;B];%两类数据合并
%设置不同类别标签
table = [true true true true false false false false false false false];
D = nominal(table);
%%数据集和标签
sd=C;
Y=D;
%% 原始数据图像
subplot(1,2,1)
gscatter(sd(:,1),sd(:,2),Y,'rg','+*');
%% SVM
SVMModel=fitcsvm(sd,Y,'KernelFunction','linear');
[lable,score]=predict(SVMModel,sd);
%% 画图
subplot(1,2,2)
h = nan(3,1);
h(1:2) = gscatter(sd(:,1),sd(:,2),Y,'rg','+*');
hold on
h(3) =plot(sd(SVMModel.IsSupportVector,1),sd(SVMModel.IsSupportVector,2), 'ko');%画出支持向量
%画出决策边界
w=-SVMModel.Beta(1,1)/SVMModel.Beta(2,1);%斜率
b=-SVMModel.Bias/SVMModel.Beta(2,1);%截距
x_ = 0:0.01:10;
y_ = w*x_+b;
plot(x_,y_)
hold on
legend(h,{'-1','+1','Support Vectors'},'Location','Southeast');
axis equal
hold off
实验结果:
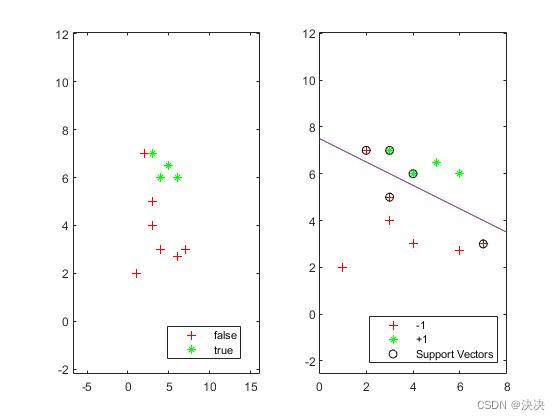
上述实验得到一个硬间隔最大化的分隔超平面
clc
clear all
%设置两类不同数据
A = [0.9,1;0.8,1.8;0.79,1.7;0.7,3;0.8,3.9;0.9,4.5;1.2,5.7;1.6,5.6;2.5,6.1;2.9,5.8; 2.9,1;3.1,1.4;3.6,1.2;5,2;5.5,3.9;4.9,4.5;4.2,5.9;3.6,5.6;2.5,5.1;2.9,5.3];
B = [2.5,3.1;3.5,2.6;4.5,3.2;3.5,2;2.4,2;3.5,2.5;4.3,3.7;2.6,2.8;2.4,3;3.6,3.1;4.4,3.3; 2.5,4.0;3.5,4.1;4.5,4.2;1.5,4;2.4,4;3.5,4.5;4.3,3.7;3.6,3.8;2.4,3.5;3.6,3.7;4.4,3.3];
C = [A;B];%两类数据合并
%设置不同类别标签
table = [true true true true true true true true true true true true true true true true true true true true false false false false false false false false false false false false false false false false false false false false false false];
D = nominal(table);
%%数据集和标签
sd=C;
Y=D;
%% 原始数据图像
subplot(1,2,1)
gscatter(sd(:,1),sd(:,2),Y,'rg','+*');
%% 原始数据图像
subplot(1,2,1)
gscatter(sd(:,1),sd(:,2),Y,'rg','+*');
%% SVM
SVMModel=fitcsvm(sd,Y,'BoxConstraint',10,'KernelFunction','rbf','KernelScale',2^0.5*2);%使用高斯核函数
%%SVMModel=fitcsvm(sd,Y,'KernelFunction','rbf','OptimizeHyperparameters',{'BoxConstraint','KernelScale'}, 'HyperparameterOptimizationOptions',struct('ShowPlots',false));%使用超参数优化
%% 画图
subplot(1,2,2)
h = nan(3,1);
h(1:2) = gscatter(sd(:,1),sd(:,2),Y,'rg','+*');
hold on
h(3) = plot(sd(SVMModel.IsSupportVector,1),sd(SVMModel.IsSupportVector, 2),'ko'); %画出支持向量
%画出决策边界
h = 0.2;
[X1,X2] = meshgrid(min(sd(:,1)):h:max(sd(:,1)),min(sd(:,2)):h:max(sd(:,2)));
%得到所有取点的矩阵
[lable,score]=predict(SVMModel,[X1(:),X2(:)]);
scoreGrid = reshape(score(:,2),size(X1,1),size(X2,2));
contour(X1,X2,scoreGrid,[0 0]);%绘制等高线
hold on
legend('-1','+1','Support Vectors','分界线');
axis equal
hold off
实验结果:
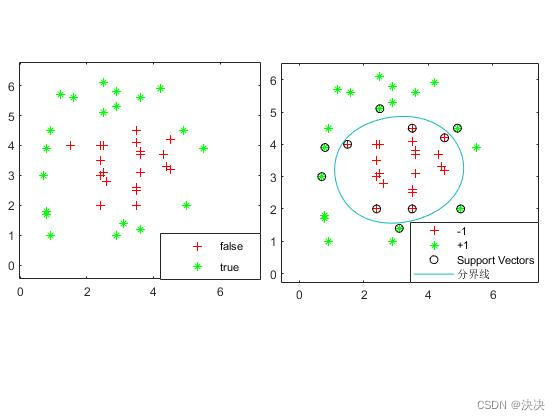
上述实验进行非线性的数据分类
一对多法(one-versus-rest,简称OVR SVMs)
训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
假如我有四类要划分(也就是4个Label),他们是A、B、C、D。
于是我在抽取训练集的时候,分别抽取
(1)A所对应的向量作为正集,B,C,D所对应的向量作为负集;
(2)B所对应的向量作为正集,A,C,D所对应的向量作为负集;
(3)C所对应的向量作为正集,A,B,D所对应的向量作为负集;
(4)D所对应的向量作为正集,A,B,C所对应的向量作为负集;
使用这四个训练集分别进行训练,然后的得到四个训练结果文件。在测试的时候,把对应的测试向量分别利用这四个训练结果文件进行测试。最后每个测试都有一个结果f1(x),f2(x),f3(x),f4(x)。于是最终的结果便是这四个值中最大的一个作为分类结果。
数据链接: [https://pan.baidu.com/s/1QUNknb-AV-cPt0hM_jSs_Q ]提取码:http
代码:
clc;
clear;
close all;
%%导入数据:训练集、测试集、训练标签、测试标签
train_data=xlsread('train_data.xls');
group_train=xlsread('group_train.xls');
test_data=xlsread('test_data.xls');
test_labels=xlsread('test_labels.xls');
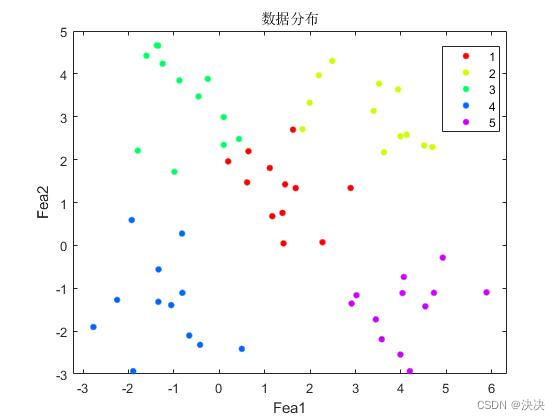
%%绘数据分布图
gscatter(train_data(:,1),train_data(:,2),group_train);
title('数据分布');
xlabel('Fea1');
ylabel('Fea2');
%%
% 训练数据分为5类
% 类别i的 正样本 选择类别i的全部,负样本 从其余类别中随机选择(个数与正样本相同)
%%
% 类别1
class1_p = train_data(1:12,:);
% randperm(n,k)是从1到n的序号中随机返回k个
index1 = randperm(48,12);
train_data_c = train_data;
train_data_c(1:12,:) = [];%正样本
class1_n = train_data_c(index1,:);%负样本
train_features1 = [class1_p;class1_n];
% 正类表示为1,负类表示为-1
train_labels1 = [ones(12,1);-1*ones(12,1)];
%% 类别2
class2_p = train_data(13:24,:);
% randperm(n,k)是从1到n的序号中随机返回k个
index1 = randperm(48,12);
train_data_c = train_data;
train_data_c(13:24,:) = [];%正样本
class2_n = train_data_c(index1,:);%负样本
train_features2 = [class2_p;class2_n];
% 正类表示为1,负类表示为-1
train_labels2 = [ones(12,1);-1*ones(12,1)];
%% 类别3
class3_p = train_data(25:36,:);
% randperm(n,k)是从1到n的序号中随机返回k个
index1 = randperm(48,12);
train_data_c = train_data;
train_data_c(25:36,:) = [];%正样本
class3_n = train_data_c(index1,:);%负样本
train_features3 = [class3_p;class3_n];
% 正类表示为1,负类表示为-1
train_labels3 = [ones(12,1);-1*ones(12,1)];
%% 类别4
class4_p = train_data(37:48,:);
% randperm(n,k)是从1到n的序号中随机返回k个
index1 = randperm(48,12);
train_data_c = train_data;
train_data_c(37:48,:) = [];%正样本
class4_n = train_data_c(index1,:);%负样本
train_features4 = [class4_p;class4_n];
% 正类表示为1,负类表示为-1
train_labels4 = [ones(12,1);-1*ones(12,1)];
%% 类别5
class5_p = train_data(49:60,:);
% randperm(n,k)是从1到n的序号中随机返回k个
index1 = randperm(48,12);
train_data_c = train_data;
train_data_c(49:60,:) = [];%正样本
class5_n = train_data_c(index1,:);%负样本
train_features5 = [class5_p;class5_n];
% 正类表示为1,负类表示为-1
train_labels5 = [ones(12,1);-1*ones(12,1)];
%%
% 分别训练5个类别的SVM模型
model1 = fitcsvm(train_features1,train_labels1,'ClassNames',{'-1','1'});
model2 = fitcsvm(train_features2,train_labels2,'ClassNames',{'-1','1'});
model3 = fitcsvm(train_features3,train_labels3,'ClassNames',{'-1','1'});
model4 = fitcsvm(train_features4,train_labels4,'ClassNames',{'-1','1'});
model5 = fitcsvm(train_features5,train_labels5,'ClassNames',{'-1','1'});
%%
% label是n*1的矩阵,每一行是对应测试样本的预测标签;
% score是n*2的矩阵,第一列为预测为“负”的得分,第二列为预测为“正”的得分。
% 用训练好的5个SVM模型分别对测试样本进行预测分类,得到5个预测标签
[label1,score1] = predict(model1,test_data);
[label2,score2] = predict(model2,test_data);
[label3,score3] = predict(model3,test_data);
[label4,score4] = predict(model4,test_data);
[label5,score5] = predict(model5,test_data);
% 求出测试样本在5个模型中预测为“正”得分的最大值,作为该测试样本的最终预测标签
score = [score1(:,2),score2(:,2),score3(:,2),score4(:,2),score5(:,2)];
% 最终预测标签为k*1矩阵,k为预测样本的个数
final_labels = zeros(20,1);
for i = 1:size(final_labels,1)
% 返回每一行的最大值和其位置
[m,p] = max(score(i,:));
% 位置即为标签
final_labels(i,:) = p;
end
% 分类评价指标

matlab打开matlab,用最简单的imread方法读取一个图像clcclearimg_h=imread('hua.jpg');返回一个数组(矩阵),往往是a*b*cunit8类型解释一下这个三维数组的意思,行数、数和层数,unit8:指数据类型,无符号八位整形,可理解为0~2^8的数三个层数分别代表RGB三个通道图像rgb最常用的是24-位实现方法,即RGB每个通道有256色阶(2^8)。基于这样的24-位RGB模型的色彩空间可以表现256×256×256≈1670万色当imshow传入了一个二维数组,它将以灰度方式绘制;可以把图像拆分为rgb三层,可以以灰度的方式观察它figure(1
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
我已经按照https://github.com/wayneeseguin/rvm#installation上的说明通过RVM安装了Ruby.有关信息,我有所有文件(readline-5.2.tar.gz、readline-6.2.tar.gz、ruby-1.9.3-p327.tar.bz2、rubygems-1.8.24.tgz、wayneeseguin-rvm-stable.tgz和yaml-0.1.4.tar.gz)在~/.rvm/archives目录中,我不想在任何目录中重新下载它们方式。当我这样做时:sudo/usr/bin/apt-getinstallbuild-essent
我的Ruby-on-Rails项目中有以下文件结构,用于规范:/spec/msd/serviceservice_spec.rb/support/my_modulerequests_stubs.rb我的request_stubs.rb有:moduleMyModule::RequestsStubsmodule_functiondeflist_clientsurl="dummysite.com/clients"stub_request(:get,url).to_return(status:200,body:"clientsbody")endend在我的service_spec.rb我有:re
Ruby是否支持(找不到更好的词)非转义(逐字)字符串?就像在C#中一样:@"c:\ProgramFiles\"...或者在Tcl中:{c:\ProgramFiles\} 最佳答案 是的,您需要在字符串前加上%前缀,然后是描述其类型的单个字符。你想要的是%q{c:\programfiles\}。镐书很好地涵盖了这一点here,部分是通用分隔输入。 关于ruby-Ruby是否支持逐字字符串?,我们在StackOverflow上找到一个类似的问题: https:/
我正在编写一个Rubygem,在我的代码中使用{key:'value'}哈希语法。我的测试都在1.9.x中通过,但我(可以理解)在1.8.7中得到syntaxerror,unexpected':',expecting')'。是否有支持1.8.x的最佳实践?我是否需要使用我们的老friend=>重写代码,还是有更好的策略? 最佳答案 我认为你运气不好,如果你想支持1.8,那么你必须使用=>。像往常一样,我会提到在1.9的某些情况下您必须使用=>:如果键不是一个符号。请记住,任何对象(符号、字符串、类、float……)都可以是Ruby哈
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
在Rails中,什么是集成更新模型某些元素的UDP监听过程的最佳方式(特别是它将向其中一个表添加行)。简单的答案似乎是在同一个进程中使用UDP套接字对象启动一个线程,但我什至不清楚我应该在哪里做适合Rails方式的事情。有没有一种巧妙的方法来开始收听UDP?具体来说,我希望能够编写一个UDPController并在每个数据报消息上调用一个特定的方法。理想情况下,我希望避免在UDP上使用HTTP(因为它会浪费一些在这种情况下非常宝贵的空间),但我完全控制消息格式,因此我可以为Rails提供它需要的任何信息。 最佳答案 Rails是一个
我是Ruby和Watir-Webdriver的新手。我有一套用VBScript编写的站点自动化程序,我想将其转换为Ruby/Watir,因为我现在必须支持Firefox。我发现我真的很喜欢Ruby,而且我正在研究Watir,但我已经花了一周时间试图让Webdriver显示我的登录屏幕。该站点以带有“我同意”区域的“警告屏幕”开头。用户点击我同意并显示登录屏幕。我需要单击该区域以显示登录屏幕(这是同一页面,实际上是一个表单,只是隐藏了)。我整天都在用VBScript这样做:objExplorer.Document.GetElementsByTagName("area")(0).click