CI/CD 是一种持续开发软件的方法,侧重于软件开发过程中的自动化,可以不断地进行构建、测试和部署代码。使用这种方法,从新代码开发到部署,可以减少人工干预甚至不用干预
CI(Continuous Integration):持续集成,也就是当每一次更改的代码被推送到远程分支后,可以创建一组脚本来自动地构建和测试这些更改,确保这些更改可以通过一些基本的准则,减少引入错误的机会
CD:
(Continuous Delivery):持续交付,在持续集成的基础上更进一步,当每一次更改的代码落库后,不仅会构建和测试,也会进行部署,但是部署需要人工干预,手动的有目的进行部署
(Continuous Deployment):持续部署,持续集成之外的另一个步骤,类似于持续交付。不同之处在于,它不是手动部署应用程序,而是将其设置为自动部署。不需要人为干预
Gitlab CI/CD 也就是 Gitlab 提供了上面的 CI/CD 能力,可以进行持续集成,持续交付和持续部署
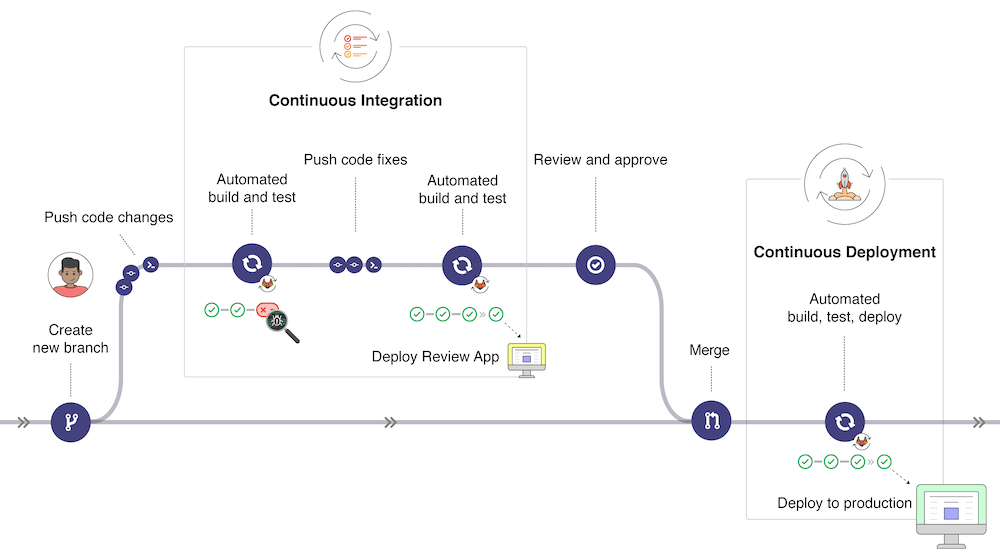
简单说就是开发者在push或者merge代码到指定分支的时候,会触发CI/CD,GitLab CI/CD配置文件(.gitlab-ci.yml)中的Job需要通过GitLab-Runner来执行,执行过后的产物可以直接用来部署。这里会涉及Pipeline 、Stages、Jobs几个概念
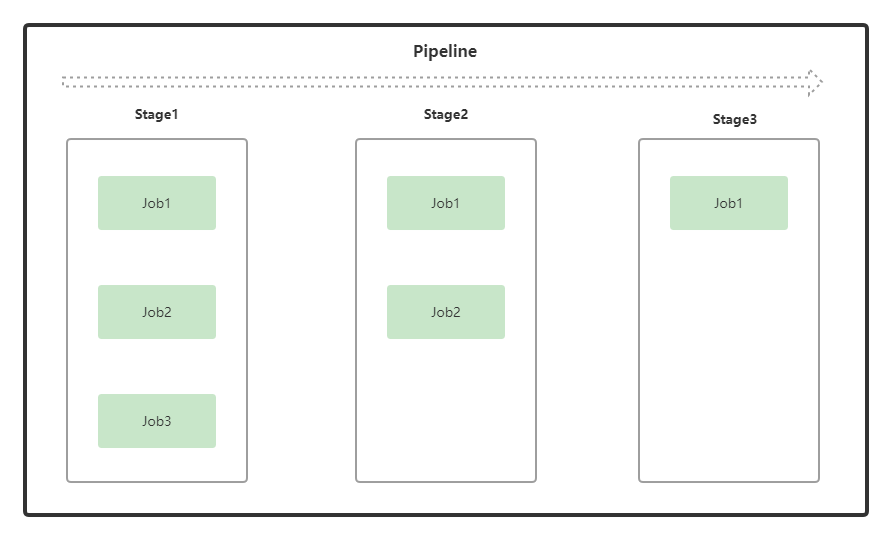
Pipelines:流水线 (在根目录包含.gitlab-ci.yml文件的代码push | merge时候会生成对应的流水线)
Stages:阶段 (定义什么时候执行Jobs,比如:在build阶段执行代码编译打包任务)
Jobs:任务是GitLab CI系统中可以独立控制并运行的最小单位 (定义了该做什么,比如:编译和测试代码)
流水线包含一个或多个阶段,每个阶段又可以有多个任务,这就是他们之间的一个关系。每个Job可以指定用来执行它的Runner,同一个Stage的多个Job可并发执行,Job中至少要包含script元素用来编写该任务运行的脚本,only元素用来指定能触发CI/CD的代码分支,tags元素用来指定该Job用哪个Runner来执行
如果同一个Stage中的所有Job都执行成功,Pipeline就会进入下一个Stage;如果一个Stage中的任何一个Job执行失败,Pipeline就不会进入下一个Stage,提前结束
前面有说到Job是需要GitLab-Runner才能运行起来的,那么它们是怎么关联起来的呢?
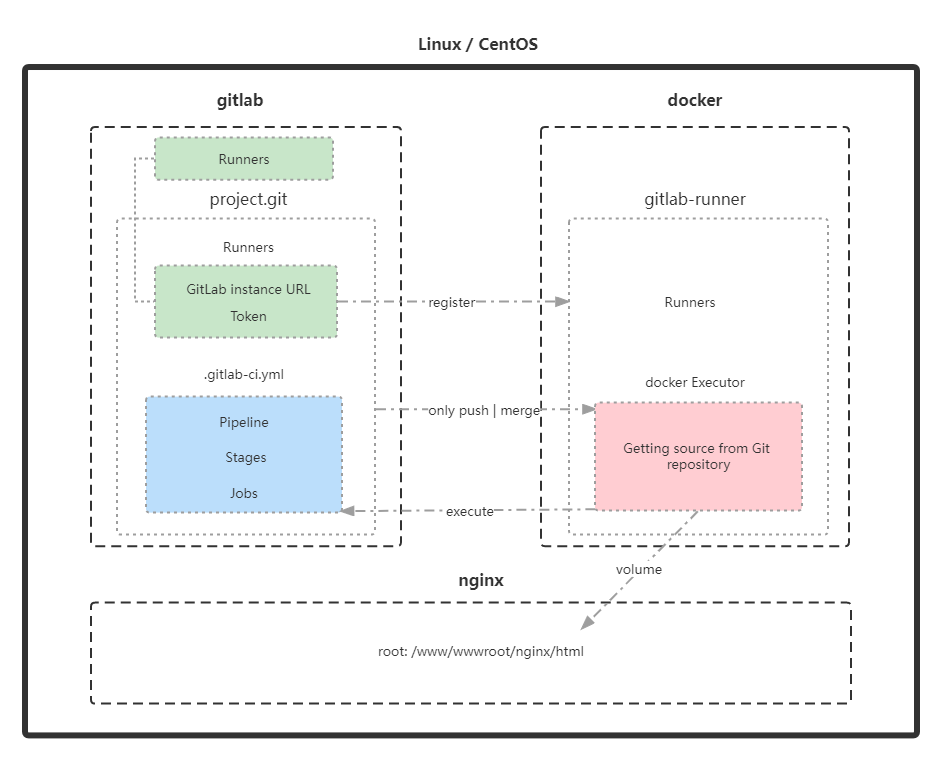
上面这张图采用docker来安装GitLab-Runner,然后将GitLab的实例URL和Token在GitLab-Runner上进行注册,这样GitLab和GitLab-Runner就能够关联上
GitLab-Runner注册Runners主要有两种方式:
1、在GitLab的admin area进入Runners菜单,里面就会有GitLab Instance URL和Token
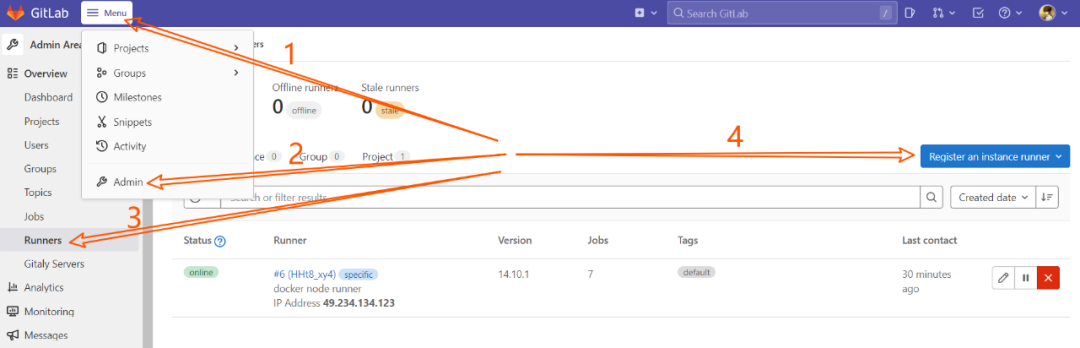
2、进到具体代码仓库,点开setting菜单,再进入CI/CD中的Runners,里面也会有GitLab Instance URL和Token
[外链图片转存中…(img-cDrdHUZW-1655395404070)]
Runner注册成功后会在GitLab的Runners列表中找到
[外链图片转存中…(img-TOBXyLc9-1655395404071)]
GitLab CI/CD完整执行过程如下:
1、编写CI/CD配置文件.gitlab-ci.yml,GitLab会检测到它,配置文件里可指定可触发CI/CD的代码分支
2、在push或者merge代码到上述指定的分支,会触发CI/CD流程,就会生成一个对应的Pipeline
3、GitLab-Runner就会将代码拉进来执行Pipeline中的Job,每个Job可指定用来执行它的Runner
4、Runner会初始化Excutor,然后通过git把GitLab的代码仓库拉过来,按照.gitlab-ci.yml里定义的任务来执行
5、本项目把Runner执行后的产物通过挂载的方式,把打包后的代码挂载到Nginx的根目录中,这样就完成了自动化部署
Runner执行Job过程:
[外链图片转存中…(img-Qh8fUGCJ-1655395404072)]
GitLab CI/CD最主要的两个步骤就是编写.gitlab-ci.yml,然后到GitLab-Runner中注册Runner,Runner可以是一个虚拟机,物理机,docker容器,或者一个容器集群。GitLab与Runner之间通过API进行通信,因此只需要Runner所在的机器有网络并且可以访问GitLab服务器即可
https://docs.gitlab.com/ee/ci
https://docs.gitlab.com/runner/register
https://zhuanlan.zhihu.com/p/441581000
喜欢的话别忘了 分享、点赞、收藏 三连~
欢迎关注公众号 前端进阶体验 收获更多优质文章~

前端进阶体验
分享前端技术,你想要的,这里都会有~
28篇原创内容
公众号
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
我想知道是否可以通过自动创建数组来插入数组,如果数组不存在的话,就像在PHP中一样:$toto[]='titi';如果尚未定义$toto,它将创建数组并将“titi”压入。如果已经存在,它只会推送。在Ruby中我必须这样做:toto||=[]toto.push('titi')可以一行完成吗?因为如果我有一个循环,它会测试“||=”,除了第一次:Person.all.eachdo|person|toto||=[]#with1billionofperson,thislineisuseless999999999times...toto.push(person.name)你有更好的解决方案吗?
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
我不确定如何为我的搜索功能添加自动完成表单。"get"do%>nil%>我有一个具有自定义操作的Controllerdefquery@users=Search.user(params[:query])@article=Search.article(params[:query])end模型如下:defself.user(search)ifsearchUser.find(:all,:conditions=>['first_nameLIKE?',"%#{search}%"])elseUser.find(:all)endenddefself.article(search)ifsearchArt
我对自动测试的工作方式的印象(基于cucumbergithubwiki和其他在线内容)是它应该重新运行红色示例,直到它们通过。我的问题是它会重新运行规范文件中找到失败示例的所有示例,包括通过的示例。我不想浪费时间在修复失败示例的同时重新运行通过的示例。是否可以配置自动测试以便仅运行失败的示例? 最佳答案 您需要rspec-retrygem。以下是文档中有关如何实现它的一些示例:将它应用到覆盖整个测试套件的configureblock中...RSpec.configuredo|config|config.verbose_retry=t
代码:threads=[]Thread.abort_on_exception=truebegin#throwexceptionsinthreadssowecanseethemthreadseputs"EXCEPTION:#{e.inspect}"puts"MESSAGE:#{e.message}"end崩溃:.rvm/gems/ruby-2.1.3@req/gems/activesupport-4.1.5/lib/active_support/dependencies.rb:478:inload_missing_constant':自动加载常量MyClass时检测到循环依赖稍加研究后,
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭4年前。Improvethisquestion我希望能够将模板化的YARD文档样式注释插入到我现有的Rails遗留应用程序中。目前它的评论很少。我想要具有指定参数的类header和方法header(通过从我假定的方法签名中提取)和返回值的占位符。在PHP代码中,我有一些工具可以检查代码并在适当的位置创建插入到代码中的文档header注释。在带有Ducktyping等的Ruby中,我确信诸如@params等类型之类