所有报错均为博主在实操过程中遇到的错误和解决办法,如果有其他报错或者不同的解决办法,请留言告诉我
安装canal过程中遇到问题,先在本文中查询是否有相同报错,将会为你节约大量排错时间
jdk1.8
canal 1.1.5
mysql8.0
es7.13.0
这是因为mysql驱动包的版本过低导致的,query cache在MySQL5.7.20就已经过时了,而在MySQL8.0之后就已经被移除了
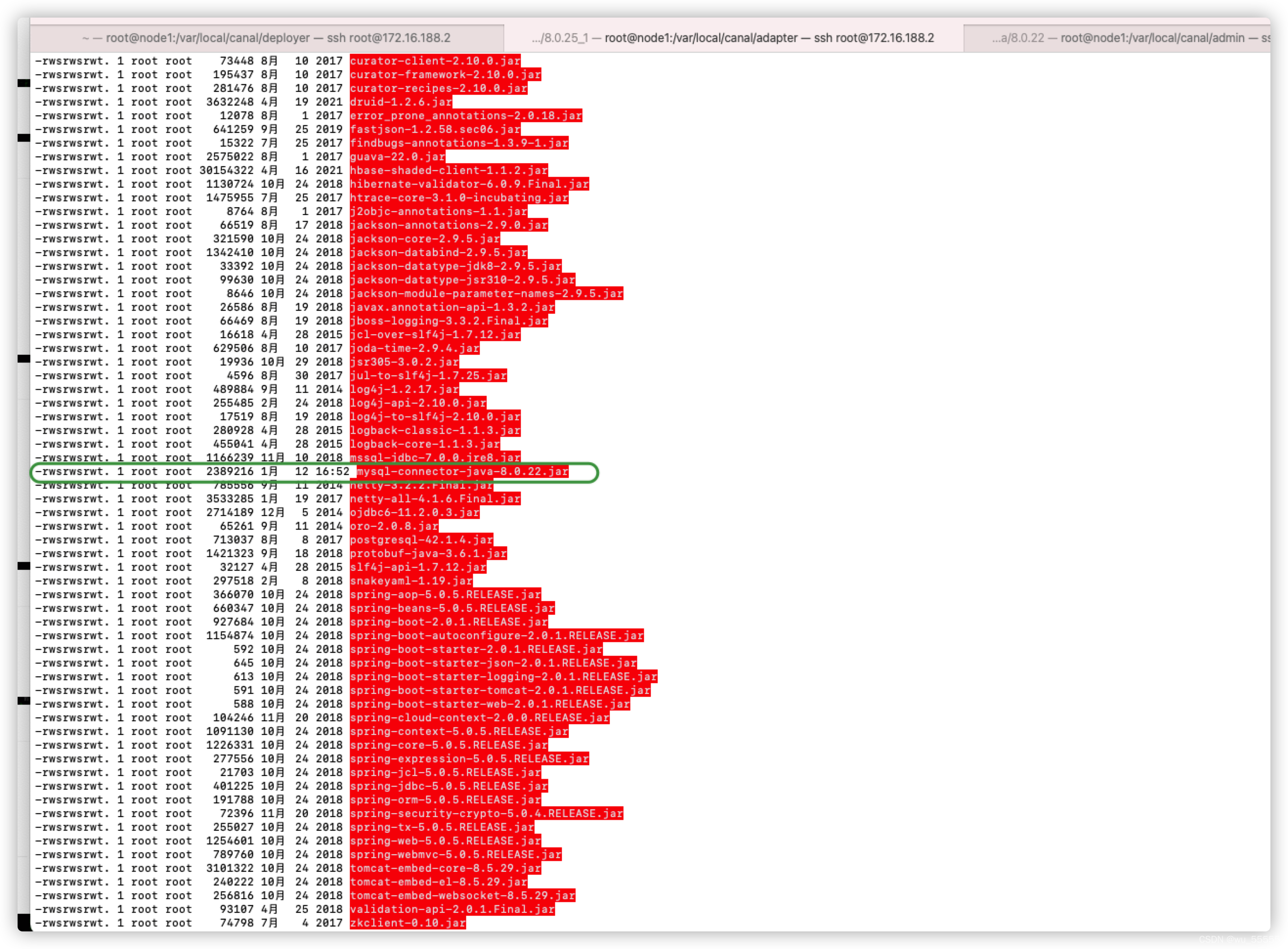
1、只需要将lib中的驱动器替换成mysql-connector-java-8.0.22.jar
2、修改驱动器权限
chmod 777 lib/mysql-connector-java-8.0.22.jar
chmod +st lib/mysql-connector-java-8.0.22.jar
查看权限如图所示
ll lib
启动canal-adapter报错:
Failed to bind properties under 'canal.conf.canal-adapters[0].groups[0].outer-adapters[1].properties' to java.util.Map<java.lang.String, java.lang.String>:
Reason: No converter found capable of converting from type [java.lang.String] to type [java.util.Map<java.lang.String, java.lang.String>]
解决:
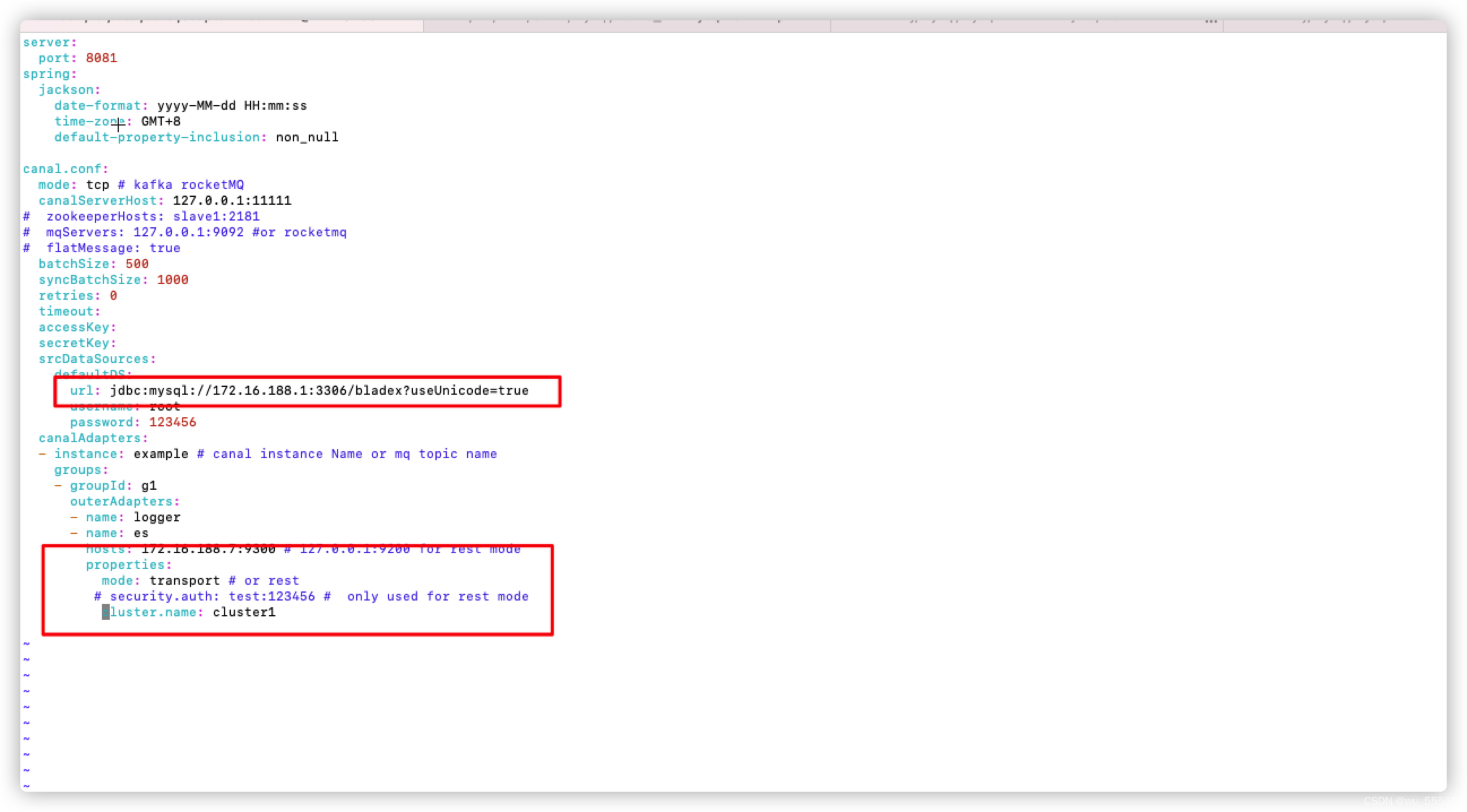
观察报错信息可以得知是配置文件中的outer2(0基,所以outer-adapter[1]实际指的是2)的properties配置有问题,我们观察配置文件,发现是properties下的mode,cluster.name等属性与properties同级了,将其如下图所示后退两字符即可。
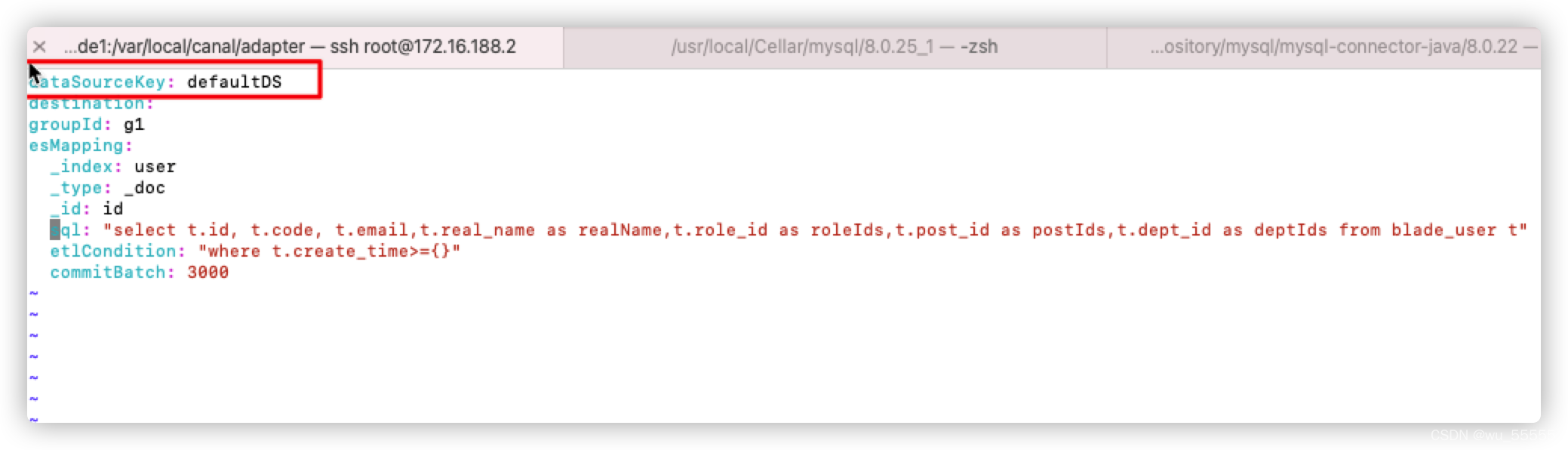
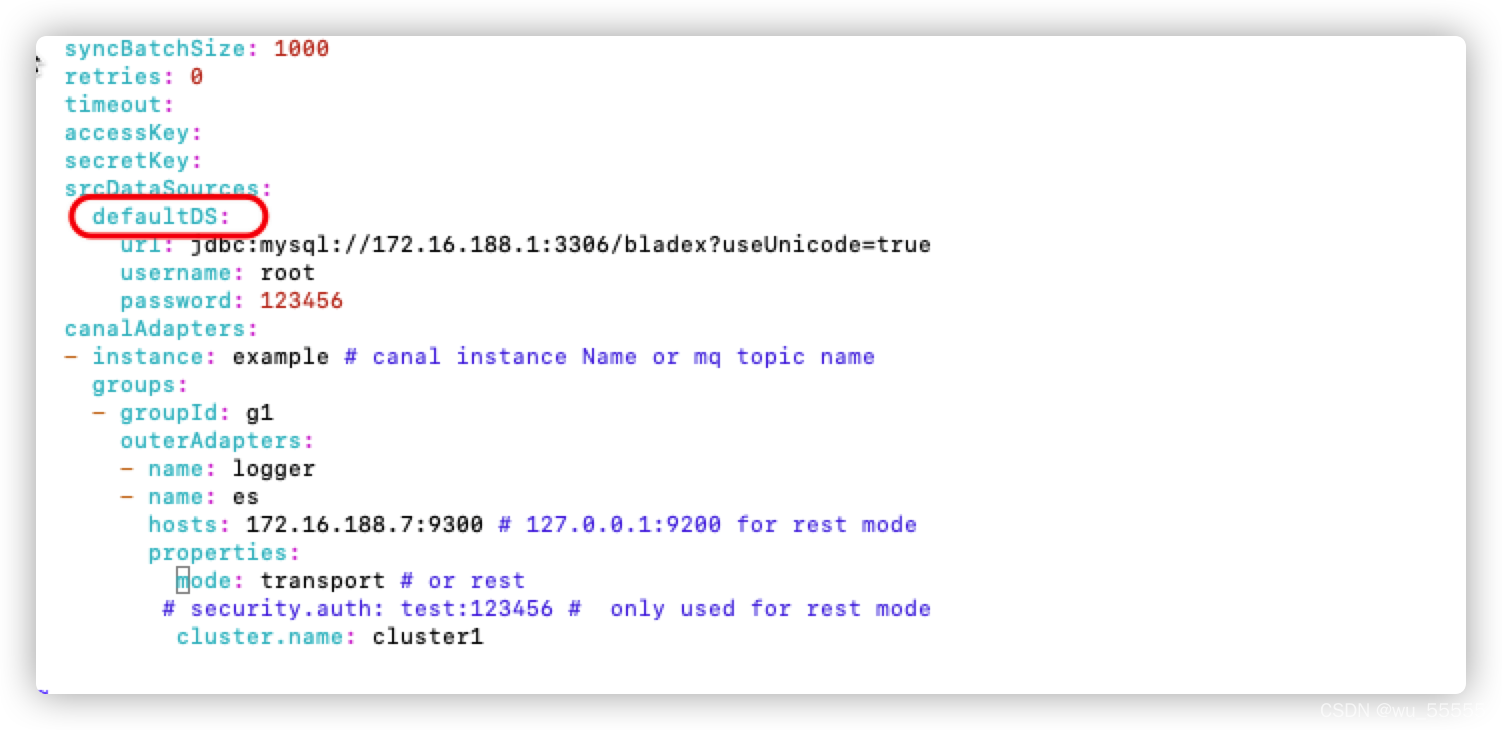
这个因为在conf/es/xxx.yml中配置的dataSourceKey并没有在conf/application.yml中的srcDataSources中维护
如下图所示,es中的dataSourceKey需要在applicaiton.yml中设置,默认是defaultDS
Failed to bind properties under 'canal.conf' to com.alibaba.otter.canal.adapter.launcher.config.AdapterCanalConfig:
Reason: Unable to set value for property src-data-sources
原因一:
mysql驱动器导致的问题,使用的数据库是8.x。驱动器是5.x的,将mysql驱动替换为8.0.x版本的。如上所示报错1
原因二:
检查该报错前的日志,是否有其他相关报错信息,比如无相关数据库,如下所示,根据其报错内容来检查配置项并且调整即可
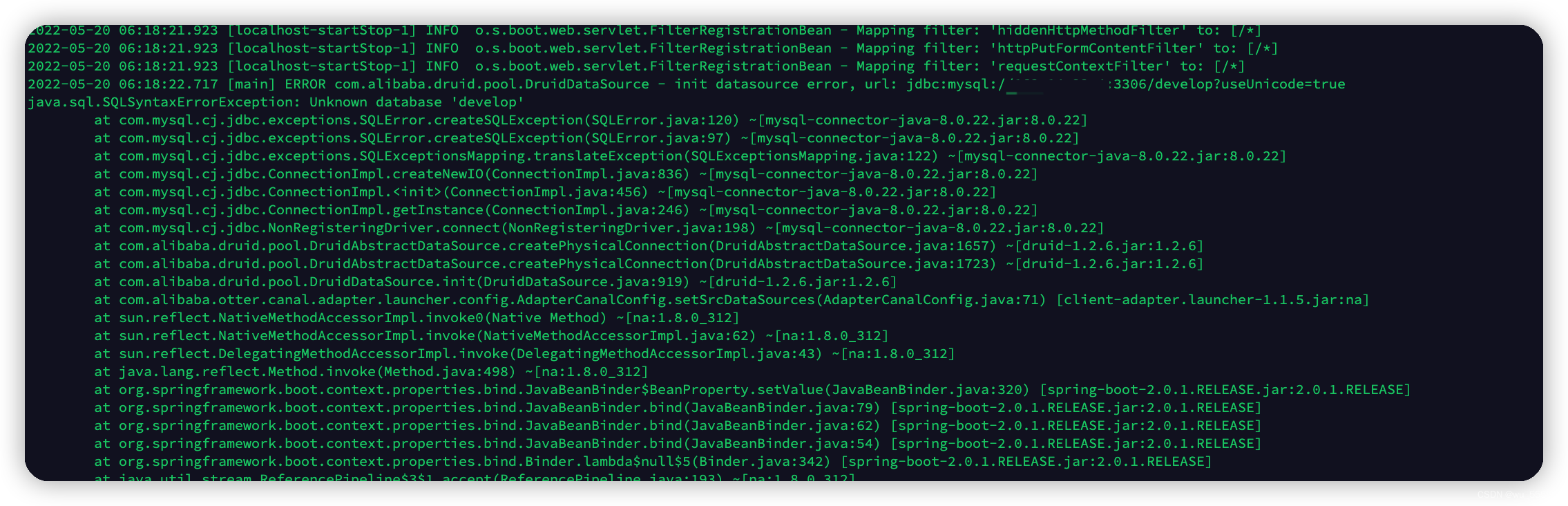
同一个ip在短时间内产生太多中断的数据库连接而导致的阻塞
登录对应的mysql,执行如下指令
flush hosts;
一般 could not be instantiated: class could not be found这样的报错是配置文件的问题,如上的报错可以看到是name: es7中的错误,在官方的示例文档中使用的是name: es6 # or es7。
在canal1.1.5+版本中设置的是name: es6 # 或者es7
但在1.1.4版本中直接使用name: es即可
1、这个报错是ES的mapping设置的问题,确保es中有该索引,并且确认是否有部分字段没有在es中设置mapping,这个要对应之前设置的sql,以及es中的mappings来解决
2、使用了elasticsearch 7.x,但adapter1.1.4默认支持es6.x
解决方案:
(1)修改adapter源码,将es依赖调整为7.x;参考博客adapter1.1.4修改源码支持es7.x
(2)换成adapter1.1.5
如果连接es使用的是rest方式,那么hosts中的ip前要添加http://,如
hosts: http://172.16.188.7:9200
java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassCastException: com.alibaba.druid.pool.DruidDataSource cannot be cast to com.alibaba.druid.pool.DruidDataSource
at com.alibaba.otter.canal.client.adapter.es7x.ES7xAdapter.init(ES7xAdapter.java:54) ~[client-adapter.es7x-1.1.5-jar-with-dependencies.jar:na]
at com.alibaba.otter.canal.adapter.launcher.loader.CanalAdapterLoader.loadAdapter(CanalAdapterLoader.java:225) [client-adapter.launcher-1.1.5.jar:na]
at com.alibaba.otter.canal.adapter.launcher.loader.CanalAdapterLoader.init(CanalAdapterLoader.java:56) [client-adapter.launcher-1.1.5.jar:na]
at com.alibaba.otter.canal.adapter.launcher.loader.CanalAdapterService.init(CanalAdapterService.java:60) [client-adapter.launcher-1.1.5.jar:na]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_271]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_271]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_271]
at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_271]
原因:
druid 包冲突
解决:
1、修改client-adapter/escore/pom.xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<!--add by whx 20220112-->
<scope>provided</scope>
</dependency>
2、重新打包
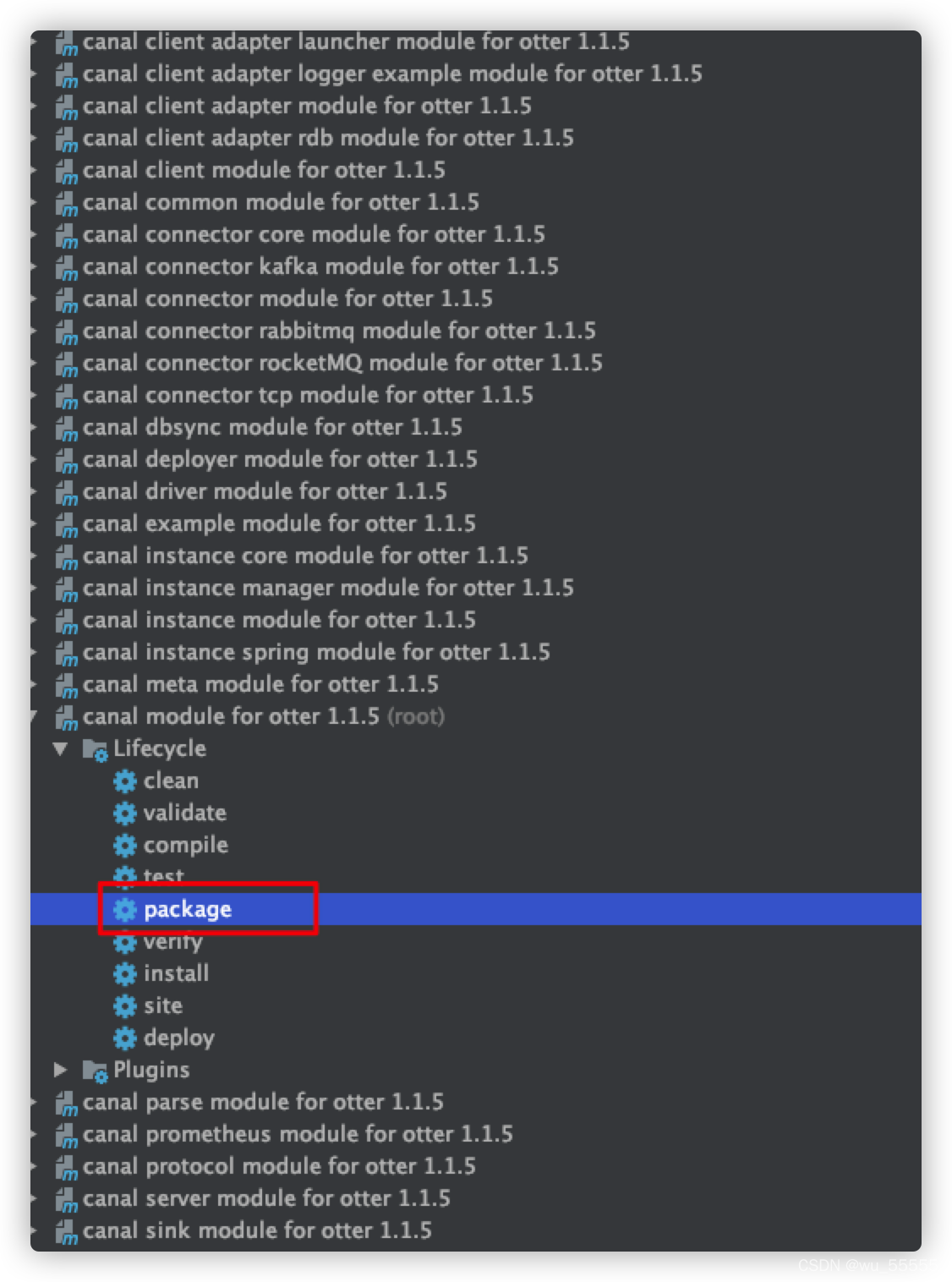
3、将client-adapter/es7x/target/client-adapter.es7x-1.1.5-jar-with-dependencies.jar上传到服务器,替换adataper/plugin下的同名jar文件
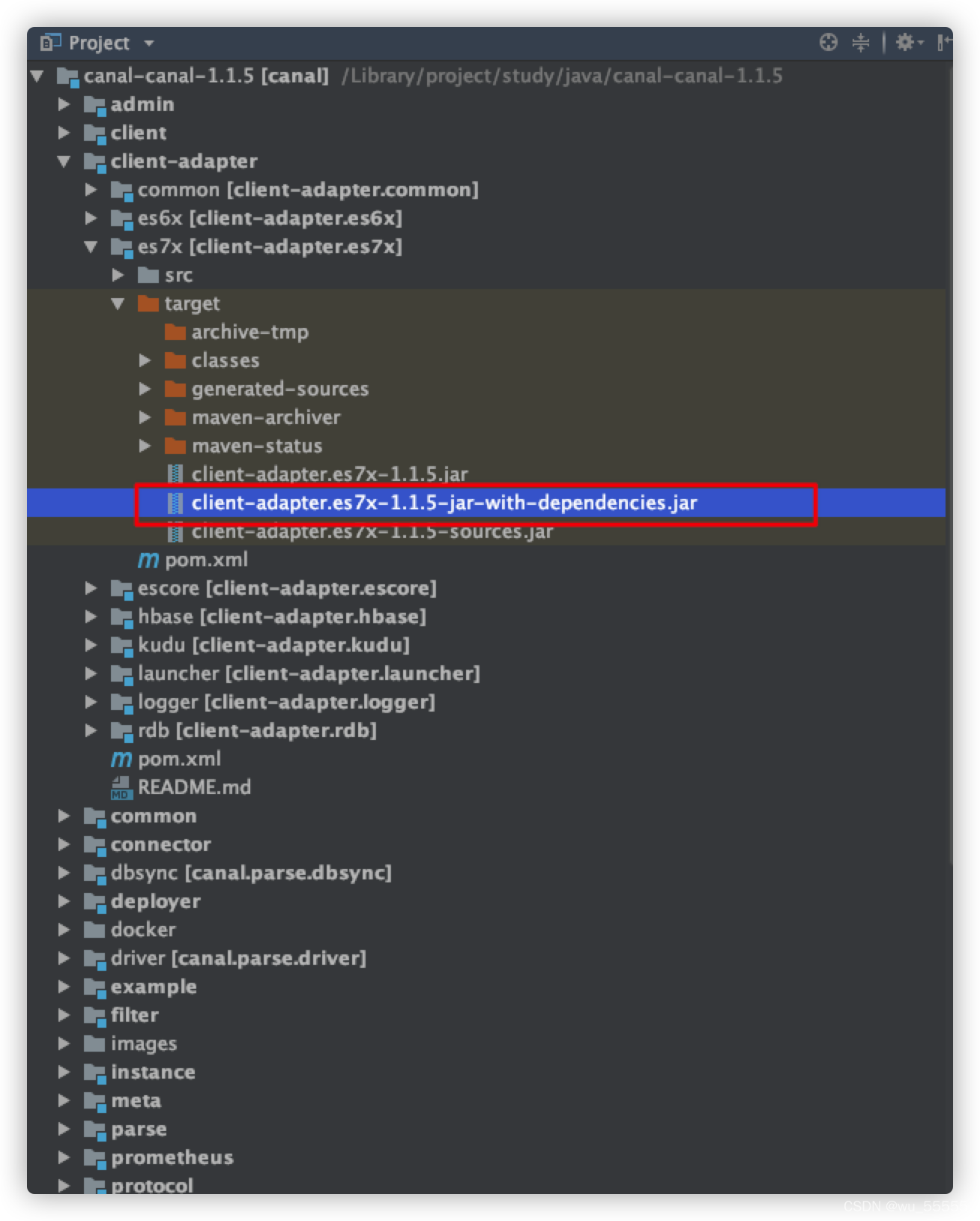
scp client-adapter.es7x-1.1.5-jar-with-dependencies.jar root@172.16.188.2:/var/local
4、给该文件赋权
chmod 777 /var/local/client-adapter.es7x-1.1.5-jar-with-dependencies.jar
5、重启服务
将lib目录下的mysql驱动器替换为mysql8.0,并附权。参考上述
服务连接断开了,将deployer和adapter都关闭,先启动deployer再启动adapter
1、es集群出现问题,导致doc无法分配。常见的是分片数的问题,可能是副本分片过多,导致集群报黄
解决:
因为我的是es单节点,所以将主分片数设置为1,副本分片设置为0。不申明的话默认创建副本分片数为1
PUT user
{
"mappings": {
"properties": {
"code": {
"type": "keyword"
},
"email": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"realName": {
"type": "text",
"analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"roleId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"postId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"deptId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
},
"settings": {
"number_of_replicas": 0,
"number_of_shards": 1
}
}
2、修改的mysql数据库数据,在es中不存在。先进行全量同步,再进行增量同步
在conf/example/instance.properties中修改
# 全量同步
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=0
#2019-01-01 00:00:00 上一次更新的时间
canal.instance.master.timestamp=1546272000000
这是由于deployer中的conf/example/meta.dat与instance.properties文件中的journalName,position,timestamp不一致导致的
# 查询bin log位置
show master status;
# 如果显示的binlog不为000001可以执行以下语句重置binlog(轻易别操作,最好让专业的运维人员操作)
# 该操作会重新生成binlog,之前的binlog就会清空,之前的数据就不会再同步
reset master;
# 刷新log日志,自此刻开始产生一个新编号的binlog日志文件
flush logs;
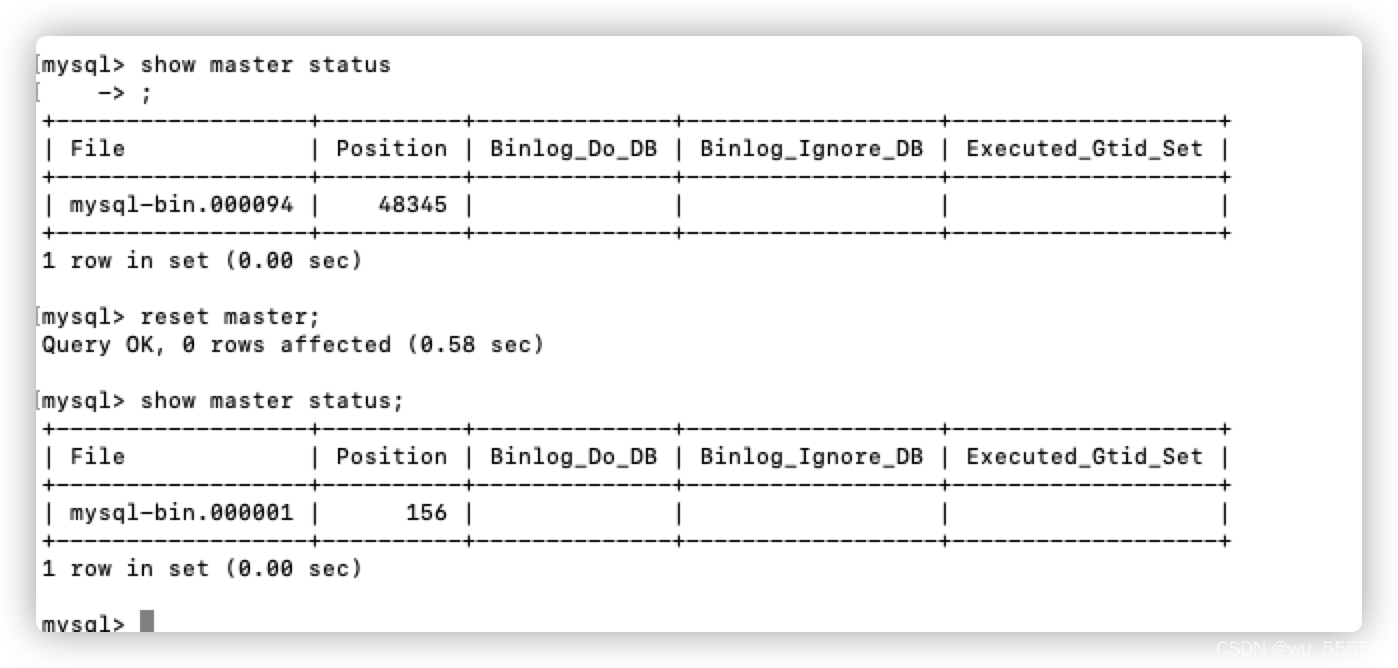
将meta.dat删除或者修改一致即可。删除后将会按照instance.properties中设置的起点同步,生产环境考虑好需要后再删除。
如果想要将之前的数据也同步的话,可以将数据库先导出,再重新导入一遍,即可重新生成binlog,实现数据的全量同步
mysql bin log数据不同步,刷新一下即可
flush logs;
1、删除conf/example/meta.dat
2、调整conf/example/instance.properties
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=0
#2019-01-01 00:00:00 上一次更新的时间
canal.instance.master.timestamp=1546272000000
3、重启deployer
另外需要注意的是如果bin log是只会记录增量操作的,也就是说开启bin log之前的历史数据是不会记录的,如果需要同步者之前的数据,解决这个问题有三个办法:
(1)通过logstash-input-jdbc来实现
(2)通过业务代码来实现(后续会详细讲解这两种方式,可以关注我后续的博客)
(3)复制原数据库数据到开启了binlog的从数据库,然后从从数据库同步
这个报错是空指针报错,很明显是哪里获取为空的,这种错误没有固定的原因,但大概率上可以锁定配置文件的问题
1、adapter的配置文件中是有包含了mysql、es、mq、zk等配置,如果不需要的配置项,就将其注释掉,不要打开
比如我这里的报错原因就是因为打开了zookeeperHosts,但是没有配置具体值,所以导致了空指针,因为我不需要zk,将其注释掉即可
# flatMessage: true
# zookeeperHosts:
2、某些必要的配置没有设置,快速排查的方式就是根据官方文档中给出的配置文件对比排错
可以参考如下配置文件
3、配置文件中配置项排版错位
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer
kafka.bootstrap.servers: 127.0.0.1:9092
kafka.enable.auto.commit: false
kafka.auto.commit.interval.ms: 1000
kafka.auto.offset.reset: latest
kafka.request.timeout.ms: 40000
kafka.session.timeout.ms: 30000
kafka.isolation.level: read_committed
kafka.max.poll.records: 1000
# rocketMQ consumer
rocketmq.namespace:
rocketmq.namesrv.addr: 127.0.0.1:9876
rocketmq.batch.size: 1000
rocketmq.enable.message.trace: false
rocketmq.customized.trace.topic:
rocketmq.access.channel:
rocketmq.subscribe.filter:
# rabbitMQ consumer
rabbitmq.host:
rabbitmq.virtual.host:
rabbitmq.username:
rabbitmq.password:
rabbitmq.resource.ownerId:
srcDataSources:
defaultDS:
url: jdbc:mysql://172.16.188.1:3306/bladex?useUnicode=true
#driverClassName: com.mysql.cj.jdbc.Driver
username: root
password: 123456
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
-
key: esKey
name: es7 # es6 or es7
hosts: http://172.16.188.7:9200 # 集群地址,逗号隔开. 127.0.0.1:9200 for rest mode or 127.0.0.1:9300 for transport mode
properties:
mode: rest # rest or transport
# security.auth: test:123456 # only used for rest mode
cluster.name: cluster1
Field error in object 'target' on field 'esMapping': rejected value []; codes
[typeMismatch.target.esMapping,typeMismatch.esMapping,typeMismatch.com.alibaba.otter.canal.client.adapter.es.core.config.ESSyncConfig$ESMapping,typeMismatch];
arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [target.esMapping,esMapping]; arguments []; default message [esMapping]]; default message [Failed to convert property value of type 'java.lang.String' to required type
'com.alibaba.otter.canal.client.adapter.es.core.config.ESSyncConfig$ESMapping' for property 'esMapping'; nested
exception is java.lang.IllegalStateException: Cannot convert value of type 'java.lang.String' to required type
'com.alibaba.otter.canal.client.adapter.es.core.config.ESSyncConfig$ESMapping' for property 'esMapping': no
matching editors or conversion strategy found]
这是配置文件问题,检查es下的配置yml文件,特别是sql语句的语法是否有问题
没有找到对应字段导致
检查下canal配置文件中的字段是否在es mapping中有对应的,大小写是否一致,是否有遗漏
因为我的操作是mysql同步至es,所以这里说明几项容易出错的地方:
1、canal配置文件中的sql中是否大小写一致,canal是区分大小写的
2、sql中设置的别名是否与es mappings中的名称一致,允许es中的部分字段为空,但是不允许sql中查询出来的字段在es mappings中找不到对应的字段
3、canal配置文件中的dataSourceKey是否正确,其对应到canal application.yml配置文件中的数据库是否正确
dataSourceKey: aaa
application.yml
srcDataSources:
aaa: # 与之对应
url: jdbc:mysql://192.168.244.1:3306/aaa?useUnicode=true
#driverClassName: com.mysql.cj.jdbc.Driver
username: root
password: 123456
xxx:
url: jdbc:mysql://192.168.244.1:3306/xxx?useUnicode=true
username: root
password: 123456
yyy:
url: jdbc:mysql://192.168.244.1:3306/yyy?useUnicode=true
username: root
password: 123456
4、canal配置文件中的排版是否正确,特别注意_index,_type等属性要放在esMappings下
dataSourceKey: aaa # 这里的key与上述application.yml中配置的数据源保持一致
outerAdapterKey: esKey # 与上述application.yml中配置的outerAdapters.key一直
destination: example # 默认为example,与application.yml中配置的instance保持一致
groupId:
esMapping:
_index: dept
_type: _doc
_id: _id
sql: "select
t.id,
t.id as _id,
t.dept_name as deptName,
t.dept_category as deptCategory,
t.parent_id as parentId,
t.ancestors as ancestors,
t.third_party_id as thirdPartyId,
t.phone as phone,
t.address as address,
t.is_deleted as isDeleted
from
dept t"
#etlCondition: "where t.update_time>='{0}'"
commitBatch: 3000
5、sql查询出来的字段类型与es mappings中的字段数据类型是否一致
6、多表同步到同一个索引时,如果都有同一个常量列且值不同时会报错。
如下所示的两个配置文件都有userSource常量列用于区分不同的数据来源,但是如下的配置会报错。
xxx.yml
dataSourceKey: aaa # 这里的key与上述application.yml中配置的数据源保持一致
outerAdapterKey: esKey # 与上述application.yml中配置的outerAdapters.key一直
destination: example # 默认为example,与application.yml中配置的instance保持一致
groupId:
esMapping:
_index: user
_type: _doc
_id: _id
sql: "select
t.id,
0 as userSource,
from
user t"
commitBatch: 3000
yyy.yml
dataSourceKey: aaa # 这里的key与上述application.yml中配置的数据源保持一致
outerAdapterKey: esKey # 与上述application.yml中配置的outerAdapters.key一直
destination: example # 默认为example,与application.yml中配置的instance保持一致
groupId:
esMapping:
_index: user
_type: _doc
_id: _id
sql: "select
t.id,
1 as userSource,
from
user_wx t"
commitBatch: 3000
adapter日志中没有报错信息,于是去查看deployer日志,这里的example是你配置的实例
cat logs/example/example.log
会发现报错:
Could not find first log file name in binary log index file
解决:
1、既然问题是没有找到数据库的binglog文件位置,那么就查看一下现在的binlog文件位置,登陆mysql执行
2.1 如果你是做增量同步,那么查询当前binlog位置
show master status;
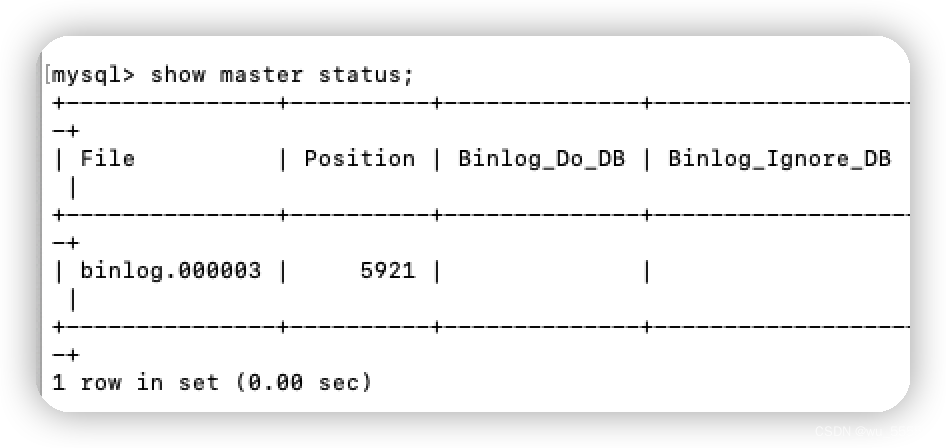
修改conf/example/instance.properties文件
canal.instance.master.address=192.168.244.17:3306
# 这里的文件名要与上面的保持一致,我这里就是文件名不一致,写成了mysql-bin.000001
canal.instance.master.journal.name=binlog.000003
canal.instance.master.position=5921
canal.instance.master.timestamp=
canal.instance.master.gtid=
2.2 如果你要做全量同步,查询binlog文件
show binary logs;
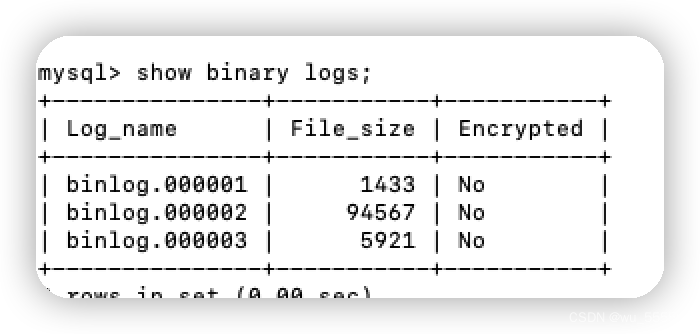
canal.instance.master.address=192.168.244.17:3306
# 这里的文件名要与上面的保持一致,我这里就是文件名不一致,写成了mysql-bin.000001
canal.instance.master.journal.name=binlog.000001
# 位置从0开始
canal.instance.master.position=0
canal.instance.master.timestamp=
canal.instance.master.gtid=
3、重启deployer和adapter
启动adapter报错:
2022-05-21 06:28:44.444 [pool-2-thread-1] ERROR c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - java.lang.NullPointerException
java.lang.RuntimeException: java.lang.NullPointerException
at com.alibaba.otter.canal.client.adapter.es.core.service.ESSyncService.sync(ESSyncService.java:116) ~[na:na]
at com.alibaba.otter.canal.client.adapter.es.core.service.ESSyncService.sync(ESSyncService.java:64) ~[na:na]
at com.alibaba.otter.canal.client.adapter.es.core.ESAdapter.sync(ESAdapter.java:115) ~[na:na]
at com.alibaba.otter.canal.client.adapter.es.core.ESAdapter.sync(ESAdapter.java:94) ~[na:na]
at com.alibaba.otter.canal.adapter.launcher.loader.AdapterProcessor.batchSync(AdapterProcessor.java:139) ~[client-adapter.launcher-1.1.5.jar:na]
at com.alibaba.otter.canal.adapter.launcher.loader.AdapterProcessor.lambda$null$1(AdapterProcessor.java:97) ~[client-adapter.launcher-1.1.5.jar:na]
at java.util.concurrent.CopyOnWriteArrayList.forEach(CopyOnWriteArrayList.java:895) ~[na:1.8.0_312]
at com.alibaba.otter.canal.adapter.launcher.loader.AdapterProcessor.lambda$null$2(AdapterProcessor.java:94) ~[client-adapter.launcher-1.1.5.jar:na]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[na:1.8.0_312]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[na:1.8.0_312]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[na:1.8.0_312]
at java.lang.Thread.run(Thread.java:748) ~[na:1.8.0_312]
Caused by: java.lang.NullPointerException: null
at com.alibaba.otter.canal.client.adapter.es7x.support.ES7xTemplate.insert(ES7xTemplate.java:79) ~[na:na]
at com.alibaba.otter.canal.client.adapter.es.core.service.ESSyncService.singleTableSimpleFiledInsert(ESSyncService.java:448) ~[na:na]
at com.alibaba.otter.canal.client.adapter.es.core.service.ESSyncService.insert(ESSyncService.java:139) ~[na:na]
at com.alibaba.otter.canal.client.adapter.es.core.service.ESSyncService.sync(ESSyncService.java:99) ~[na:na]
... 11 common frames omitted
2022-05-21 06:28:44.449 [Thread-4] ERROR c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - Outer adapter sync failed! Error sync but ACK!
解决:
1、修改adapter/application.yml,给outerAdapters配置一个key,注意这里如果有多个adapter实例,那么就配置不同的key
canalAdapters:
- instance: test # canal instance Name or mq topic name
groups:
- groupId: g2
outerAdapters:
# - name: logger
-
key: esKey3 # 配置key
name: es7 # es6 or es7
#hosts: http://192.168.101.11:9200 # 集群地址,逗号隔开. 127.0.0.1:9200 for rest mode or 127.0.0.1:9300 for transport mode
hosts: http://192.168.244.11:9200 # 集群地址,逗号隔开. 127.0.0.1:9200 for rest mode or 127.0.0.1:9300 for transport mode
properties:
mode: rest # rest or transport
security.auth: elastic:elastic # only used for rest mode
cluster.name: blade-cluster
deployser日志报错:
2022-05-21 07:45:15.651 [MultiStageCoprocessor-Parser-fleet-0] ERROR com.alibaba.otter.canal.common.utils.NamedThreadFactory - from MultiStageCoprocessor-Parser-fleet-0
com.alibaba.otter.canal.parse.exception.CanalParseException: com.alibaba.otter.canal.parse.exception.CanalParseException: com.alibaba.otter.canal.parse.exception.CanalParseException: parse row data failed.
Caused by: com.alibaba.otter.canal.parse.exception.CanalParseException: com.alibaba.otter.canal.parse.exception.CanalParseException: parse row data failed.
Caused by: com.alibaba.otter.canal.parse.exception.CanalParseException: parse row data failed.
Caused by: com.alibaba.otter.canal.parse.exception.CanalParseException: column size is not match for table:fleet.source_project_cargo,9 vs 8
解决:
1、可以看到报错中已经给出明确提示了
column size is not match for table:fleet.source_project_cargo,9 vs 8
2、该错误官方中有解释
官方文档 TableMetaTSDB
在instance.properties中设置
canal.instance.tsdb.spring.xml=classpath:spring/tsdb/h2-tsdb.xml
# table meta tsdb info
canal.instance.tsdb.enable=true
# 以下配置不用开启,因为在canal.properties中已经设置过了,只要没有手动关闭过就不用再配置了
#canal.instance.tsdb.dir=${canal.file.data.dir:../conf}/${canal.instance.destination:}
#canal.instance.tsdb.url=jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
3、一般将这个开启就解决了,但是我这里即时将其开启还是报错,查阅相关资料有说将canal.instance.tsdb.enable设置为false后重启解决的,但是我这里将其设置为false后依旧没有解决
实在没有其他办法了,查阅官方github,导致这个问题发生的原因是因为表结构发生过变化,但是binlog中读取到的与现在的表结构不一致导致。
于是直接跳过该binlog checkpoint,也就是将binlog的读取位置设置为当前的最新binlog位置
(1)查阅当前binlog最新位置,mysql中执行
show master status;
(2)将读取位置该为最新,修改deployer conf/example/instance.properties
canal.instance.master.address=162.14.99.4:3306
canal.instance.master.journal.name=mysql-bin.000002
canal.instance.master.position=226586328
# 当前时间的时间戳形式
canal.instance.master.timestamp=1653140932
canal.instance.master.gtid=
(3)重启deployer , adapter
(4)因为读取的是最新的binlog。为了把当前的数据同步进来,将需要同步的表或库导出,然后再导入一遍。问题解决(注意:这里的解决方案要谨慎,生产环境因为时时刻刻在产生数据,可行性很低,所以看要么设置一个停机维护来进行实操)
在instance.properties中设置时间戳
canal.instance.master.timestamp=1546272000000
该错误是因为sql中使用了group_concat函数,但是该函数默认长度是1024,超过的会被截取,导致出现了json格式的数据格式不正确,没有正确的关闭json
解决:
1、修改my.cnf,扩大group_concat_max_len
group_concat_max_len = 102400
2、重启mysql
sql中没有_id字段导致,使用as将id命名别名:select id as _id
我这里出现这个问题是在canal1.1.6版本中,原因是es7文件夹中的.yml文件中书写的sql里使用了``将表名括起来,导致未识别,如下所示
select id,name,age from `user`
解决:
将``去掉即可
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf