国外博士论文可去ProQuest学位论文全文数据库查找下载,ProQuest学位论文全文数据库是将ProQuest公司PQDD文摘库(现名PQDT)中适合中国科研人员科研和教学使用的论文全文建设而成,并向全国百数家科研教学单位的读者提供全文服务。是目前国内最完备、高质量、唯一的可以综合查询国外学位论文全文的数据库。
ProQuest学位论文全文数据库覆盖了大部分北美地区高等院校以及世界其他地区数千个高等院校每年获得通过的博硕士论文。Harvard University、Massachusetts Institue of Technology、Cambridge University、Stanford University、 Hong Kong University of Science and Technology等知名院校每年都有大量论文被收录。
ProQuest学位论文全文数据库是一个覆盖学科范围十分全面的数据库,包含了自然科学、社会科学和生命科学在内的11个大的学科,下辖31个一级学科和268个二级学科,每年更新最新获得学科的优秀博硕士论文。
校外在ProQuest数据库下载博士论文过程:
一、首先在文献党下载器首页(wxdown.org)下载客户端,登录客户端进入资源库,在资源库双击“ProQuest”名称即可进入该数据库:

二、进入 ProQuest数据库首页,输入关键词检索,如果查找博士论文可勾选“仅博士论文”:

三、也可点击首页的高级检索,添加检索条件检索:
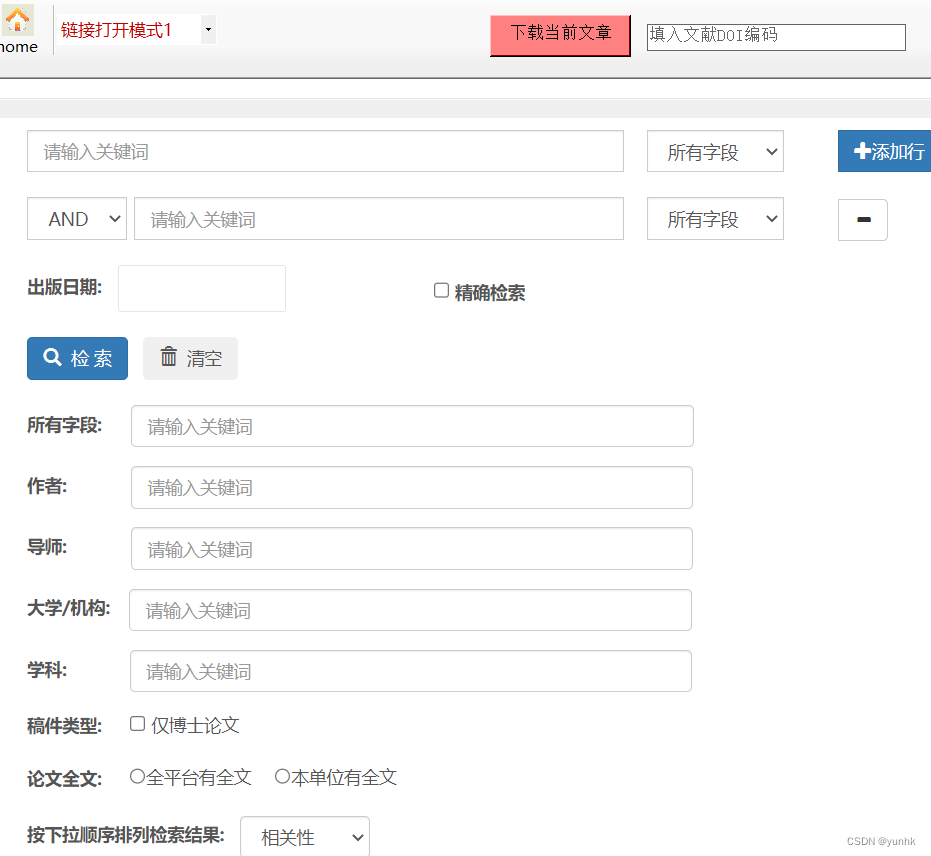
四、举例,输入关键词检索到相关文献,可以在左侧筛选栏选择自己需要的选项,如:文献类型、年份、作者、机构、语言等进行二次筛选:
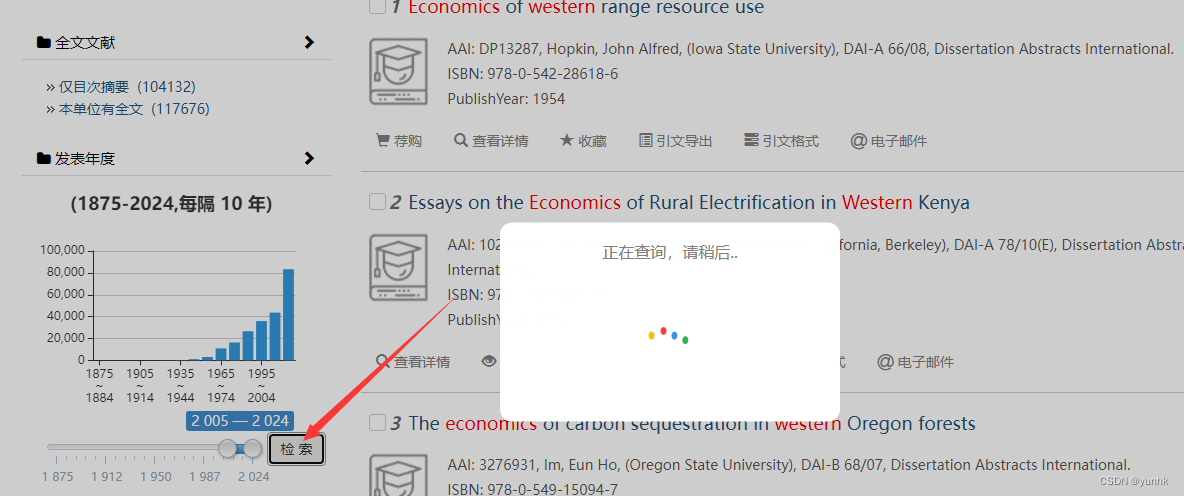
五、检索到自己需要的文献,点击下方的“查看PDF”:

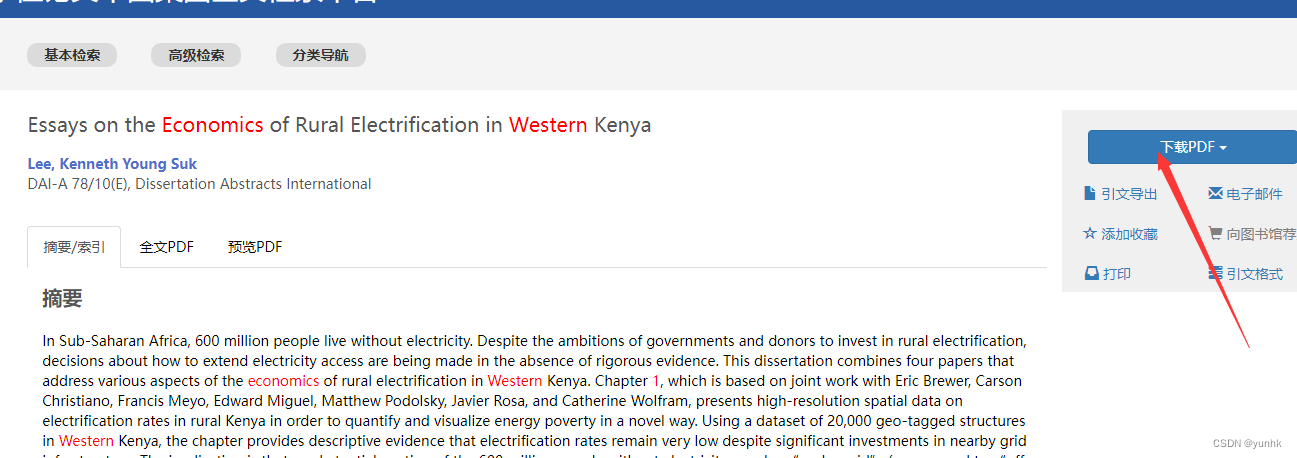
六、转下页,点击“下载PDF”键完成下载全文:
七、一篇国外的博士论文下载好了,如果你还需要其他外文文献数据库的文献资源如:Springer、EI(工程索引 )、Elsevier(sciencedirect)、Web of Science、Wiley、PubMed 、IEEE等等,都可用这个途径下载文献。
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
我想找到给定字符串中的所有匹配项,包括重叠匹配项。我怎样才能实现它?#Example"a-b-c-d".???(/\w-\w/)#=>["a-b","b-c","c-d"]expected#Solutionwithoutoverlappedresults"a-b-c-d".scan(/\w-\w/)#=>["a-b","c-d"],but"b-c"ismissing 最佳答案 在积极的前瞻中使用捕获:"a-b-c-d".scan(/(?=(\w-\w))/).flatten#=>["a-b","b-c","c-d"]参见Rubyde
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
这应该是一个简单的问题,但我找不到任何相关信息。给定一个Ruby中的正则表达式,对于每个匹配项,我需要检索匹配的模式$1、$2,但我还需要匹配位置。我知道=~运算符为我提供了第一个匹配项的位置,而string.scan(/regex/)为我提供了所有匹配模式。如果可能,我需要在同一步骤中获得两个结果。 最佳答案 MatchDatastring.scan(regex)do$1#Patternatfirstposition$2#Patternatsecondposition$~.offset(1)#Startingandendingpo