实验表明,RNN 在几乎所有的序列问题上都有良好表现,包括语音/文本识别、机器翻译、手写体识别、序列数据分析(预测)等。
在实际应用中,RNN 在内部设计上存在一个严重的问题:由于网络一次只能处理一个时间步长,后一步必须等前一步处理完才能进行运算。这意味着 RNN 不能像 CNN 那样进行大规模并行处理,特别是在 RNN/LSTM 对文本进行双向处理时。这也意味着 RNN 极度地计算密集,因为在整个任务运行完成之前,必须保存所有的中间结果。
CNN 在处理图像时,将图像看作一个二维的“块”(m*n 的矩阵)。迁移到时间序列上,就可以将序列看作一个一维对象(1*n 的向量)。通过多层网络结构,可以获得足够大的感受野。这种做法会让 CNN 非常深,但是得益于大规模并行处理的优势,无论网络多深,都可以进行并行处理,节省大量时间。这就是 TCN 的基本思想。
LightRNN:高效利用内存和计算的循环神经网络_曼陀罗彼岸花的博客-CSDN博客
将RNN内存占用缩小90%:多伦多大学提出可逆循环神经网络:将RNN内存占用缩小90%:多伦多大学提出可逆循环神经网络 - 知乎

循环神经网络(RNN)在处理序列数据方面取得了当前最佳的性能表现,但训练时需要大量内存,需要存储隐藏状态。
最近,循环神经网络(RNN)已被用于处理多种自然语言处理(NLP)任务,例如语言建模、机器翻译、情绪分析和问答。有一种流行的 RNN 架构是长短期记忆网络(LSTM),其可以通过记忆单元(memory cell)和门函数(gating function)建模长期依赖性和解决梯度消失问题。因为这些元素,LSTM 循环神经网络在当前许多自然语言处理任务中都实现了最佳的表现,尽管它的方式几乎是从头开始学习。
虽然 RNN 越来越受欢迎,但它也存在一个局限性:当应用于大词汇的文本语料库时,模型的体量将变得非常大。比如说,当使用 RNN 进行语言建模时,词首先需要通过输入嵌入矩阵(input-embedding matrix)从 one-hot 向量(其维度与词汇尺寸相同)映射到嵌入向量。然后为了预测下一词的概率,通过输出嵌入矩阵(output-embedding matrix)将顶部隐藏层投射成词汇表中所有词的概率分布。当该词汇库包含数千万个不同的词时(这在 Web 语料库中很常见),这两个嵌入矩阵就会包含数百亿个不同的元素,这会使得 RNN 模型变得过大,从而无法装进 GPU 设备的内存。以 ClueWeb 数据集为例,其词汇集包含超过 1000 万词。如果嵌入向量具有 1024 个维度并且每个维度由 32 位浮点表示,则输入嵌入矩阵的大小将为大约 40GB。进一步考虑输出嵌入矩阵和隐藏层之间的权重,RNN 模型将大于 80GB,这一数字远远超出了市面上最好的 GPU 的能力。
即使 GPU 的内存可以扩容,用于训练这样体量模型的计算复杂度也将高到难以承受。在 RNN 语言模型中,最耗时的运算是计算词汇表中所有词的概率分布,这需要叠乘序列每个位置处的输出嵌入矩阵和隐藏状态。简单计算一下就可以知道,需要使用目前最好的单 GPU 设备计算数十年才能完成 ClueWeb 数据集语言模型的训练。此外,除了训练阶段的难题,即使我们最终训练出了这样的模型,我们也几乎不可能将其装进移动设备让它进入应用。
到目前为止,深度学习背景下的序列建模主题主要与递归神经网络架构(如LSTM和GRU)有关。S. Bai等人(*)认为,这种思维方式已经过时,在对序列数据进行建模时,应该将卷积网络作为主要候选者之一加以考虑。他们能够表明,在许多任务中,卷积网络可以取得比RNNs更好的性能,同时避免了递归模型的常见缺陷,如梯度爆炸/消失问题或缺乏内存保留。此外,使用卷积网络而不是递归网络可以提高性能,因为它允许并行计算输出。他们提出的架构称为时间卷积网络(TCN),将在下面的部分中进行解释。
TCN是指时间卷积网络,一种新型的可以用来解决时间序列预测的算法。
该算法于2016年由Lea等人首先提出,当时他们在做视频动作分割的研究,一般而言此常规过程包括两个步骤:首先,使用(通常)对时空信息进行编码的CNN来计算低级特征,其次,将这些低级特征输入到使用(通常是)捕获高级时域信息的分类器中)RNN。这种方法的主要缺点是需要两个单独的模型。
TCN提供了一种统一的方法来分层捕获所有两个级别的信息。
自从TCN提出后引起了巨大反响,有人认为:时间卷积网络(TCN)将取代RNN成为NLP或者时序预测领域的王者。
DataScienceCentral 的编辑主任William Vorhies给出的原因如下:
RNN耗时太长,由于网络一次只读取、解析输入文本中的一个单词(或字符),深度神经网络必须等前一个单词处理完,才能进行下一个单词的处理。这意味着 RNN 不能像 CNN 那样进行大规模并行处理;并且TCN的实际结果也要优于RNN算法。
TCN可以采用一系列任意长度并将其输出为相同长度。在使用一维完全卷积网络体系结构的情况下,使用因果卷积。一个关键特征是,时间t的输出仅与t之前发生的元素卷积。
TCN 模型以 CNN 模型为基础,并做了如下改进:
下面将分别介绍 CNN 的扩展技术。
TCN的特点:

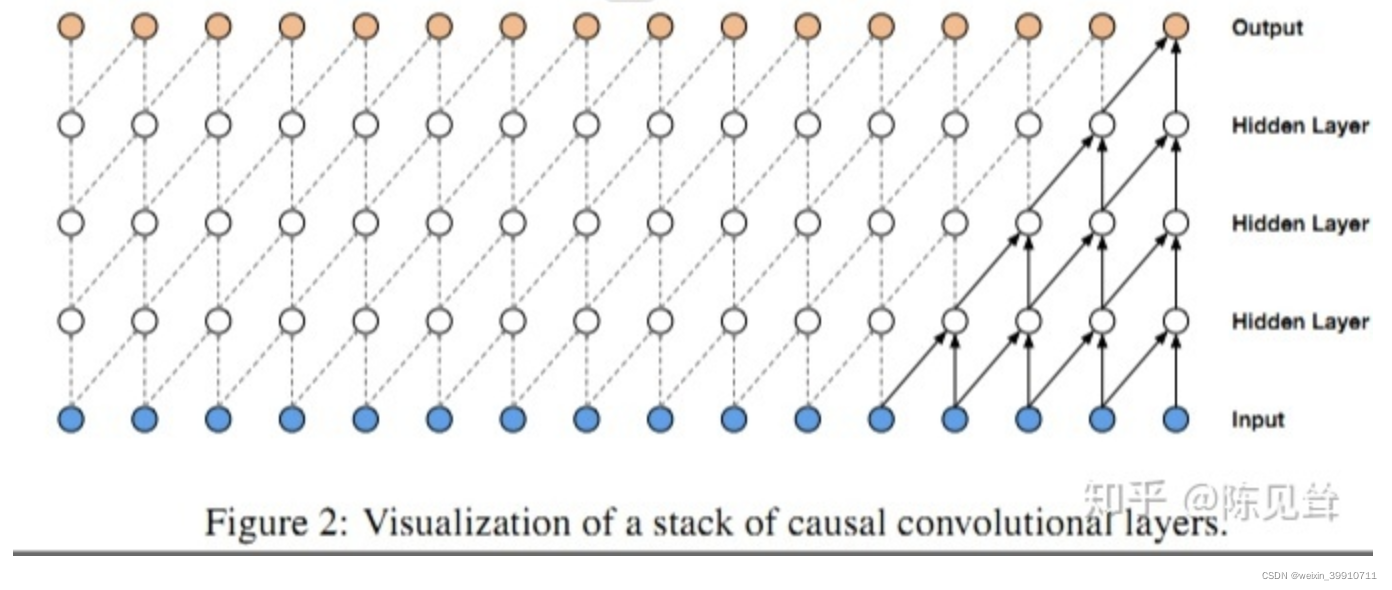
因果卷积可以用上图直观表示。 即对于上一层t时刻的值,只依赖于下一层t时刻及其之前的值。和传统的卷积神经网络的不同之处在于,因果卷积不能看到未来的数据,它是单向的结构,不是双向的。也就是说只有有了前面的因才有后面的果,是一种严格的时间约束模型,因此被成为因果卷积。
因果卷积有两个特点:
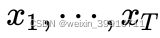 ,预测
,预测  。但是在预测
。但是在预测 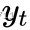 时,只能使用已经观测到的序列 ,而不能使用
时,只能使用已经观测到的序列 ,而不能使用 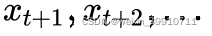 。
。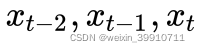 ;假设以输出层作为输出,它的最后一个节点关联了输入的五个节点。
;假设以输出层作为输出,它的最后一个节点关联了输入的五个节点。单纯的因果卷积还是存在传统卷积神经网络的问题,即对时间的建模长度受限于卷积核大小的,如果要想抓去更长的依赖关系,就需要线性的堆叠很多的层。标准的 CNN 可以通过增加 pooling 层来获得更大的感受野,而经过 pooling 层后肯定存在信息损失的问题。
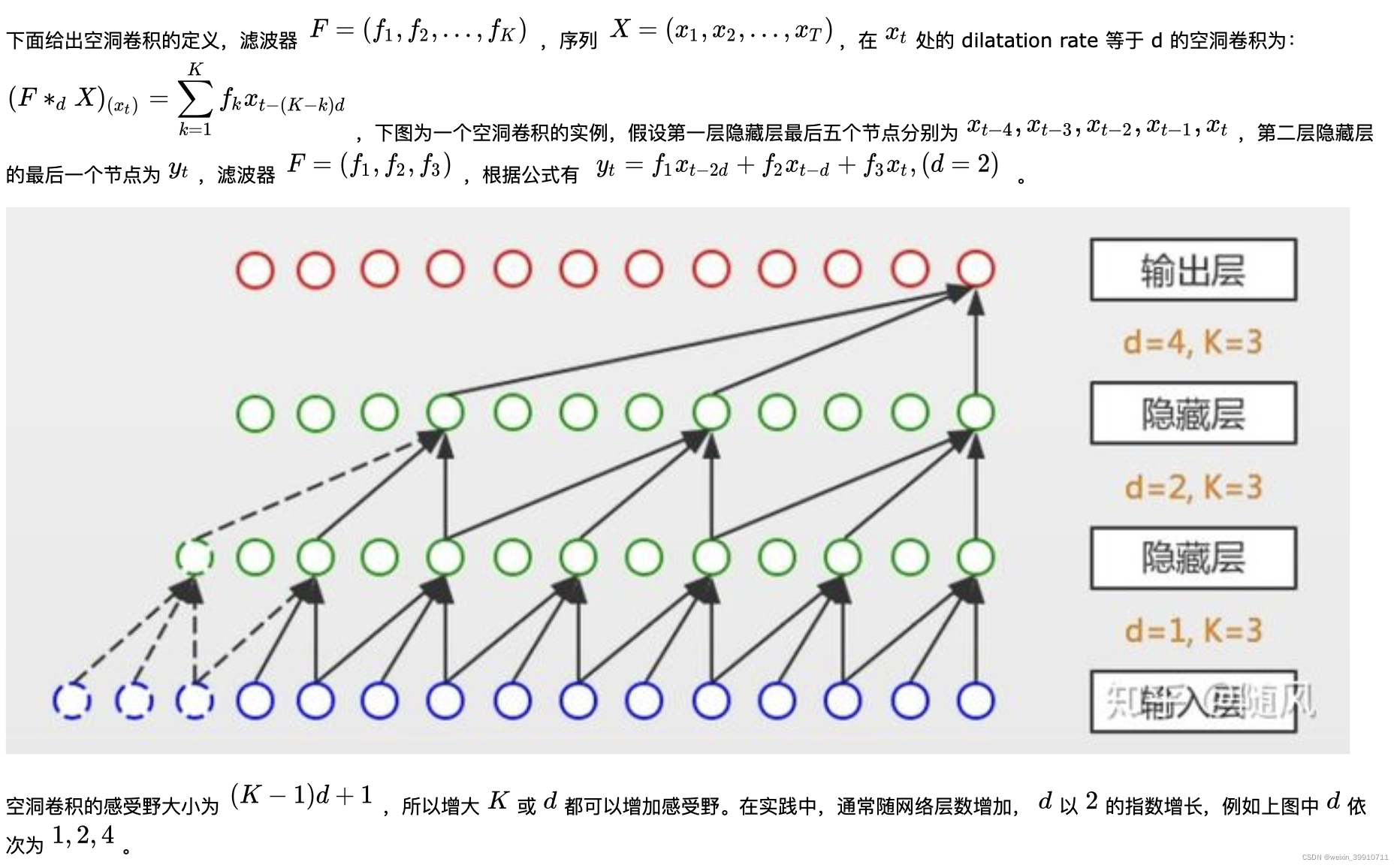
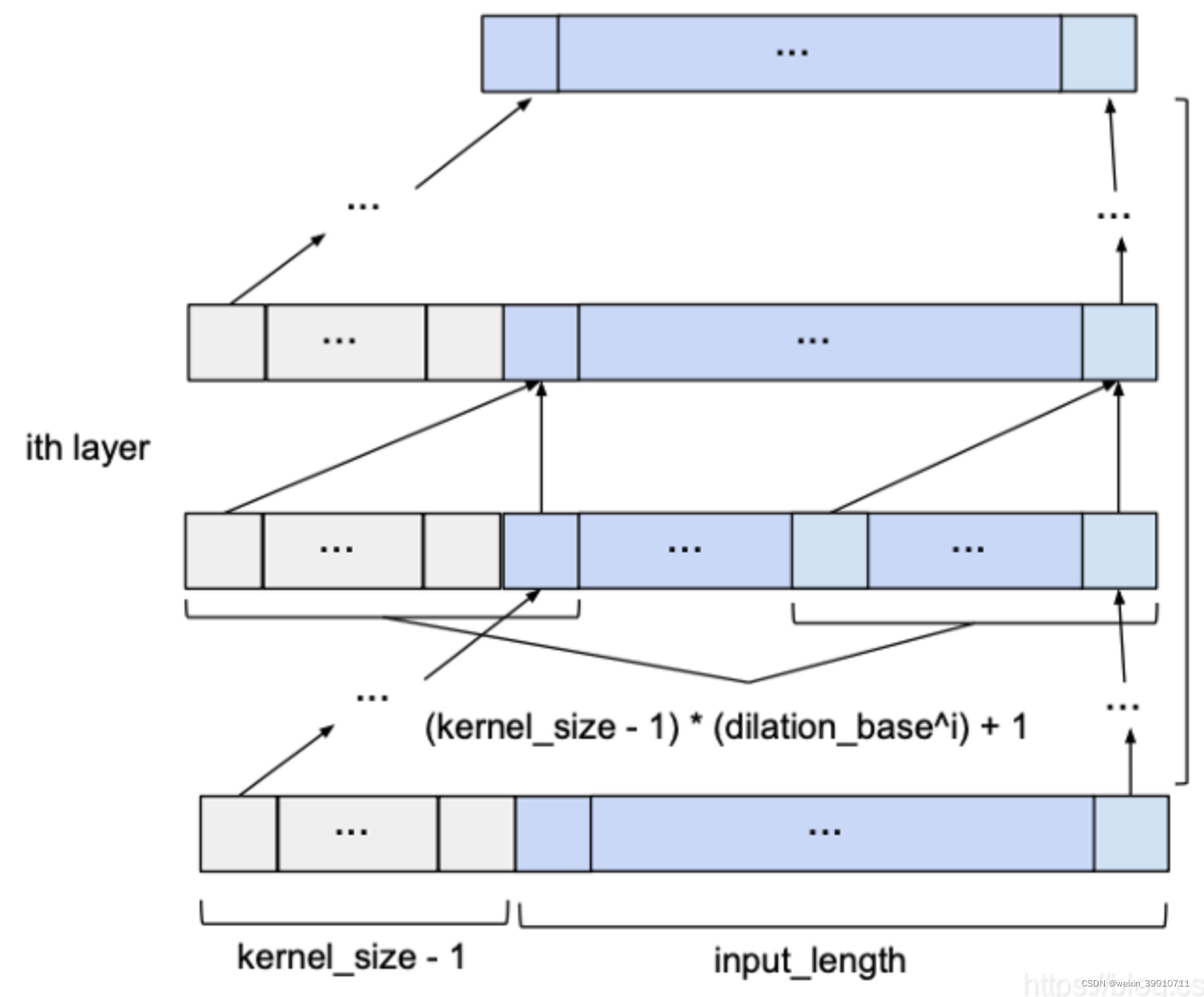
空洞卷积是在标准的卷积里注入空洞,以此来增加感受野。空洞卷积多了一个超参数 dilation rate,指的是 kernel 的间隔数量(标准的 CNN 中 dilatation rate 等于 1)。空洞的好处是不做 pooling 损失信息的情况下,增加了感受野,让每个卷积输出都包含较大范围的信息。下图展示了标准 CNN (左)和 Dilated Convolution (右),右图中的 dilatation rate 等于 2 。
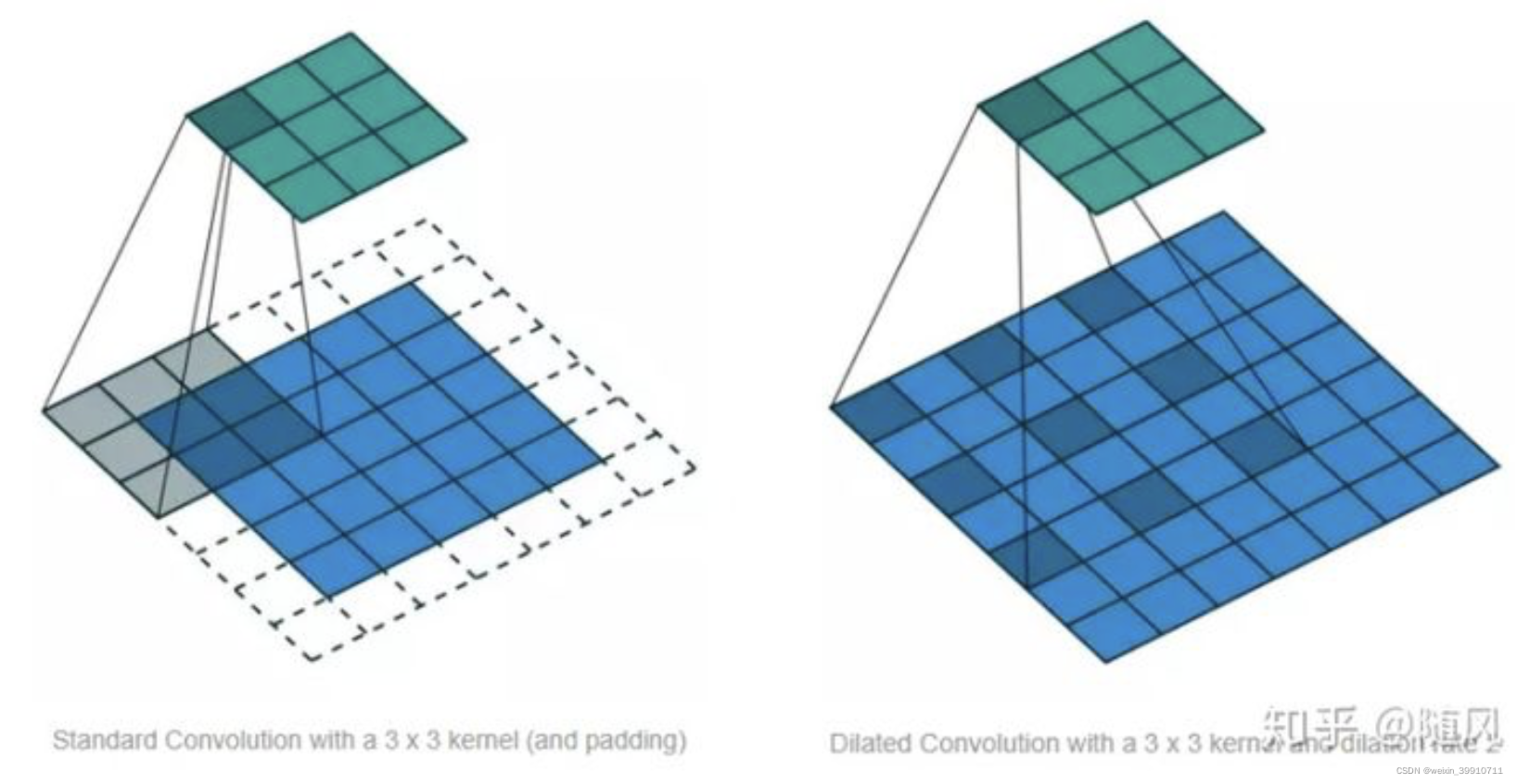
和传统卷积不同的是,膨胀卷积允许卷积时的输入存在间隔采样,采样率受图中的d控制。 最下面一层的d=1,表示输入时每个点都采样,中间层d=2,表示输入时每2个点采样一个作为输入。一般来讲,越高的层级使用的d的大小越大。所以,膨胀卷积使得有效窗口的大小随着层数呈指数型增长。这样卷积网络用比较少的层,就可以获得很大的感受野。
空洞卷积的参数:
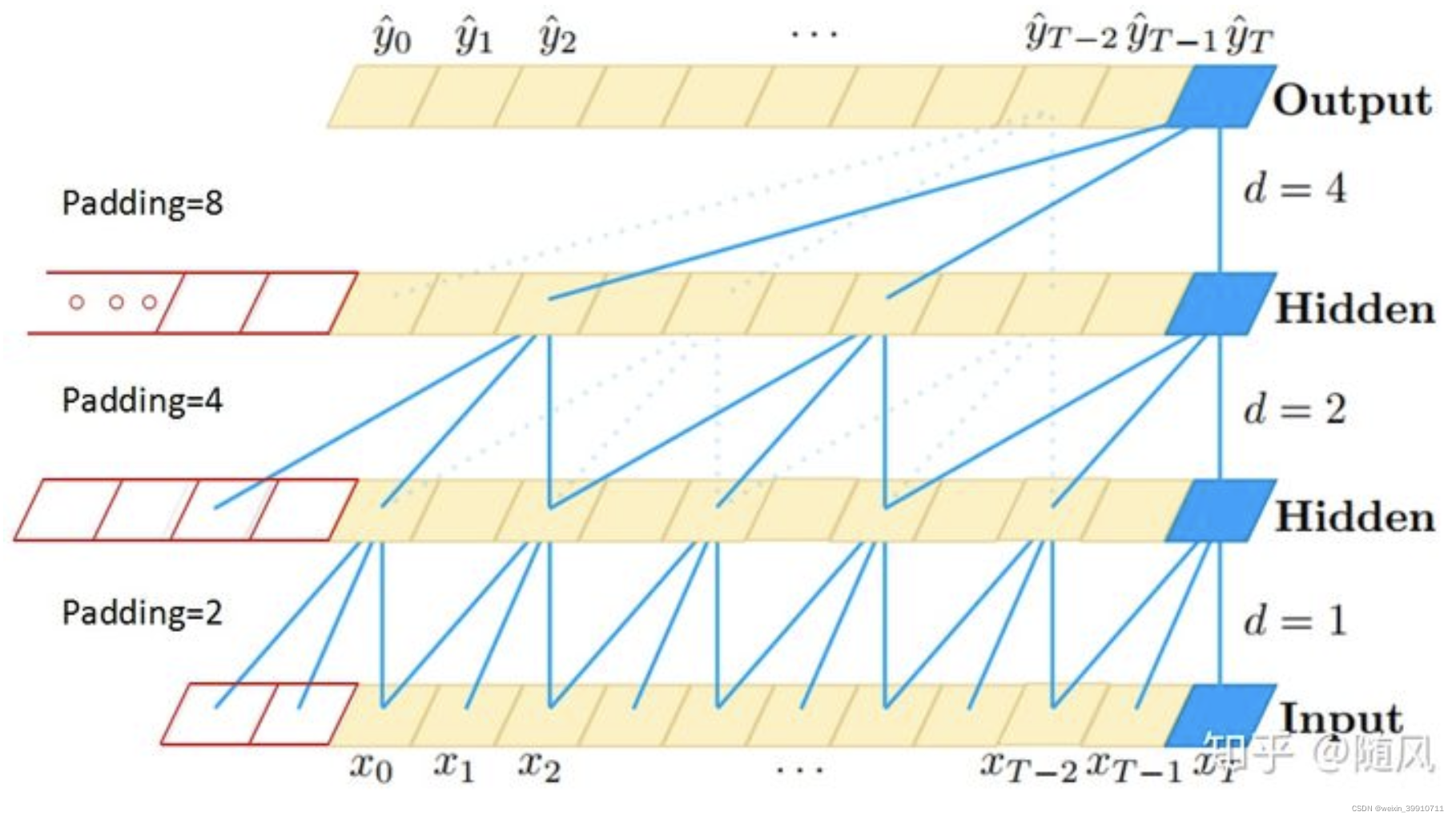
因为研究对象是时间序列,TCN 采用一维的卷积网络。上图是 TCN 架构中的因果卷积与空洞卷积,可以看到每一层 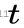 时刻的值只依赖于上一层
时刻的值只依赖于上一层 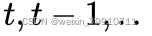 时刻的值,体现了因果卷积的特性;而每一层对上一层信息的提取,都是跳跃式的,且逐层 dilated rate 以 2 的指数增长,体现了空洞卷积的特性。由于采用了空洞卷积,因此每一层都要做 padding(通常情况下补 0),padding 的大小为
时刻的值,体现了因果卷积的特性;而每一层对上一层信息的提取,都是跳跃式的,且逐层 dilated rate 以 2 的指数增长,体现了空洞卷积的特性。由于采用了空洞卷积,因此每一层都要做 padding(通常情况下补 0),padding 的大小为 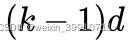 。
。
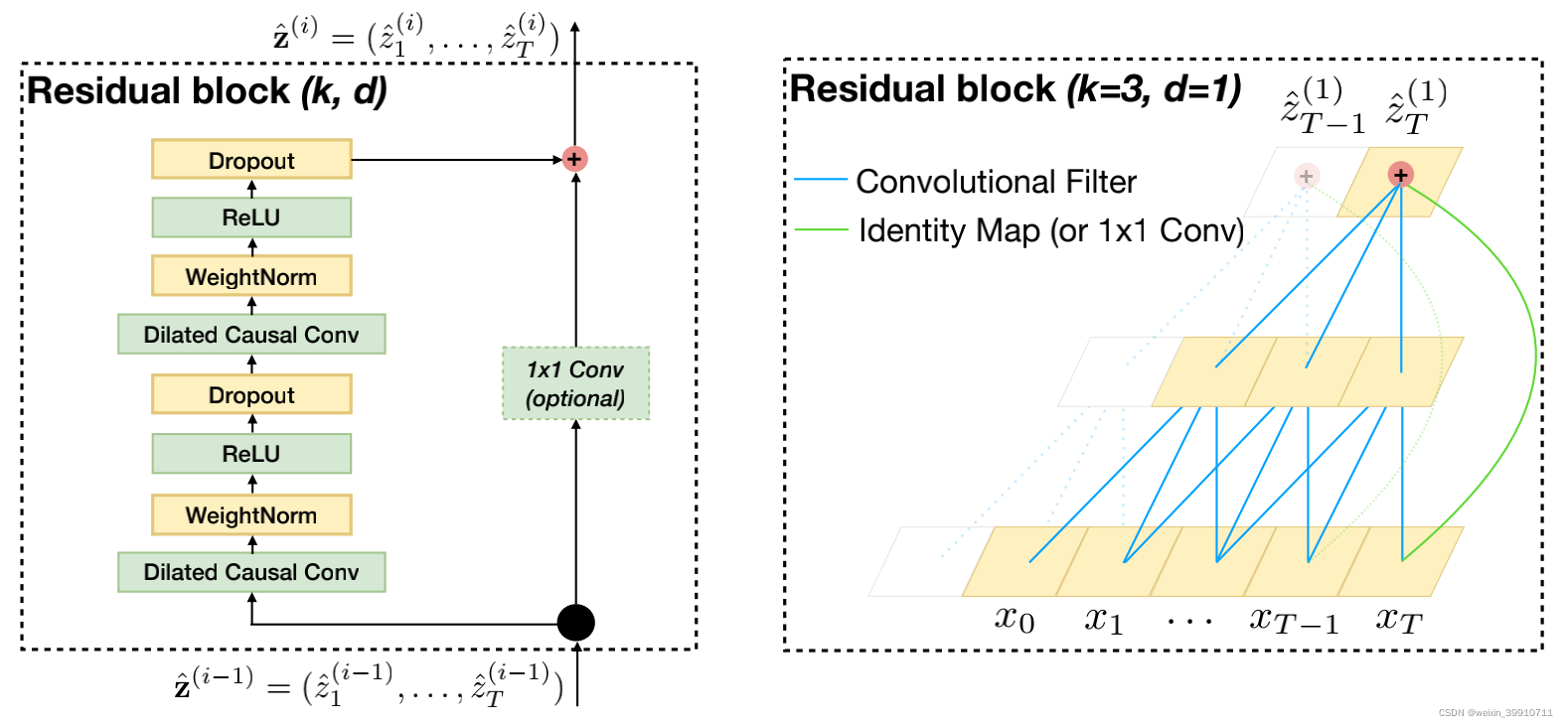
残差链接被证明是训练深层网络的有效方法,它使得网络可以以跨层的方式传递信息。本文构建了一个残差块来代替一层的卷积。如上图所示,一个残差块包含两层的卷积和非线性映射,在每层中还加入了WeightNorm和Dropout来正则化网络。
给定input_length, kernel_size, dilation_base和覆盖整个历史所需的最小层数,基本的TCN网络看起来像这样:
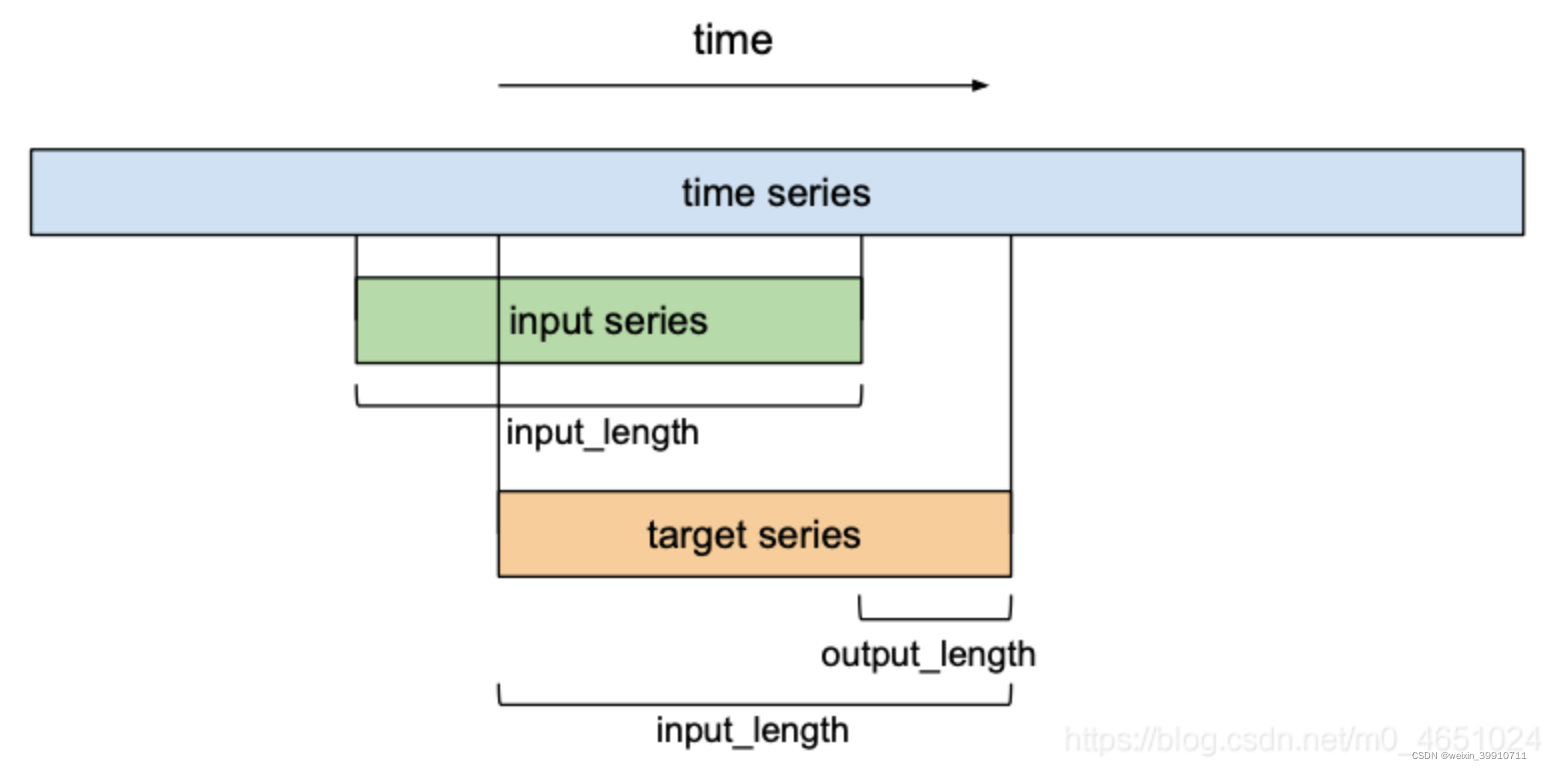
到目前为止,我们只讨论了‘输入序列’和‘输出序列’,而没有深入了解它们之间是如何相互关联的。在预测方面,我们希望预测未来时间序列的下一个条目。为了训练我们的TCN网络进行预测,训练集将由给定时间序列的等大小子序列对(输入序列、目标序列)组成。
即 input series = target series
目标序列将是相对于其各自的输入序列向右移动一定数量output_length的序列。这意味着长度input_length的目标序列包含其各自输入序列的最后(input_length - output_length)元素作为第一个元素,位于输入序列最后一个条目之后的output_length元素作为它的最后一个元素。在预测方面,这意味着该模型所能预测的最大预测视界等于output_length。使用滑动窗口的方法,许多重叠的输入和目标序列可以创建出一个时间序列。
优点:
使用 TCN 也有两个明显的缺点:
论文《An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling》:https://arxiv.org/pdf/1803.01271.pdf
TCN 时间卷积网络:TCN 时间卷积网络 - 知乎
时域卷积网络TCN详解:使用卷积进行序列建模和预测:时域卷积网络TCN详解:使用卷积进行序列建模和预测_deephub的博客-CSDN博客_tcn时间卷积网络
时空卷积网络TCN:时空卷积网络TCN - USTC丶ZCC - 博客园
Darts实现TCN(时域卷积网络): https://blog.csdn.net/liuhaikang/article/details/119704701?spm=1001.2014.3001.5501
TCN-时间卷积网络:https://blog.csdn.net/qq_27586341/article/details/90751794?utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromMachineLearnPai2~default-4.base&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromMachineLearnPai2~default-4.base
多变量时间序列、预训练模型和协变量:
我需要检查DateTime是否采用有效的ISO8601格式。喜欢:#iso8601?我检查了ruby是否有特定方法,但没有找到。目前我正在使用date.iso8601==date来检查这个。有什么好的方法吗?编辑解释我的环境,并改变问题的范围。因此,我的项目将使用jsapiFullCalendar,这就是我需要iso8601字符串格式的原因。我想知道更好或正确的方法是什么,以正确的格式将日期保存在数据库中,或者让ActiveRecord完成它们的工作并在我需要时间信息时对其进行操作。 最佳答案 我不太明白你的问题。我假设您想检查
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实
在Ruby中,以毫秒为单位获取自纪元(1970)以来的当前系统时间的正确方法是什么?我试过了Time.now.to_i,好像不是我想要的结果。我需要结果显示毫秒并且使用long类型,而不是float或double。 最佳答案 (Time.now.to_f*1000).to_iTime.now.to_f显示包含十进制数字的时间。要获得毫秒数,只需将时间乘以1000。 关于ruby-以毫秒为单位获取当前系统时间,我们在StackOverflow上找到一个类似的问题:
我想知道我应该如何着手这个项目。我需要每周向人们发送一次电子邮件。但是,这必须在每周的特定时间自动生成并发送。编码有多难?我需要知道是否有任何书籍可以提供帮助,或者你们中的任何人是否可以指导我。它必须使用rubyonrails进行编程。因此有一个网络服务和数据库集成。干杯 最佳答案 为什么这么复杂?您只需安排工作。您可以使用Delayed::Job例如。Delayed::Job让您可以使用run_at符号在特定时间安排作业,如下所示:Delayed::Job.enqueue(SendEmailJob.new(...),:run_
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案