今天在浏览代码发现前辈使用了ThreadPoolTaskExecutor,一时间有点懵,因为并不属于任何一个jdk下的线程池。后面浏览资料发现它属于Spring自带,所以根据网上博客来学习下:
首先在学习Spring自带的ThreadPoolTaskExecutor之前,我们先来回顾下老朋友:jdk下的ThreadPoolExecutor,很多人容易把这两个搞混。
这个类是JDK中的线程池类,继承自Executor, Executor 顾名思义是专门用来处理多线程相关的一个接口,所有线程相关的类都实现了这个接口,里面有一个execute()方法,用来执行线程,线程池主要提供一个线程队列,队列中保存着所有等待状态的线程。避免了创建与销毁的额外开销,提高了响应的速度。相关的继承实现类图例如ScheduledThreadPoolExecutor。
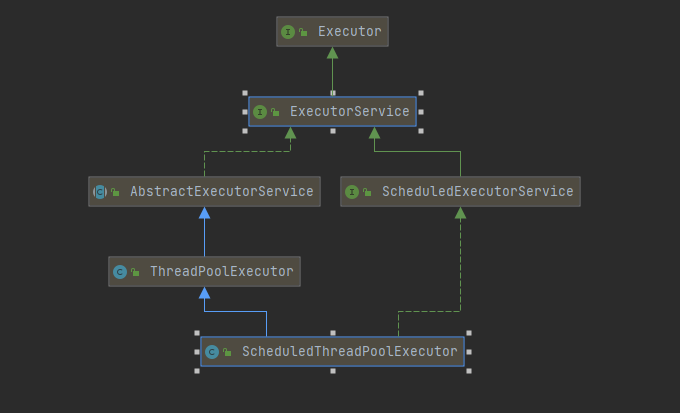
ExecutorService为线程池接口,提供了线程池生命周期方法,继承自Executor接口,ThreadPoolExecutor为线程池实现类,提供了线程池的维护操作等相关方法,继承自AbstractExecutorService,AbstractExecutorService实现了ExecutorService接口。
|--ExecutorService 子接口: 线程池的主要接口
|--ThreadPoolExecutor 线程池的实现类
|--ScheduledExceutorService 子接口: 负责线程的调度
|--ScheduledThreadPoolExecutor : 继承ThreadPoolExecutor,实现了ScheduledExecutorService
Executors为线程池工具类,相当于一个工厂类,用来创建合适的线程池,返回ExecutorService类型的线程池。有人如下方法。
ExecutorService newFixedThreadPool() : 创建固定大小的线程池
ExecutorService newCachedThreadPool() : 缓存线程池,线程池的数量不固定,可以根据需求自动的更改数量。
ExecutorService newSingleThreadExecutor() : 创建单个线程池。 线程池中只有一个线程
ScheduledExecutorService newScheduledThreadPool() : 创建固定大小的线程,可以延迟或定时的执行任务
其中AbstractExecutorService是他的抽象父类,继承自ExecutorService,ExecutorService 接口扩展Executor接口,增加了生命周期方法。
实际应用中我一般都比较喜欢使用Exectuors工厂类来创建线程池,里面有五个方法,分别创建不同的线程池,如上,创建一个制定大小的线程池,Exectuors工厂实际上就是调用的ExectuorPoolService的构造方法,传入默认参数。
public class Executors {
/**
* Creates a thread pool that reuses a fixed number of threads
* operating off a shared unbounded queue. At any point, at most
* {@code nThreads} threads will be active processing tasks.
* If additional tasks are submitted when all threads are active,
* they will wait in the queue until a thread is available.
* If any thread terminates due to a failure during execution
* prior to shutdown, a new one will take its place if needed to
* execute subsequent tasks. The threads in the pool will exist
* until it is explicitly {@link ExecutorService#shutdown shutdown}.
*
* @param nThreads the number of threads in the pool
* @return the newly created thread pool
* @throws IllegalArgumentException if {@code nThreads <= 0}
*/
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
/**
* Creates a thread pool that maintains enough threads to support
* the given parallelism level, and may use multiple queues to
* reduce contention. The parallelism level corresponds to the
* maximum number of threads actively engaged in, or available to
* engage in, task processing. The actual number of threads may
* grow and shrink dynamically. A work-stealing pool makes no
* guarantees about the order in which submitted tasks are
* executed.
*
* @param parallelism the targeted parallelism level
* @return the newly created thread pool
* @throws IllegalArgumentException if {@code parallelism <= 0}
* @since 1.8
*/
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
当然,例如阿里的规范。是不允许直接使用Executors去创建线程池的,我们可以使用ThreadPoolExecutor
package com.mbw.design_rule.figure;
import java.util.concurrent.*;
public class ThreadDemo {
public static void main(String[] args) {
ExecutorService es = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(10), Executors.defaultThreadFactory(), new ThreadPoolExecutor.DiscardPolicy());
}
}
首先是静态方法newSingleThreadExecutor()、newFixedThreadPool(int nThreads)、newCachedThreadPool()。我们来看一下其源码实现(基于JDK8)。
public class Executors {
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
}
通过查看源码我们知道上述三种静态方法的内部实现均使用了ThreadPoolExecutor类。难怪阿里会建议通过ThreadPoolExecutor的方式实现,原来Executors类的静态方法也是用的它,只不过帮我们配了一些参数而已。
第二是ThreadPoolExecutor类的构造方法。既然现在要直接使用ThreadPoolExecutor类了,那么其中的初始化参数就要我们自己配了,了解其构造方法势在必行。
ThreadPoolExecutor类一共有四个构造方法,我们只需要了解之中的一个就可以了,因为其他三种构造方法只是帮我们配置了一些默认参数,最后还是调用了它。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {}
其中的参数含义是:
corePoolSize:线程池中的线程数量;
maximumPoolSize:线程池中的最大线程数量;
keepAliveTime:当线程池线程数量超过corePoolSize时,多余的空闲线程会在多长时间内被销毁;
unit:keepAliveTime的时间单位;
workQueue:任务队列,被提交但是尚未被执行的任务;
threadFactory:线程工厂,用于创建线程,一般情况下使用默认的,即Executors类的静态方法defaultThreadFactory();handler:拒绝策略。当任务太多来不及处理时,如何拒绝任务。
对于这些参数要有以下了解:
首先corePoolSize肯定是 <= maximumPoolSize。
其他关系如下:
若当前线程池中线程数 < corePoolSize,则每来一个任务就创建一个线程去执行;
若当前线程池中线程数 >= corePoolSize,会尝试将任务添加到任务队列。如果添加成功,则任务会等待空闲线程将其取出并执行;
若队列已满,且当前线程池中线程数 < maximumPoolSize,创建新的线程,这类线程又叫救急线程;
若当前线程池中线程数 >= maximumPoolSize,则会采用拒绝策略(JDK提供了四种,下面会介绍到)。
注意:关系3是针对的有界队列,无界队列永远都不会满,所以只有前2种关系。
参数workQueue是指提交但未执行的任务队列。若当前线程池中线程数>=corePoolSize时,就会尝试将任务添加到任务队列中。主要有以下几种:
JDK内置了四种拒绝策略
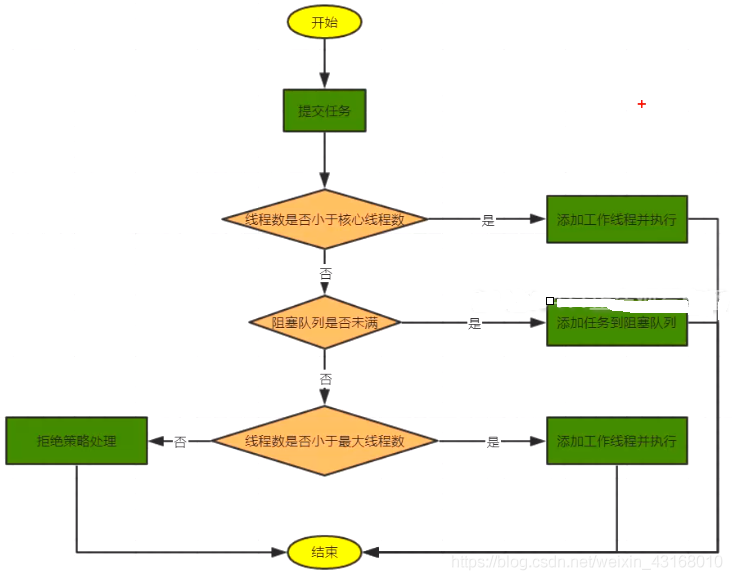
1.查看核心线程池是否已满,不满就创建一条线程执行任务,否则执行第二步。
2.查看任务队列是否已满,不满就将任务存储在任务队列中,否则执行第三步。
3.查看线程池是否已满,即就是是否达到最大线程池数,不满就创建一条线程执行任务,否则就按照策略处理无法执行的任务。
流程图如下
上一篇分享了JDK自带的线程池ThreadPoolExecutor的配置和参数详解,然而我们实际开发中更多的是使用SpringBoot来开发,Spring默认也是自带了一个线程池方便我们开发,它就是ThreadPoolTaskExecutor,ThreadPoolTaskExecutor是对ThreadPoolExecutor进行了封装处理。接下来我们就来聊聊Spring的线程池吧。
在聊spring线程池之前,首先需要了解一个注解–@Async,当一个方法标上该注解时,在被调用的时候会开启一个新的线程开始异步操作,即用于异步处理。
在SpringBoot环境中,要使用@Async注解,我们需要先在启动类上加上@EnableAsync注解。这个与在SpringBoot中使用@Scheduled注解需要在启动类中加上@EnableScheduling是一样的道理。加上@EnableAsync注解后,如果我们想在调用一个方法的时候开启一个新的线程开始异步操作,我们只需要在这个方法上加上@Async注解,当然前提是,这个方法所在的类必须在Spring环境中。
如果对@Async底层感兴趣可以去浏览https://blog.csdn.net/BryantLmm/article/details/85129372
我们可以使用springBoot默认的线程池,不过一般我们会自定义线程池(因为比较灵活),配置方式有:
package com.mbw.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
@Configuration
@EnableAsync
public class ThreadPoolTaskConfig {
/** 核心线程数(默认线程数) */
private static final int CORE_POOL_SIZE = 20;
/** 最大线程数 */
private static final int MAX_POOL_SIZE = 100;
/** 允许线程空闲时间(单位:默认为秒) */
private static final int KEEP_ALIVE_TIME = 10;
/** 缓冲队列大小 */
private static final int QUEUE_CAPACITY = 200;
/** 线程池名前缀 */
private static final String THREAD_NAME_PREFIX = "mbw-Async-";
@Bean("taskExecutor") // bean的名称,默认为首字母小写的方法名
public ThreadPoolTaskExecutor taskExecutor(){
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(CORE_POOL_SIZE);
executor.setMaxPoolSize(MAX_POOL_SIZE);
executor.setQueueCapacity(QUEUE_CAPACITY);
executor.setKeepAliveSeconds(KEEP_ALIVE_TIME);
executor.setThreadNamePrefix(THREAD_NAME_PREFIX);
// 线程池对拒绝任务的处理策略
// CallerRunsPolicy:由调用线程(提交任务的线程)处理该任务
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 初始化
executor.initialize();
return executor;
}
}
样就会申明一个线程池Bean
在使用多线程方法上标注@Async时表明调用的线程池,如下
注意:该类一定要处于spring环境中
package com.mbw.design_rule;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Component;
@Component
@Slf4j
public class AsyncTask {
@Async("taskExecutor")
public void doTaskThree() throws Exception {
log.info("开始做任务三");
long start = System.currentTimeMillis();
Thread.sleep(10000);
long end = System.currentTimeMillis();
log.info("完成任务三,耗时:" + (end - start) + "毫秒");
}
}
package com.mbw.controller;
import com.mbw.design_rule.AsyncDemo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class DemoController {
@Autowired
public AsyncDemo asyncDemo;
@GetMapping("/async")
public void getResult() throws Exception {
for (int i = 0; i < 5; i++) {
asyncDemo.doTaskThree();
}
}
}
启动后:

Spring异步线程池的接口类是TaskExecutor,本质还是java.util.concurrent.Executor,没有配置的情况下,默认使用的是simpleAsyncTaskExecutor。
@Async演示Spring默认的simpleAsyncTaskExecutor
@Component
@EnableAsync
public class ScheduleTask {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Async
@Scheduled(fixedRate = 2000)
public void testScheduleTask() {
try {
Thread.sleep(6000);
System.out.println("Spring1自带的线程池" + Thread.currentThread().getName() + "-" + sdf.format(new Date()));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Async
@Scheduled(cron = "*/2 * * * * ?")
public void testAsyn() {
try {
Thread.sleep(1000);
System.out.println("Spring2自带的线程池" + Thread.currentThread().getName() + "-" + sdf.format(new Date()));
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
从运行结果可以看出Spring默认的@Async用线程池名字为SimpleAsyncTaskExecutor,而且每次都会重新创建一个新的线程,所以可以看到TaskExecutor-后面带的数字会一直变大。
simpleAsyncTaskExecutor的特点是,每次执行任务时,它会重新启动一个新的线程,并允许开发者控制并发线程的最大数量(concurrencyLimit),从而起到一定的资源节流作用。默认是concurrencyLimit取值为-1,即不启用资源节流。
上面介绍了Spring默认的线程池simpleAsyncTaskExecutor,但是Spring更加推荐我们开发者使用ThreadPoolTaskExecutor类来创建线程池,其本质是对java.util.concurrent.ThreadPoolExecutor的包装。
这个类则是spring包下的,是Spring为我们开发者提供的线程池类,这里重点讲解这个类的用法。
Spring提供了xml给我们配置ThreadPoolTaskExecutor线程池,但是现在普遍都在用SpringBoot开发项目,所以直接上yaml或者properties配置即可,或者也可以使用@Configuration配置也行,关于使用在3.1讲解@Async的时候其实已经使用,这里在通过配置文件的形式回顾下:
application.properties
# 核心线程池数
spring.task.execution.pool.core-size=5
# 最大线程池数
spring.task.execution.pool.max-size=10
# 任务队列的容量
spring.task.execution.pool.queue-capacity=5
# 非核心线程的存活时间
spring.task.execution.pool.keep-alive=60
# 线程池的前缀名称
spring.task.execution.thread-name-prefix=god-jiang-task-
AsyncScheduledTaskConfig.java
@Configuration
public class AsyncScheduledTaskConfig {
@Value("${spring.task.execution.pool.core-size}")
private int corePoolSize;
@Value("${spring.task.execution.pool.max-size}")
private int maxPoolSize;
@Value("${spring.task.execution.pool.queue-capacity}")
private int queueCapacity;
@Value("${spring.task.execution.thread-name-prefix}")
private String namePrefix;
@Value("${spring.task.execution.pool.keep-alive}")
private int keepAliveSeconds;
@Bean
public Executor myAsync() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
//最大线程数
executor.setMaxPoolSize(maxPoolSize);
//核心线程数
executor.setCorePoolSize(corePoolSize);
//任务队列的大小
executor.setQueueCapacity(queueCapacity);
//线程前缀名
executor.setThreadNamePrefix(namePrefix);
//线程存活时间
executor.setKeepAliveSeconds(keepAliveSeconds);
/**
* 拒绝处理策略
* CallerRunsPolicy():交由调用方线程运行,比如 main 线程。
* AbortPolicy():直接抛出异常。
* DiscardPolicy():直接丢弃。
* DiscardOldestPolicy():丢弃队列中最老的任务。
*/
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
//线程初始化
executor.initialize();
return executor;
}
}
在方法上添加@Async注解,然后还需要在@SpringBootApplication启动类或者@Configuration注解类上 添加注解@EnableAsync启动多线程注解,@Async就会对标注的方法开启异步多线程调用,注意,这个方法的类一定要交给Spring容器来管理
@Component
@EnableAsync
public class ScheduleTask {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Async("myAsync")
@Scheduled(fixedRate = 2000)
public void testScheduleTask() {
try {
Thread.sleep(6000);
System.out.println("Spring1自带的线程池" + Thread.currentThread().getName() + "-" + sdf.format(new Date()));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Async("myAsync")
@Scheduled(cron = "*/2 * * * * ?")
public void testAsyn() {
try {
Thread.sleep(1000);
System.out.println("Spring2自带的线程池" + Thread.currentThread().getName() + "-" + sdf.format(new Date()));
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
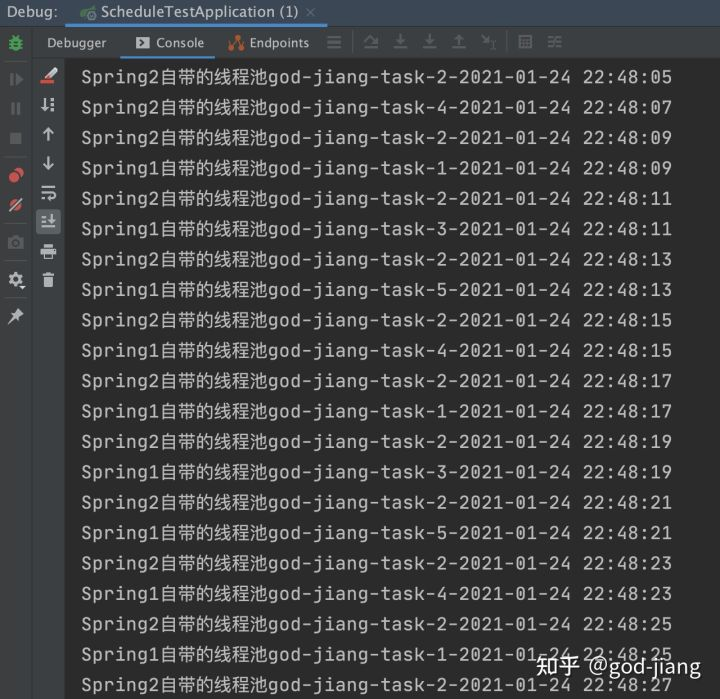
以上从运行结果可以看出,自定义ThreadPoolTaskExecutor可以实现线程的复用,而且还能控制好线程数,写出更好的多线程并发程序。
另外需要注意的是:关于注解失效需要注意以下几点

https://zhuanlan.zhihu.com/p/346086161
https://blog.csdn.net/weixin_43168010/article/details/97613895https://blog.csdn.net/weixin_43168010/article/details/94436901
钩子(Hook)方法的优点:beforeExecute(Thread,Runnable)和afterExecute(Runnable,Throwable)beforeExecute(Thread,Runnable)andafterExecute(Runnable,Throwable)methodsthatarecalledbeforeandafterexecutionofeachtask.Thesecanbeusedtomanipulatetheexecutionenvironment;forexample,reinitializingThreadLocals,gatheringsta
我需要能够更改ThreadPoolExecutor任务队列的大小.当然,BlockingQueue不支持改变大小,ThreadPoolExecutor也不支持改变队列。所以,我想出的方法是使用ThreadPoolExecutor.shutdownNow(),这会返回一个尚未执行的Runnable列表。然后我可以创建一个具有所需队列大小的新执行程序并重新提交所有任务。问题在于调用shutdownNow()时正在进行的任务。据我从javadoc中得知,执行程序将在当前执行任务的所有线程上调用Thread.interrupt()。我不希望我的任务被杀死。这个问题可能是询问如何编写我的任务以使
在Java中使用ThreadPoolExecutor时,处理RejectedExecutionException的最佳方法是什么?我想确保提交的任务不应该被忽视并且应该被执行。截至目前,完成任务没有硬性实时要求。我认为可以做的一件事是在一个循环中等待,直到我知道可运行队列中有空间,然后继续并将其添加到队列中。如果人们可以分享他们的经验,我们会很高兴。添加我想到的可能的解决方案:while(executor.getQueue().remainingCapacity 最佳答案 我会改变你队列的行为。例如publicclassMyBloc
我希望有一个ThreadPoolExecutor,我可以在其中设置一个corePoolSize和一个maximumPoolSize,然后队列将切换任务立即进入线程池,从而创建新线程,直到达到maximumPoolSize,然后开始添加到队列中。有这样的事吗?如果没有,它没有这样的策略有什么充分的理由吗?我本质上想要的是提交任务执行,当它达到一个点,它基本上会因为有太多线程(通过设置maximumPoolSize)而获得“最差”性能时,它将停止添加新线程并且使用该线程池并开始排队,然后如果队列已满则拒绝。当负载回落时,它可以开始将未使用的线程拆除回corePoolSize。在我的申请中,
我有大量图片要从服务器获取,我想获取一些优先级高于其他图片的图片,所以我实现了自己的ThreadPoolExecutor返回一个FutureTask实现了Comparable但它似乎不起作用。这些任务或多或少按照我将它们添加到队列的顺序进行处理。我已经调试了ThreadPoolExecutor的BlockingQueue并发现当我添加具有更高优先级的Runnable时,它并没有转移所有排在队列的顶部。这是代码publicclassPriorityThreadPoolExecutorextendsThreadPoolExecutor{publicPriorityThreadPoolExe
我遇到了一个奇怪的问题。我正在尝试使用生产者/消费者模型,如果我在这里做错了什么,请提出建议。当我使用固定线程4的ExecutorService时,我从来没有得到任何异常并且程序运行但是当我使用ThreadPoolExecutor时,它给了我异常。无法找出错误是什么!请指教!ExecutorService代码:ArrayBlockingQueuelist=newArrayBlockingQueue(2);ThreadFactorythreadFactory=Executors.defaultThreadFactory();ExecutorServicethreadPool=Execut
我在两个类上使用Spring@Async。两者最终都实现了一个接口(interface)。我正在创建两个单独的ThreadPoolTaskExecutor,因此每个类都有自己的ThreadPool来处理。然而,由于我认为代理和Spring如何实现异步类,我必须将@Async注释放在基本接口(interface)上。因此,这两个类最终使用相同的ThreadPoolTaskExecutor。是否可以告诉Spring对于这个Bean(在本例中我将实现该接口(interface)的类称为服务),使用这个ThreadPoolTaskExecutor。 最佳
ThreadPoolExecutor#getActiveCount()的javadocs假设该方法“返回正在执行任务的线程的大致数量。”是什么让这个数字是近似值而不是精确值?它会多报还是少报Activity线程?方法如下:/***Returnstheapproximatenumberofthreadsthatareactively*executingtasks.**@returnthenumberofthreads*/publicintgetActiveCount(){finalReentrantLockmainLock=this.mainLock;mainLock.lock();tr
我使用ThreadPoolExecutor从互联网加载大量图像。当找到新图像时,我需要先渲染它,在这种情况下我想放弃仍在ThreadPoolExecutor中排队的旧任务并添加这些新项目进行下载。我发现ThreadPoolExecutor中没有“clearqueue”方法,“purge”方法听起来不太好。我该怎么办?我只是想调用这个执行器的“关闭”并重新创建一个新的执行器来执行此操作,不确定是否合适。 最佳答案 你试过吗?ThreadPoolExecutorpool=.....;pool.remove(task);task是您要删除
我认为使用ThreadPoolExecutor我们可以在构造函数中传递的BlockingQueue中或使用execute方法提交要执行的Runnable。另外我的理解是,如果任务可用,它将被执行。我不明白的是:publicclassMyThreadPoolExecutor{privatestaticThreadPoolExecutorexecutor;publicMyThreadPoolExecutor(intmin,intmax,intidleTime,BlockingQueuequeue){executor=newThreadPoolExecutor(min,max,10,Time