
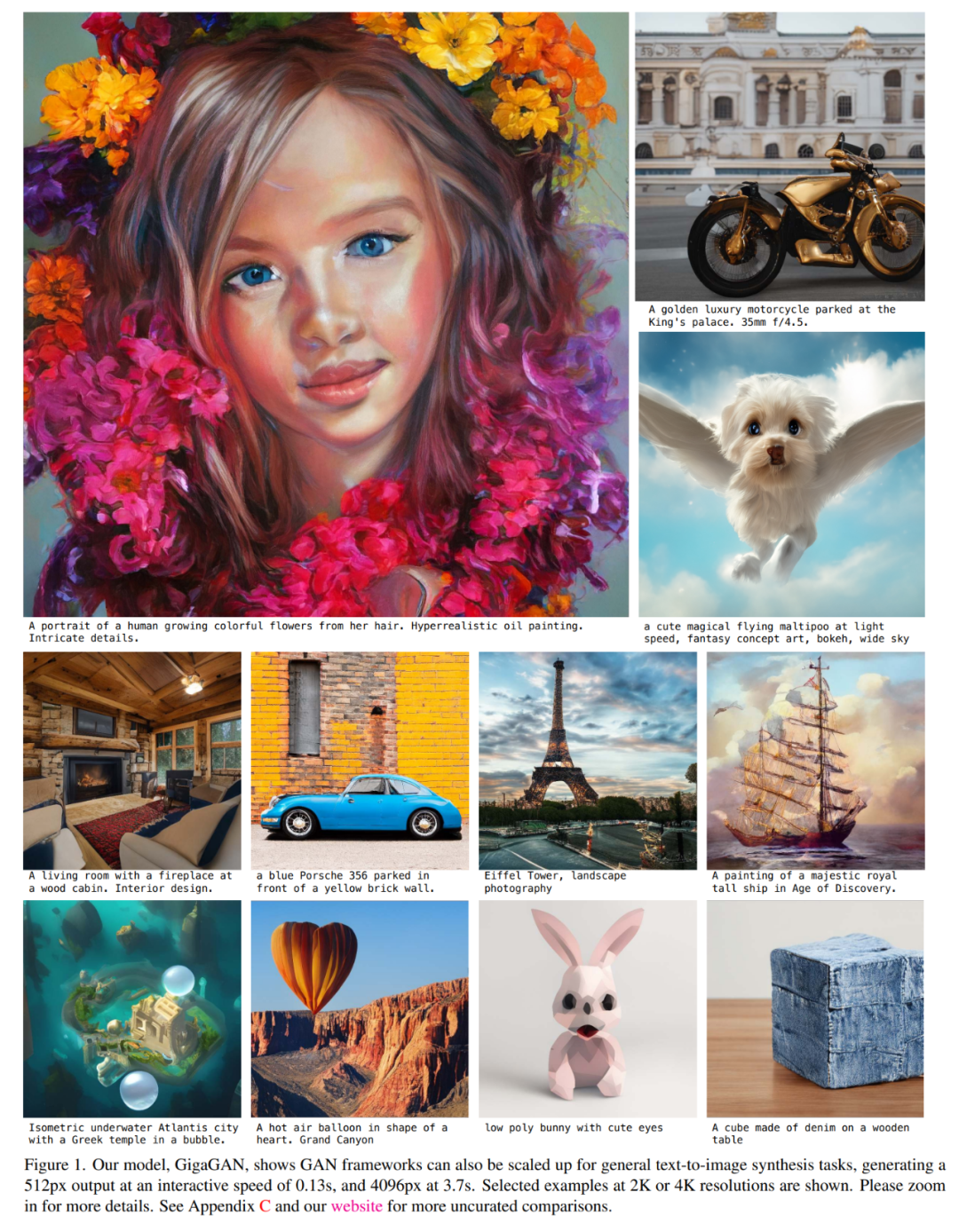
 此外,该研究还采用了多阶段方法 [14, 104],首先以 64 × 64 的低分辨率生成图像,然后再上采样到 512 × 512 分辨率。这两个网络是模块化的,并且足够强大,能够以即插即用的方式使用。该研究表明,基于文本条件的 GAN 上采样网络可以用作基础扩散模型的高效且更高质量的上采样器,如下图 2 和图 3 所示。
此外,该研究还采用了多阶段方法 [14, 104],首先以 64 × 64 的低分辨率生成图像,然后再上采样到 512 × 512 分辨率。这两个网络是模块化的,并且足够强大,能够以即插即用的方式使用。该研究表明,基于文本条件的 GAN 上采样网络可以用作基础扩散模型的高效且更高质量的上采样器,如下图 2 和图 3 所示。 上述改进使 GigaGAN 远远超越了以前的 GAN:比 StyleGAN2 大 36 倍,比 StyleGAN-XL 和 XMC-GAN 大 6 倍。虽然 GigaGAN 十亿(1B)的参数量仍然低于近期的大型合成模型,例如 Imagen (3.0B)、DALL・E 2 (5.5B) 和 Parti (20B),但研究者表示他们尚未观察到关于模型大小的质量饱和。GigaGAN 在 COCO2014 数据集上实现了 9.09 的零样本 FID,低于 DALL・E 2、Parti-750M 和 Stable Diffusion。
上述改进使 GigaGAN 远远超越了以前的 GAN:比 StyleGAN2 大 36 倍,比 StyleGAN-XL 和 XMC-GAN 大 6 倍。虽然 GigaGAN 十亿(1B)的参数量仍然低于近期的大型合成模型,例如 Imagen (3.0B)、DALL・E 2 (5.5B) 和 Parti (20B),但研究者表示他们尚未观察到关于模型大小的质量饱和。GigaGAN 在 COCO2014 数据集上实现了 9.09 的零样本 FID,低于 DALL・E 2、Parti-750M 和 Stable Diffusion。
 该研究成功地在数十亿现实世界图像上训练了基于 GAN 的十亿参数规模模型 GigaGAN。这表明 GAN 仍然是文本到图像合成的可行选择,研究人员们应考虑将其用于未来的积极扩展。
该研究成功地在数十亿现实世界图像上训练了基于 GAN 的十亿参数规模模型 GigaGAN。这表明 GAN 仍然是文本到图像合成的可行选择,研究人员们应考虑将其用于未来的积极扩展。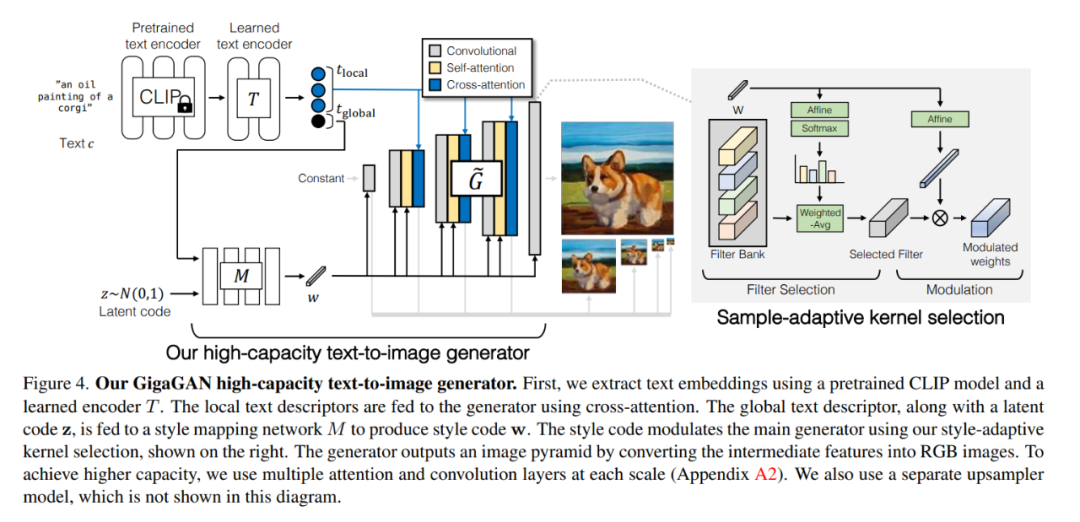 判别器由两个分支组成,用于处理图像和文本调节 t_D。文本分支对文本的处理与生成器类似(图 4)。图像分支接收一个图像金字塔,并对每个图像尺度进行独立预测。此外,预测是在下采样层的所有后续尺度上进行的,这使得它成为一个多尺度输入、多尺度输出(MS-I/O)的判别器。
判别器由两个分支组成,用于处理图像和文本调节 t_D。文本分支对文本的处理与生成器类似(图 4)。图像分支接收一个图像金字塔,并对每个图像尺度进行独立预测。此外,预测是在下采样层的所有后续尺度上进行的,这使得它成为一个多尺度输入、多尺度输出(MS-I/O)的判别器。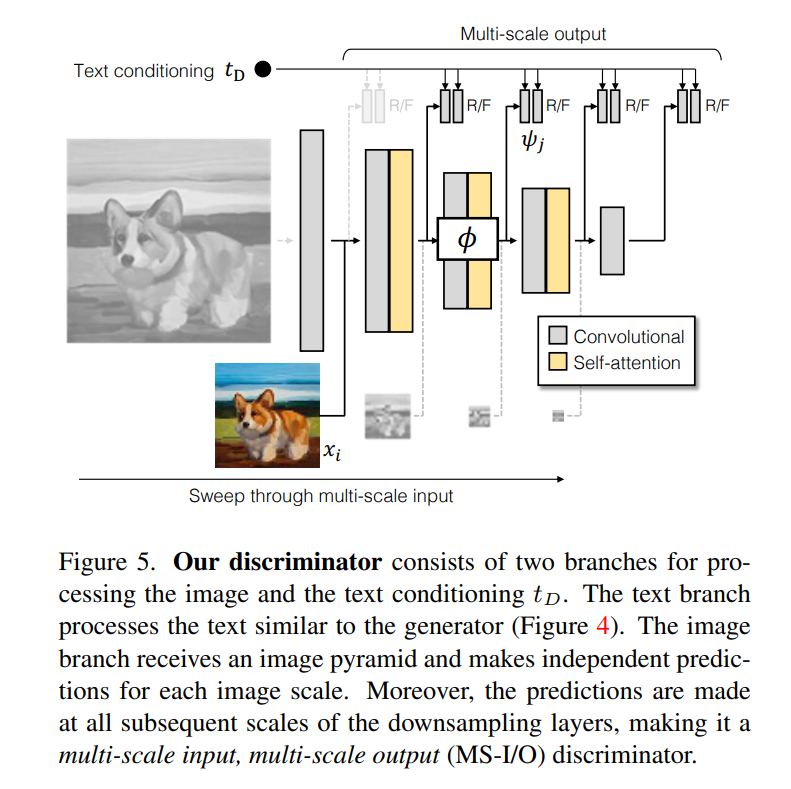 实验结果
实验结果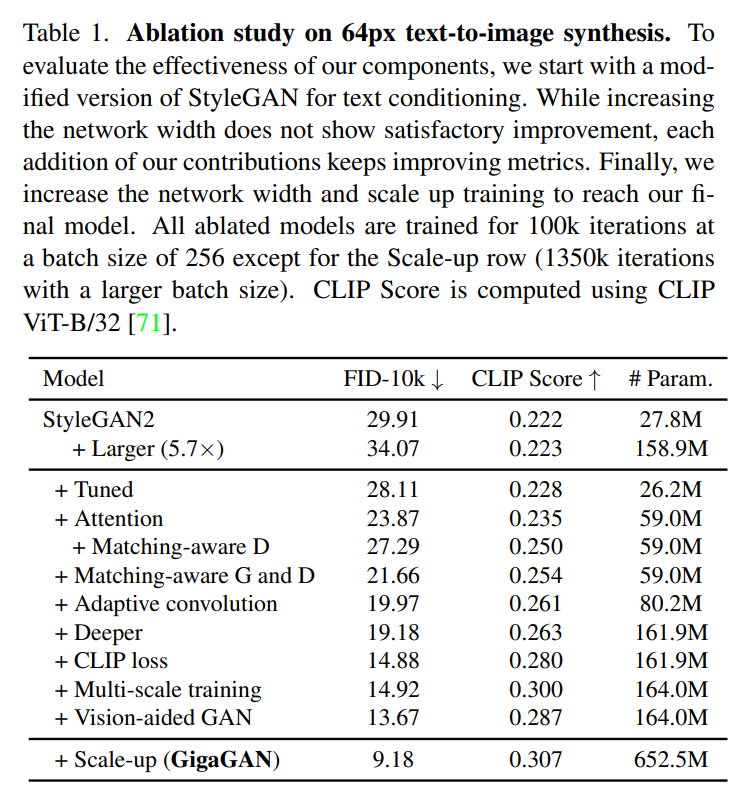 在第二个实验中,他们测试了模型文生图的能力,结果显示,GigaGAN 表现出与 Stable Diffusion(SD-v1.5)相当的 FID,同时产生的结果比扩散或自回归模型快得多。
在第二个实验中,他们测试了模型文生图的能力,结果显示,GigaGAN 表现出与 Stable Diffusion(SD-v1.5)相当的 FID,同时产生的结果比扩散或自回归模型快得多。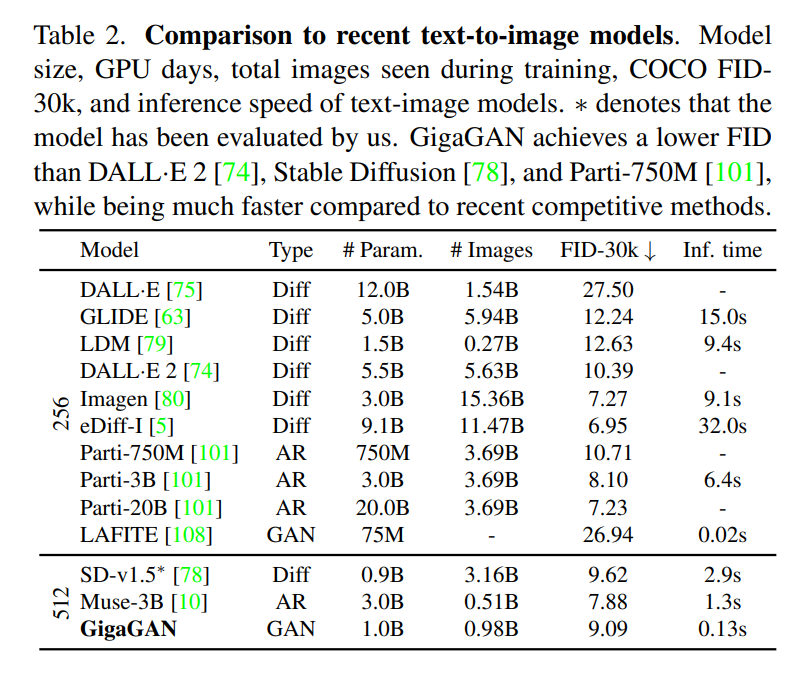 在第三个实验中,他们将 GigaGAN 与基于蒸馏的扩散模型进行比较,结果显示,GigaGAN 能比基于蒸馏的扩散模型更快地合成更高质量的图像。
在第三个实验中,他们将 GigaGAN 与基于蒸馏的扩散模型进行比较,结果显示,GigaGAN 能比基于蒸馏的扩散模型更快地合成更高质量的图像。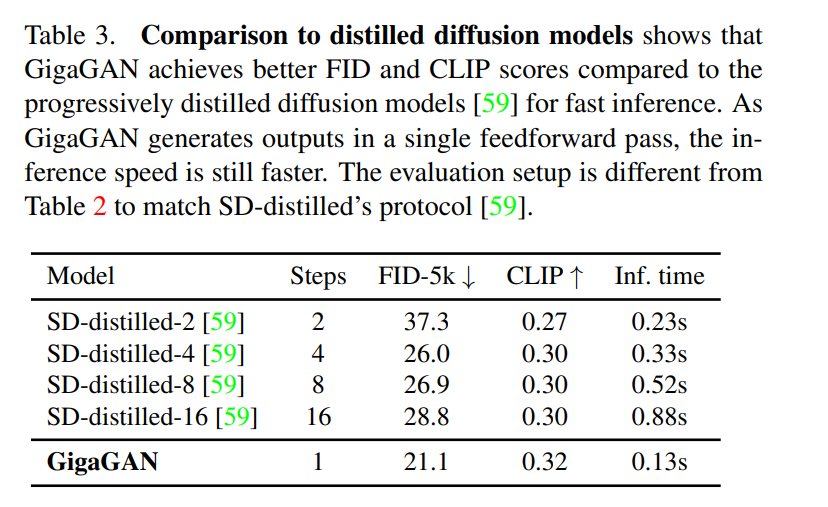 在第四个实验中,他们验证了 GigaGAN 的上采样器在有条件和无条件的超分辨率任务中相比其他上采样器的优势。
在第四个实验中,他们验证了 GigaGAN 的上采样器在有条件和无条件的超分辨率任务中相比其他上采样器的优势。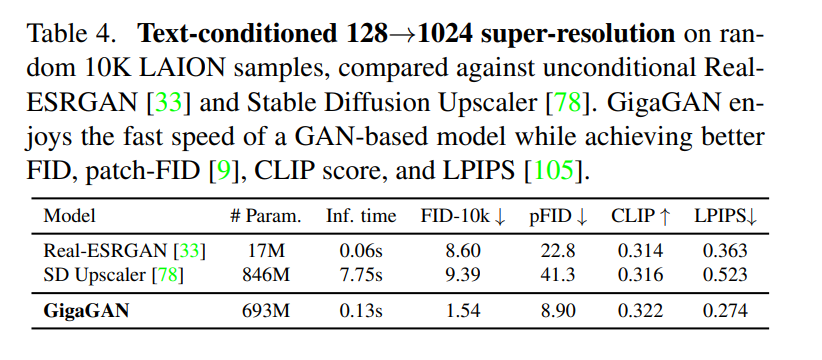
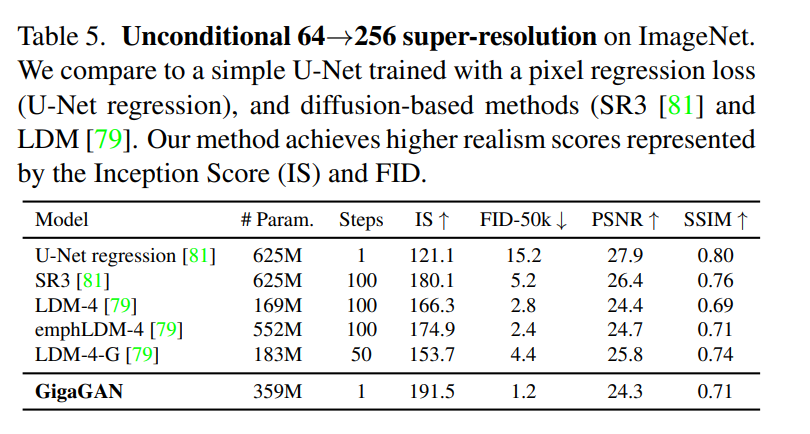 最后,他们展示了自己提出的大规模 GAN 模型仍然享受 GAN 的连续和解纠缠的潜在空间操作,从而实现了新的图像编辑模式。图表请参见上文中的图 6 和图 8。
最后,他们展示了自己提出的大规模 GAN 模型仍然享受 GAN 的连续和解纠缠的潜在空间操作,从而实现了新的图像编辑模式。图表请参见上文中的图 6 和图 8。按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。在我在网上找到的每个基准测试中,Ruby似乎都很慢,比Java慢得多。Ruby的人只是说这无关紧要。您能举个例子说明RubyonRails(以及Ruby本身)的速度真的无关紧要吗?
我有这段代码:date_counter=Time.mktime(2011,01,01,00,00,00,"+05:00")@weeks=Array.new(date_counter..Time.now).step(1.week)do|week|logger.debug"WEEK:"+week.inspect@weeks从技术上讲,代码有效,输出:SatJan0100:00:00-05002011SatJan0800:00:00-05002011SatJan1500:00:00-05002011etc.但是执行时间完全是垃圾!每周计算大约需要四秒钟。我在这段代码中是否遗漏了一些奇怪的低效
我想知道NokogiriXPath或CSS解析是否可以更快地处理HTML文件。速度有何不同? 最佳答案 Nokogiri没有XPath或CSS解析。它将XML/HTML解析为单个DOM,然后您可以使用CSS或XPath语法进行查询。CSS选择器在要求libxml2执行查询之前在内部转换为XPath。因此(对于完全相同的选择器)XPath版本会快一点点,因为CSS不需要先转换成XPath。但是,您的问题没有通用答案;这取决于您选择的是什么,以及您的XPath是什么样的。很有可能,您不会编写与Nokogiri创建的相同的XPath。例如
过程和lambdadiffer关于方法范围和return关键字的效果。我对它们之间的性能差异很感兴趣。我写了一个测试,如下所示:deftime(&block)start=Time.nowblock.callp"thattook#{Time.now-start}"enddeftest(proc)time{(0..10000000).each{|n|proc.call(n)}}enddeftest_block(&block)time{(0..10000000).each{|n|block.call(n)}}enddefmethod_testtime{(1..10000000).each{|
我正在使用RubyonRails3.2.2、FactoryGirl3.1.0、FactoryGirlRails3.1.0、Rspec2.9.0和RspecRails2.9.0。为了测试我的应用程序,我必须在数据库中创建大量记录(大约5000条),但是该操作非常慢(创建记录需要10多分钟)。我这样进行:before(:each)do5000.timesdoFactoryGirl.create(:article,)endend如何改进我的规范代码以加快速度?注意:可能速度较慢是由在每个文章创建过程前后运行的(5)个文章回调引起的,但我可以跳过这些(因为我唯一需要测试的是文章和不是关联的模型
从来源(database_cleaner,active_record)来看,它们应该同样快。但是有人声称使用database_cleaner的事务策略会降低Controller和模型规范的速度(forexample)。我手头没有用于基准测试的大型测试套件。任何人有任何见解或比较两者? 最佳答案 我花了一点时间在广泛使用ActiveRecord固定装置的中型代码库上比较两者。当我将其切换为使用DatabaseCleaner而不是use_transactional_fixtures时,模型规范开始花费大约两倍的时间。在进行了与您相同的比
Ai-Bot基于流行的Node.js和JavaScript语言的一款新自动化框架,支持Windows和Android自动化。1、Windowsxpath元素定位算法支持支持Windows应用、.NET、WPF、Qt、Java和Electron客户端程序和ie、edgechrome浏览器2、Android支持原生APP和H5界面,元素定位速度是appium十倍,无线远程自动化操作多台安卓设备3、基于opencv图色算法,支持找图和多点找色,1080*2340全分辨率找图50MS以内4、内置免费OCR人工智能技术,无限制获取图片文字和找字功能。5、框架协议开源,除官方node.jsSDK外,用户可
(本题试图找出为什么一个程序在不同的处理器上运行会有所不同,所以它与编程的性能方面有关。)以下程序在配备2.2GHzCore2Duo的Macbook上运行需要3.6秒,在配备2.53GHzCore2Duo的MacbookPro上运行需要1.8秒。这是为什么?这有点奇怪……当CPU的时钟速度仅快15%时,为什么要加倍速度?我仔细检查了CPU仪表,以确保2个内核中没有一个处于100%使用率(以便查看CPU是否忙于运行其他东西)。难道是因为一个是MacOSXLeopard,一个是MacOSXSnowLeopard(64位)?两者都运行Ruby1.9.2。pRUBY_VERSIONpRUBY_
在我的一个Rails应用程序中,当我粘贴文本、键入和(尤其是)删除文本时,控制台开始运行得非常慢。我可以在顶部看到irb正在使用大量cpu。但我不知道如何进一步诊断这个问题。它是几周前才开始发生的。我想知道它是否可能与readline/wirble相关?这两个我都用。我刚刚在另一个应用程序中尝试了它,粘贴了一段文本,它看起来同样糟糕-文本以每秒一个字符的速度出现!也许我的命令行历史已经填满了?我怎样才能删除它?(对于Rails控制台,不是我的bash命令行历史记录)感谢任何建议-max编辑-抱歉,应该提供一些系统详细信息。给你:System-Ubuntu10.04Rubyversion
默认情况下,Selenium在我使用Cucumber定义的场景中尽可能快地运行。我想将它设置为以较低的速度运行,这样我就可以拍摄该过程的视频。我发现Selenium::Client::Driver的一个实例有一个set_speed方法。对应于JavaAPI.如何获取Selenium::Client::Driver类的实例?我可以得到page.driver,但它返回Capybara::Driver::Selenium的实例。 最佳答案 感谢http://groups.google.com/group/ruby-capybara/msg