参考文档:https://ruhyadi.github.io/project/computer-vision/yolo3d/
代码:https://github.com/ruhyadi/yolo3d-lightning
本次分享将会从以下四个方面展开:
物体检测模型中的算法选择
单目摄像头下的物体检测神经网络
训练预测参数的设计
模型训练与距离测算
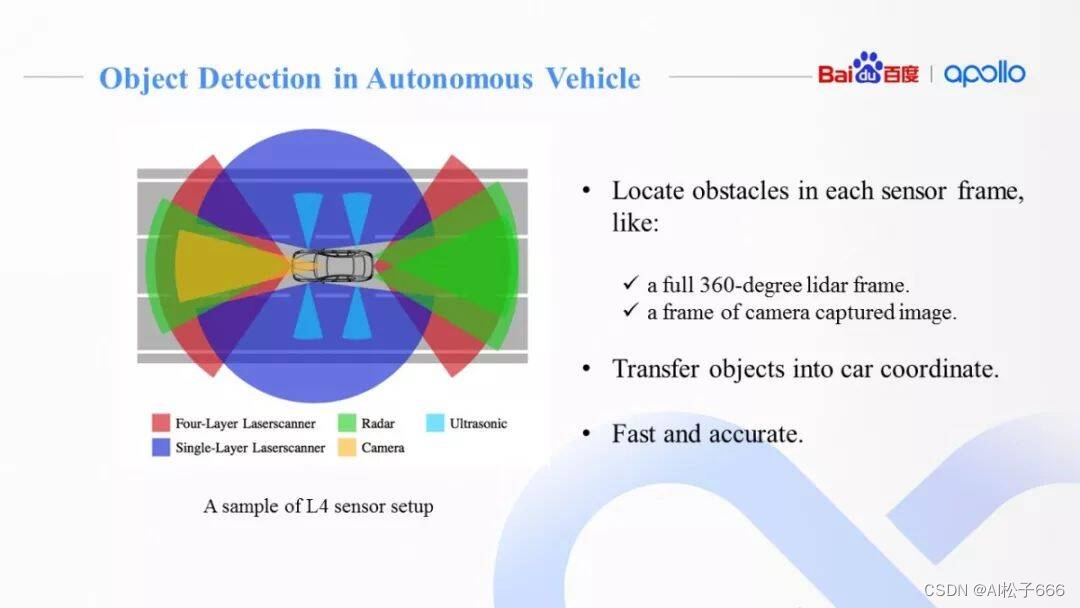
物体检测(Object Detection)是无人车感知的核心问题,要求我们对不同的传感器(如图中覆盖不同观测范围FOV的无人车传感器)设计不同的算法,去准确检测出障碍物。例如在Apollo中,为3D点云而设计的的CNN-SEG深度学习算法,为2D图像而设计的YOLO-3D深度学习算法等。
物体检测要求实时准确的完成单帧的障碍物检测,并借助传感器内外参标定转换矩阵,将检测结果映射到统一的车身坐标系或世界坐标系中。准确率、召回率、算法时耗是物体检测的重要指标。本次分享只覆盖Apollo中基于单目摄像头的物体检测模块。

Apollo 2.5和3.0中,我们基于YOLO V2设计了单目摄像头下的物体检测神经网络, 我们简称它 Multi task YOLO-3D, 因为它最终输出单目摄像头3D障碍物检测和2D图像分割所需的全部信息。
它和原始的YOLO V2有以下几种不同:
物体体检测: 包括2D框(以像素为单位),3D真实物体尺寸(以米为单位),障碍物类别和障碍物相对偏转角(Alpha Angle,和KITTI数据集定义一致)。下文会详细讲解各个输出的意义。
物体分割:车道线信息,并提供给定位模块,这里不做叙述。
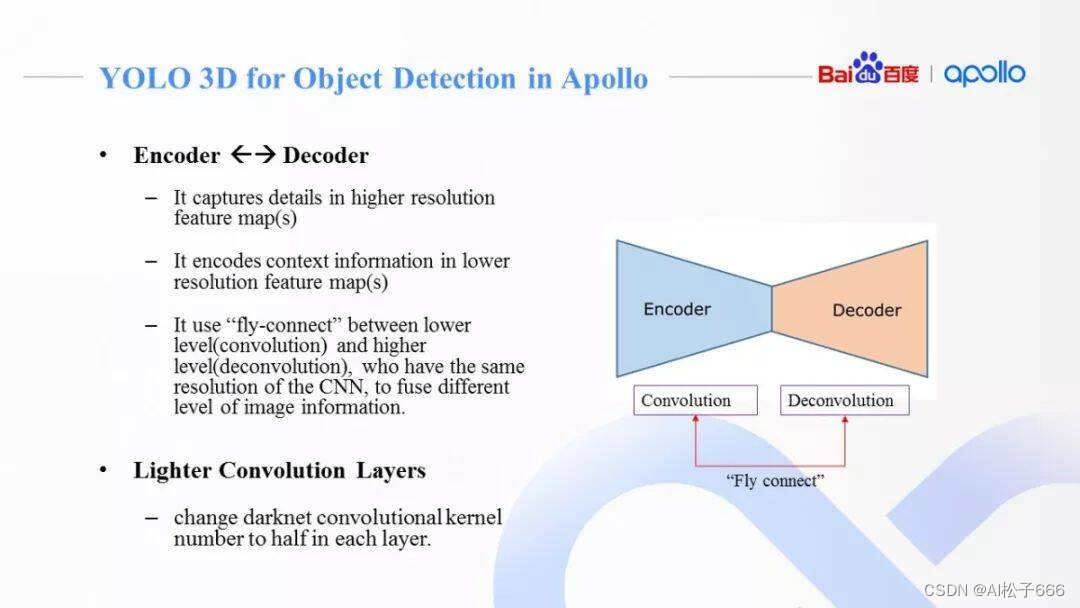
在原始Darknet基础上中,加入了更深的卷积层(Feature Map Size更小)同时添加反卷积层,捕捉更丰富图像上下文信息(Context Information)。高分辨率多通道特征图,捕捉图像细节(例如Edge,Corner),深层低分辨率多通道特征图,编码更多图像上下文信息。和FPN类似的飞线连接,更好的融合了图像的细节和整体信息。

如前文所述,物体检测最终输出包括2D框(以像素为单位),3D真实物体尺寸(以米为单位),障碍物类别和障碍物相对偏转角(Alpha Angle,和KITTI数据集定义一致)等信息。
和YOLO V2算法一样, 我们在标注样本集中通过聚类,产生一定数目的“锚”模板,去描述不同类别、不同朝向、不同大小的障碍物。例如对小轿车和大货车,我们会定义不同的锚模板,去描述它们的实际物理尺寸。

为什么我们要去训练、预测这些参数呢?我们以相机成像的原理来解释:针孔相机(Pinhole Camera)通过投影变换,可以将三维Camera坐标转换为二维的图像坐标。这个变换矩阵解释相机的内在属性,称为相机内参(Camera Intrinsic) K。
对任意一个相机坐标系下的障碍物的3D框,我们可以用它的中心点 T = {X, Y, Z},长宽高 D = {L, W, H},以及各个坐标轴方向上的旋转角 R = {ϕ, φ , θ}来描述。这种9维的参数描述和3D框8点的描述是等价的,而且不需要冗余的8*3个坐标参数来表示。
因此,对一个相机坐标系下3D障碍物,我们通过相机内参,可以投射到2D图像上,得到2D框[c_x, c_y, h, w]。从图中可以看到,一个障碍物在相机下总共有9维3D描述和4维2D描述,他们之间通过相机内参矩阵联系起来。
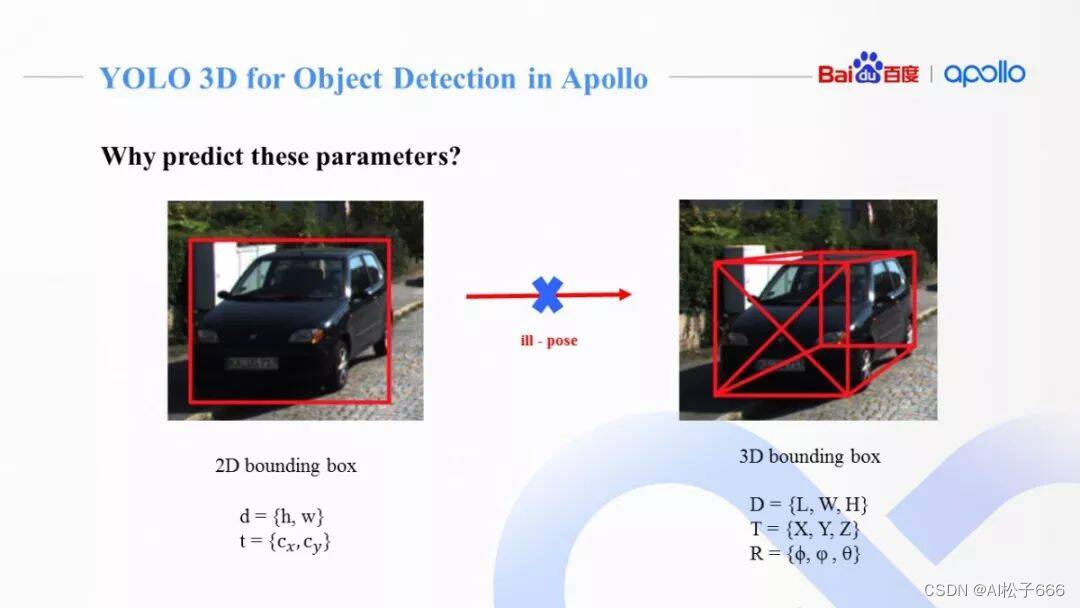
然而,只通过2D框[c_x, c_y, h, w],是没有办法还原成完整的3D障碍物信息。
而通过神经网络直接预测3D障碍物的9维参数,也会比较困难,尤其是预测障碍物3D中心点坐标。所以我们要根据几何学来设计我们到底要训练预测哪些参数。

首先利用地面平行假设,我们可以降低所需要预测的3D参数。
例如:(1)我们假设3D障碍物只沿着垂直地面的坐标轴有旋转,而另外两个方向并未出现旋转,也就是只有yaw偏移角,剩下的Pitch Roll均为0。(2)障碍物中心高度和相机高度相当,所以可以简化认为障碍物的Z=0。
从右图可以看到,我们现在只有6维3D信息需要预测,但还是没有办法避免预测中心点坐标X和Y分量。

第二,我们可以利用成熟的2D障碍物检测算法,准确预测出图像上2D障碍物框(以像素为单位)。
第三,对3D障碍物里的6维描述,我们可以选择训练神经网络来预测方差较小的参数,例如障碍物的真实物理大小,因为一般同一类别的障碍物的物理大小不会出现量级上的偏差(车辆的高度一般在2-5米之间,很少会出现大幅变化)。而yaw 转角也比较容易预测,跟障碍物在图像中的位置关系不大,适合通用物体检测框架来训练和预测。实验中也多次证明此项。
所以现在我们唯一没有训练和预测的参数就是障碍物中心点相对相机坐标系的偏移量X分量和Y分量。需要注意的是障碍物离相机的物理距离Distance=sqrt(X^2 + Y^2)。所以得到X和Y,我们自然就可以得到障碍物离相机的真实距离,这是单目测距的最终要求之一。
综上,我们可以合理的推断出, 实现单目摄像头的3D障碍物检测需要两部分:
训练网络,并预测出大部分参数:
(1)图像上2D障碍物框预测,因为有对应的大量成熟算法文献;
(2)障碍物物理尺寸,因为同类别内方差较小;
(3)不被障碍物在图像上位置所影响,并且通过图像特征(Appearance Feature)可以很好解释的障碍物yaw偏转角。
通过图像几何学,来计算出障碍物中心点相对相机坐标系的偏移量X分量和Y分量。

当我们训练好相应的神经网络,输出我们需要的各个参数之后,我们需要考虑的是如何计算出障碍物离摄像头的距离。根据之前介绍,通过内参和几何学关系,我们可以链接起图像中3D障碍物大小(单位为像素)和真实3D坐标系下障碍物大小(单位为米)。
Apollo这个课件里面介绍的是建立了一个哈希表,通过障碍物大小、朝向来查询距离,但是我在Apollo源码里面没有看到相关代码,代码里面是通过上图公式来计算出Z这个维度,然后根据相机内参,将障碍物2DBox中心点,投影到相机坐标系中,得到相机坐标系下的X,Y坐标,进而得到障碍物的距离D,在进入具体实践之前,还要对图4网络预测的Yaw角度alpha进行一个细致分析。
Apollo网络训练严格遵循了kitti数据集格式,可以在kitti数据集.md文档中查阅数据格式,这里具体对其角度alpha进行解析
从上面分析可知,
对任意一个相机坐标系下的障碍物的3D框,我们可以用它的中心点 T = {X, Y, Z},长宽高 D = {L, W, H},以及各个坐标轴方向上的旋转角 R = {ϕ, φ , θ}来描述。
而我们通过问题的简化,只需要去预测与地面垂直的坐标轴旋转角(Kitti是Y轴),所以就有了下图
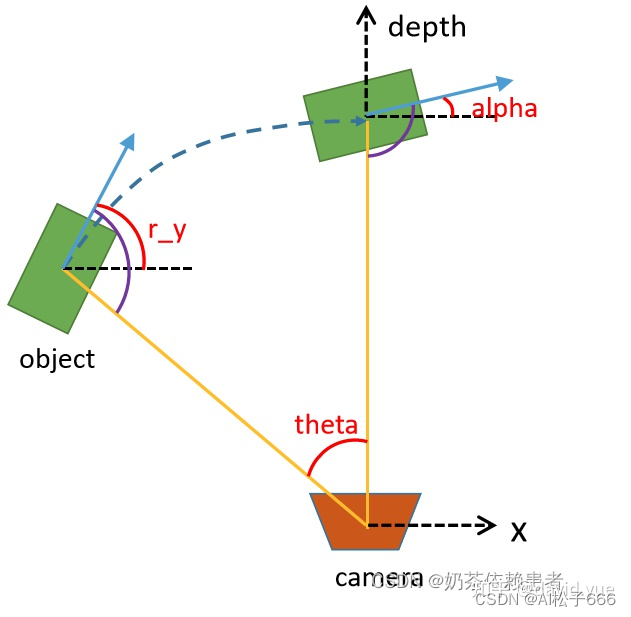
上图中,有三个角度需要特别说明:
alpha:即为模型预测输出,其表示含义为在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴,即此时物体方向与相机x轴的夹角
theta:绕Y轴旋转的角度,具体含义为以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴
r_y:障碍物当前时刻朝向与相机坐标系X轴形成的夹角
**在这个旋转过程中,将车辆看成一个刚体,旋转半径(车辆中心点与相机中心点组成的连线)与车辆前进方向组成的夹角在旋转前后是保持不变的,**根据这一个关系,可以得到如下表达式

YOLO3D 原理参考:
3D Bounding Box Estimation Using Deep Learning and Geometry (Deep3DBox) 论文详解
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc