StoneDB 的主从切换既可以手动切换,也可以自动切换,自动切换通常需要使用第三方中间件。本文介绍的是较为常用的中间件 Replication Manager,当 master 发生宕机时,可自动切换至 slave,保证业务正常运行,故障节点恢复后再加入主从。
服务器配置说明
| IP | Memory | CPU | OS version |
|---|---|---|---|
| 192.168.30.40 | 8G | 8C | CentOS Linux release 7.9 |
| 192.168.30.41 | 8G | 8C | CentOS Linux release 7.9 |
| 192.168.30.42 | 8G | 8C | CentOS Linux release 7.9 |
| 192.168.30.46 | 16G | 16C | CentOS Linux release 7.9 |
注:主从环境中的各个服务器的配置一般情况下建议是一致的,但由于 StoneDB 不管重放 binlog,还是用于 OLAP 场景的查询,都是较消耗系统资源的,建议 StoneDB 配置略高于 MySQL。
主从环境说明
| IP | DATABASE | ROLE | DB version |
|---|---|---|---|
| 192.168.30.40 | MySQL | master | MySQL 5.7 |
| 192.168.30.41 | / | Replication Manager | / |
| 192.168.30.42 | MySQL | slave | MySQL 5.7 |
| 192.168.30.46 | StoneDB | slave | StoneDB 5.7 |
注:MySQL 与 StoneDB 的版本建议保持一致。
推荐采用一主两从的架构,其中 StoneDB 不参与主从切换:
1)master(192.168.30.40)使用 InnoDB 引擎,可读写,提供 OLTP 场景的读写业务;
2)slave1(192.168.30.42)使用 InnoDB 引擎,只读,同时作为 standby,当 master 发生宕机时,可切换至 slave1,保证业务正常运行;
3)slave2(192.168.30.46)使用 Tianmu 引擎,只读,提供 OLAP 场景的读业务。
操作系统环境检查的步骤在四个节点均需要执行。
# systemctl stop firewalld
# systemctl disable firewalld
# vim /etc/selinux/config
SELINUX = disabled
修改vm.swappiness的值为1,表示尽量不使用Swap。
# vi /etc/sysctl.conf
vm.swappiness = 1
# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 1031433
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 65535
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 10240
cpu time (seconds, -t) unlimited
max user processes (-u) 1024
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
修改操作系统的软硬限制
# vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
mysql soft nproc 1028056
mysql hard nproc 1028056
# groupadd mysql
# useradd -g mysql mysql
# passwd mysql
Replication Manager 节点无需创建,以上步骤执行完之后,重启操作系统。
在 master 节点和 slave1 节点安装 MySQL。
https://downloads.mysql.com/archives/community/
从官网下载 MySQL 5.7 的安装包。
# rpm -qa|grep mariadb
mariadb-5.5.56-2.el7.x86_64
mariadb-server-5.5.56-2.el7.x86_64
mariadb-libs-5.5.56-2.el7.x86_64
# yum remove mariadb*
# rpm -qa|grep mariadb
# tar -zxvf mysql-5.7.36-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
# cd /usr/local/
# mv mysql-5.7.36-linux-glibc2.12-x86_64 mysql
# mkdir -p /mysql/data/
# mkdir -p /mysql/log
# chown -R mysql:mysql /mysql/
# vim /etc/my.cnf
[client]
port = 3306
socket = /mysql/data/mysql.sock
[mysqld]
port = 3306
basedir = /usr/local/mysql
datadir = /mysql/data
socket = /mysql/data/mysql.sock
pid_file = /mysql/data/mysqld.pid
log_error = /mysql/log/mysqld.log
log_bin = /mysql/log/mybinlog
server_id = 40
character_set_server = utf8mb4
collation_server = utf8mb4_general_ci
max_connections = 1000
binlog_format = row
default_storage_engine = innodb
read_only=0
innodb_buffer_pool_size = 4096000000
innodb_log_file_size = 1024000000
innodb_log_files_in_group = 3
innodb_io_capacity = 4000
innodb_io_capacity_max = 8000
#开启GTID模式
gtid_mode = on
enforce_gtid_consistency = 1
#并行复制
binlog_transaction_dependency_tracking = WRITESET
transaction_write_set_extraction = XXHASH64
# vim /etc/my.cnf
[client]
port = 3306
socket = /mysql/data/mysql.sock
[mysqld]
port = 3306
basedir = /usr/local/mysql
datadir = /mysql/data
socket = /mysql/data/mysql.sock
pid_file = /mysql/data/mysqld.pid
log_error = /mysql/log/mysqld.log
log_bin = /mysql/log/mybinlog
server_id = 42
character_set_server = utf8mb4
collation_server = utf8mb4_general_ci
max_connections = 1000
binlog_format = row
default_storage_engine = innodb
read_only=1
innodb_buffer_pool_size = 4096000000
innodb_log_file_size = 1024000000
innodb_log_files_in_group = 3
innodb_io_capacity = 4000
innodb_io_capacity_max = 8000
#开启GTID模式
gtid_mode = on
enforce_gtid_consistency = 1
#并行复制
slave_parallel_type = LOGICAL_CLOCK
slave_parallel_workers = 4
/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf --initialize --user=mysql
/usr/local/mysql/bin/mysqld_safe --defaults-file=/etc/my.cnf --user=mysql &
注:管理员用户的临时密码在 mysqld.log 中,第一次登陆后需要修改管理员用户的密码。
https://stonedb.io/zh/docs/download/
从官网下载 StoneDB 5.7 的安装包。
# cd /
# tar -zxvf stonedb-ce-5.7-v1.0.0.el7.x86_64.tar.gz
用户可根据安装规范将安装包上传至服务器,解压出来的目录是 stonedb57,示例中的安装路径是 /stonedb57。
# cd /stonedb57/install/bin
# ldd mysqld
# ldd mysql
如果检查返回有关键字"not found",说明缺少文件,需要安装对应的依赖包。例如:
libsnappy.so.1 => not found
在 Ubuntu 上使用命令 "sudo apt search libsnappy" 检查,说明需要安装 libsnappy-dev。在 RedHat 或者 CentOS 上使用命令 "yum search all snappy" 检查,说明需要安装 snappy-devel、snappy。
mkdir -p /stonedb57/install/data
mkdir -p /stonedb57/install/binlog
mkdir -p /stonedb57/install/log
mkdir -p /stonedb57/install/tmp
mkdir -p /stonedb57/install/redolog
mkdir -p /stonedb57/install/undolog
chown -R mysql:mysql /stonedb57
# vim /stonedb57/install/my.cnf
[client]
port = 3306
socket = /stonedb57/install/tmp/mysql.sock
[mysqld]
port = 3306
basedir = /stonedb57/install/
datadir = /stonedb57/install/data
socket = /stonedb57/install/tmp/mysql.sock
pid_file = /stonedb57/install/data/mysqld.pid
log_error = /stonedb57/install/log/mysqld.log
log_bin = /stonedb57/install/binlog/binlog
server_id = 46
character_set_server = utf8mb4
collation_server = utf8mb4_general_ci
max_connections = 1000
binlog_format = row
default_storage_engine = tianmu
read_only=1
innodb_buffer_pool_size = 2048000000
innodb_log_file_size = 1024000000
innodb_log_files_in_group = 3
innodb_io_capacity = 4000
innodb_io_capacity_max = 8000
innodb_log_group_home_dir = /stonedb57/install/redolog/
innodb_undo_directory = /stonedb57/install/undolog/
innodb_undo_log_truncate = 1
innodb_undo_tablespaces = 3
innodb_undo_logs = 128
#开启GTID模式
gtid_mode = on
enforce_gtid_consistency = 1
#并行复制
slave_parallel_type = LOGICAL_CLOCK
slave_parallel_workers = 8
/stonedb57/install/bin/mysqld --defaults-file=/stonedb57/install/my.cnf --initialize --user=mysql
/stonedb57/install/bin/mysqld_safe --defaults-file=/stonedb57/install/my.cnf --user=mysql &
注:管理员用户的临时密码在 mysqld.log 中,第一次登陆后需要修改管理员用户的密码。
create user 'repl'@'%' identified by 'mysql123';
grant replication slave on *.* to 'repl'@'%';
/usr/local/mysql/bin/mysqldump -uroot -pmysql123 --single-transaction --set-gtid-purged=on -B aa > /tmp/aa.sql
scp /tmp/aa.sql root@192.168.30.42:/tmp
scp /tmp/aa.sql root@192.168.30.43:/tmp
注:如果数据较大,建议使用 mydumper.
/usr/local/mysql/bin/mysql -uroot -pmysql123 -S /mysqldb/data/mysql.sock
source /tmp/aa.sql
注:恢复前需要确保 gtid_executed 为空。
在恢复前,需要修改存储引擎,注释锁表语句。
sed -i 's/UNLOCK TABLES/-- UNLOCK TABLES/g' /tmp/aa.sql
sed -i 's/LOCK TABLES `/-- LOCK TABLES `/g' /tmp/aa.sql
sed -i 's/ENGINE=InnoDB/ENGINE=tianmu/g' /tmp/aa.sql
/stonedb57/install/bin/mysql -uroot -pmysql123 -S /stonedb57/install/tmp/mysql.sock
source /tmp/aa.sql
注:恢复前需要确保 gtid_executed 为空。
CHANGE MASTER TO
MASTER_HOST='192.168.30.40',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='mysql123',
MASTER_AUTO_POSITION = 1;
start slave;
show slave status\G
CHANGE MASTER TO
MASTER_HOST='192.168.30.40',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='mysql123',
MASTER_AUTO_POSITION = 1;
start slave;
show slave status\G
在所有节点都要配置
# vim /etc/hosts
192.168.30.40 HAMI01
192.168.30.41 HAMI02
192.168.30.42 HAMI03
192.168.30.46 HAST05
在 Replication Manager 节点配置
ssh-keygen
ssh-copy-id HAMI01
ssh-copy-id HAMI03
ssh-copy-id HAST05
ssh HAMI01
ssh HAMI03
ssh HAST05
注:若 ssh 免密登录表示免密配置成功。
# vim /etc/yum.repos.d/signal18.repo
[signal18]
name=Signal18 repositories
baseurl=http://repo.signal18.io/centos/2.1/$releasever/$basearch/
gpgcheck=0
enabled=1
# yum install -y replication-manager-osc
# rpm -qa|grep replication
replication-manager-osc-2.2.20-1.x86_64
create user 'rep_monitor'@'%' identified by 'mysql123';
grant reload, process, super, replication slave, replication client, event ON *.* to 'rep_monitor'@'%';
grant select ON mysql.event to 'rep_monitor'@'%';
grant select ON mysql.user to 'rep_monitor'@'%';
grant select ON performance_schema.* to 'rep_monitor'@'%';
# vim /etc/replication-manager/config.toml
# 集群名称
[StoneDB-HA]
# 主从节点
db-servers-hosts = "192.168.30.40:3306,192.168.30.42:3306,192.168.30.46:3306"
# 主节点
db-servers-prefered-master = "192.168.30.40:3306"
# 监控用户
db-servers-credential = "rep_monitor:mysql123"
db-servers-connect-timeout = 2
# 复制用户
replication-credential = "repl:mysql123"
# StoneDB不被用于切换
db-servers-ignored-hosts="192.168.30.46:3306"
##############
## FAILOVER ##
##############
# 故障自动切换
failover-mode = "automatic"
# 30s内再次发生故障不切换,防止硬件问题或网络问题
failover-time-limit=30
[Default]
#########
## LOG ##
#########
log-file = "/var/log/replication-manager.log"
log-heartbeat = false
log-syslog = false
monitoring-datadir = "/var/lib/replication-manager"
log-level=1
replication-multi-master = false
replication-multi-tier-slave = false
failover-readonly-state = true
http-server = true
http-bind-address = "0.0.0.0"
http-port = "10001"
# systemctl start replication-manager
# netstat -lntp|grep replication
tcp6 0 0 :::10001 :::* LISTEN 13128/replication-m
tcp6 0 0 :::10005 :::* LISTEN 13128/replication-m
http://192.168.30.41:10001
默认用户名密码为 admin/repman
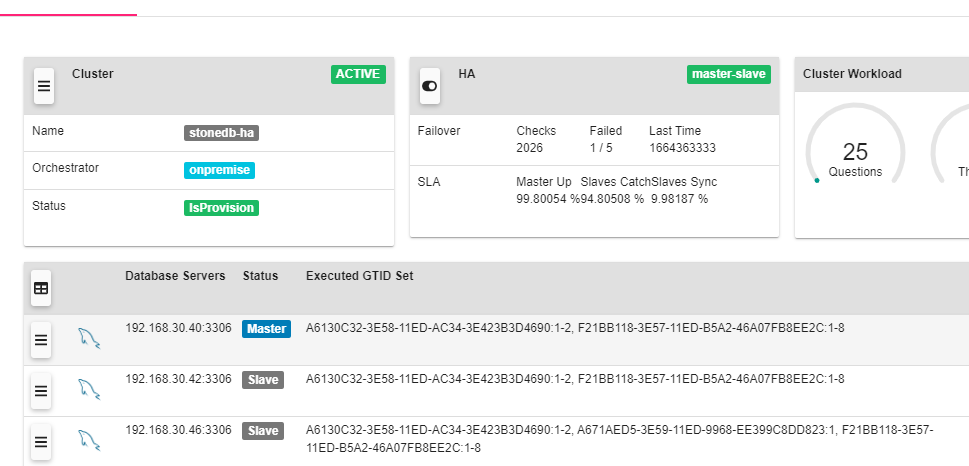
1)建议设置为 GTID 模式;
2)建议主从配置成半同步模式;
3)StoneDB 不参与主从切换。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在从erb文件切换到HAML。我将hamlgem添加到我的系统中。我创建了app/views/layouts/application.html.haml文件。我应该只删除application.html.erb文件吗?此外,仍然有/public/index.html文件被呈现为默认页面。我想创建自己的默认index.html.haml页面。我应该把它放在哪里以及如何使系统呈现该文件而不是默认索引文件?谢谢! 最佳答案 是的,您可以删除任何已转换为HAML的View的ERB版本。至于你的另一个问题,删除public/index/h
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin
如果我构建了一个应用程序来访问来自Gmail、Twitter和Facebook的一些数据,并且我希望用户只需输入一次他们的身份验证信息,并且在几天或几周后重置,那会怎样是在Ruby中动态执行此操作的最佳方法吗?我看到很多人只是拥有他们客户/用户凭证的配置文件,如下所示:gmail_account:username:myClientpassword:myClientsPassword这看起来a)非常不安全,b)如果我想为成千上万的用户存储此类信息,它就无法工作。推荐的方法是什么?我希望能够在这些服务之上构建一个界面,因此每次用户进行交易时都必须输入凭据是不可行的。
我正在使用Devise在Rails应用程序中,并希望通过API公开一些模型数据,但应该像应用程序一样限制对API的访问。$curlhttp://myapp.com/api/v1/sales/7.json{"error":"Youneedtosigninorsignupbeforecontinuing."}很明显。在这种情况下是否有访问API的最佳实践?我更喜欢一步验证+获取数据,但这只是为了让客户的工作更轻松。他们将使用JQuery在客户端提取数据。感谢您提供任何信息!凡妮莎 最佳答案 我建议您按照以下帖子中的选项2:使用APIke