搜索一般都会要求具有“搜索推荐”或者叫“搜索补全”的功能,即在用户输入搜索的过程中,进行自动补全或者纠错。以此来提高搜索文档的匹配精准度,进而提升用户的搜索体验,这就是Suggest。
term suggester正如其名,只基于tokenizer之后的单个term去匹配建议词,并不会考虑多个term之间的关系。
POST /<index>/_search
{
"suggest": {
"<suggest_name>": {
"text": "<search_content>",
"term": {
"suggest_mode": "<suggest_mode>",
"field": "<field_name>"
}
}
}
}
演示索引的数据类型


"suggest_mode": "missing",默认值就是missing,意思就是当搜索的文本和索引100%精准匹配的时候,就没有建议的必要了。对于搜索baoqing,可能以为你想要搜索的是baoqiang、baoqian、baoqia;但对于搜索baoqiang来说,和索引100%匹配,以为你就是要搜索baoqiang。
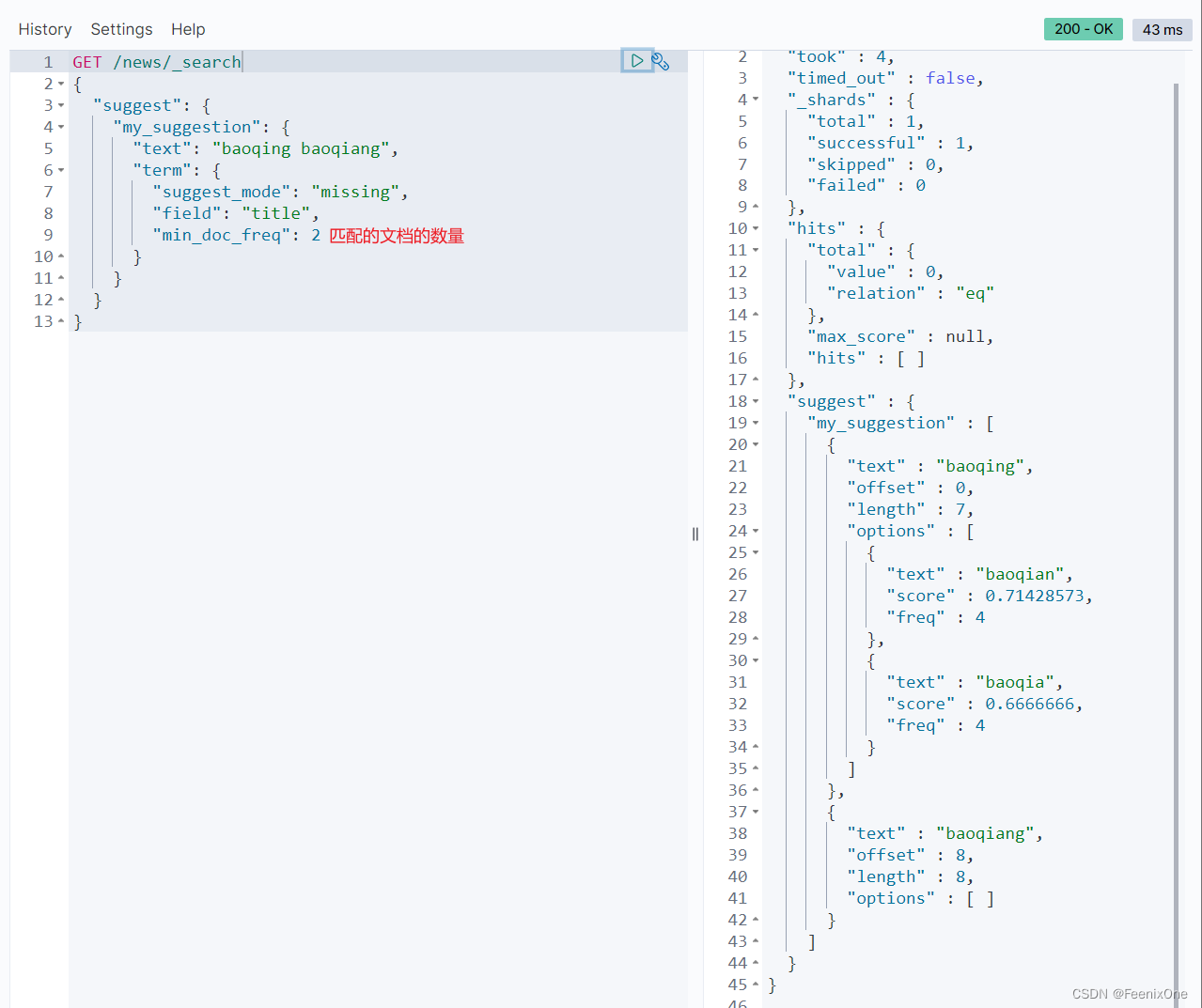
"min_doc_freq": 2,这个是大于的关系,不包含等于。意思是搜索的文本匹配到的文档数要大于2才返回。

"suggest_mode": "popular",这玩意儿说人话其实就是返回的建议词中不包含搜索词。

"suggest_mode": "always",对返回的建议词不做任何的限制。
term suggester可以对单个term进行建议或纠错,不会考虑多个term之间的关系。但是phrase suggester在term suggester基础上会考虑多个term之间的关系,比如是否同时出现一个索引原文中,相邻成都以及词频等。phrase suggester和term suggester相比,对建议的文本会参考上下文,也就是一个句子的其他token,不只是单纯的token距离匹配,它可以基于共生和频率选出更好的建议。
phrase suggester在使用之前先创建一个特定的mapping

值得注意的是,过滤器使用的是shingle,最小和最大值分别是2和3,测试一下

明明最小值是2,为什么还有一个单词的拆分粒度。因为shingle要求是必须要保持一元组的,就是无论最小值和最大值是多少,一定会有单个单词的拆分。可以通过"output_unigrams": false指定关闭保留一元组,这个强烈建议不要关闭,应该保留。

"highlight": {
"pre_tag": "<em>",
"post_tag": "</em>"
}
使用高亮属性可以将被纠正的词在返回中高亮显示提示用户

首先,返回结果中的"text" : "lucene and elasticsearch",这个text并不一定就是文档,和存储的数据不一定就是一样的,只是ES认为你可能想要搜索的文本而已。而且对于ES来说,纠正的词越多,他会认为纠正过的词可信度越高,所以越是纠正的多的,纠正的离谱的,就越会被放在前面推荐使用。
前面两个suggester其实使用的频率很低,说到suggester那基本都是completion suggester的天下。completion suggester基于内存而非索引,性能强悍,不过需要结合特定的completion类型,只适合前缀搜索,并不支持中缀和后缀搜索。
completion suggester可以自动补全,自动完成,支持三种查询【前缀查询(prefix)模糊查询(fuzzy)正则表达式查询(regex)】 ,主要针对的应用场景就是"Auto Completion"。 此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放。对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是Completion Suggester的局限所在。
指定completion suggester的mapping



completion suggester的速度快是通过大量内存换来的,并且只能支持前缀搜索,如果用户输入的不是前缀,召回率可能很低。所以几个suggester应该配合着使用:当使用completion没有结果的时候,应该考虑加入fuzzy参数来纠错,还没有结果的话可以考虑使用term suggester
completion suggester通过映射上下文来实现,在索引和查询启用上下文的完成字段时,必须提供上下文。添加上下文呢映射会增加completion的字段的索引大小,并且这一代过程发生在堆中。完成建议者会考虑索引中的所有文档,但是通常来说,我们在进行智能推荐的时候最好通过某些条件过滤,并且有可能会针对某些特性提升权重。
context的名字,用于区分同一个索引中不同的context对象。需要在查询的时候指定当前namecontext对象的类型,目前支持两种:category和geo,分别用于对suggest item分类和指定地理位置。指定context suggester的mapping

定义一个名为 place_type 的类别上下文,其中类别必须与建议一起发送;
定义一个名为 location 的地理上下文,类别必须与建议一起发送。

使用boost增加权重,在返回数据集中优先排序。
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
给定一个元素和一个数组,Ruby#index方法返回元素在数组中的位置。我使用二进制搜索实现了我自己的索引方法,期望我的方法会优于内置方法。令我惊讶的是,内置的在实验中的运行速度大约是我的三倍。有Rubyist知道原因吗? 最佳答案 内置#indexisnotabinarysearch,这只是一个简单的迭代搜索。但是,它是用C而不是Ruby实现的,因此自然可以快几个数量级。 关于Ruby#index方法VS二进制搜索,我们在StackOverflow上找到一个类似的问题: