

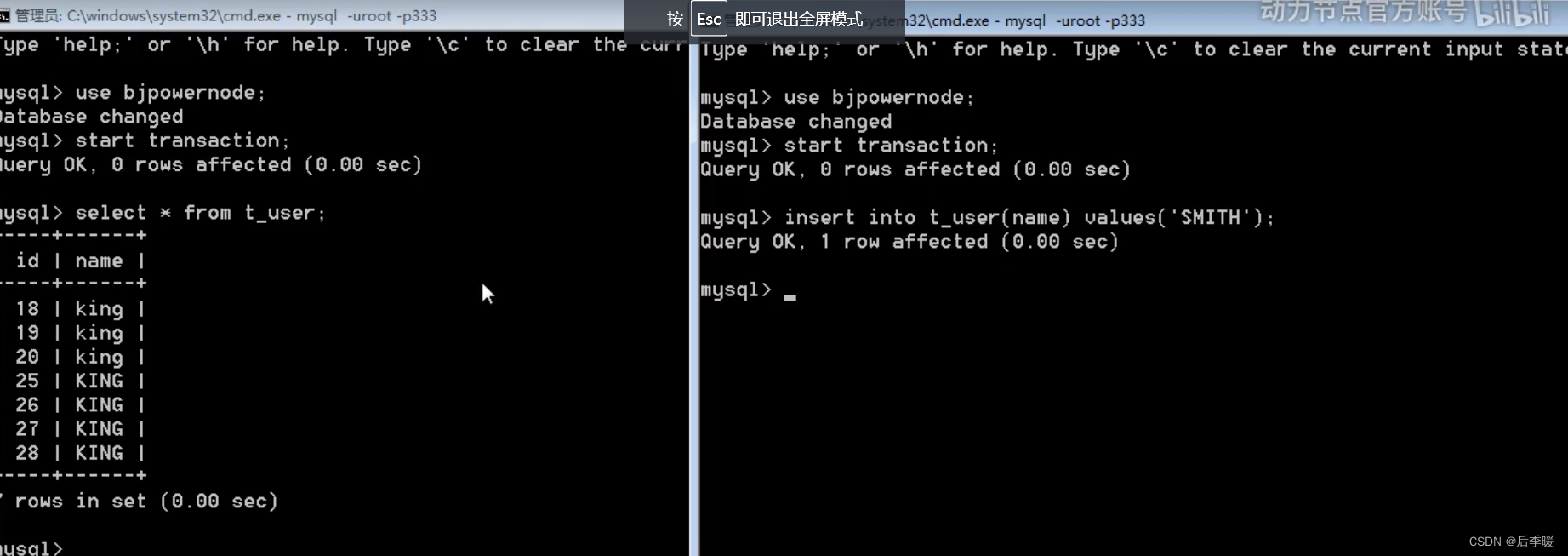
开两个cmd窗口:
我们发现,右边窗口已经开启事务,insert添加了一行数据,(因为开启了事务 所以不会自动提 交)
所以并没有提交 ,但左边能读出来你添加的这行数据了。这就是读未提交。
脏读就是假如现在右边目前执行的事务不想要了,回滚了,也就是不想添加这一行了,那么左边 读取的数据还是有添加的这一行,这就是脏读。
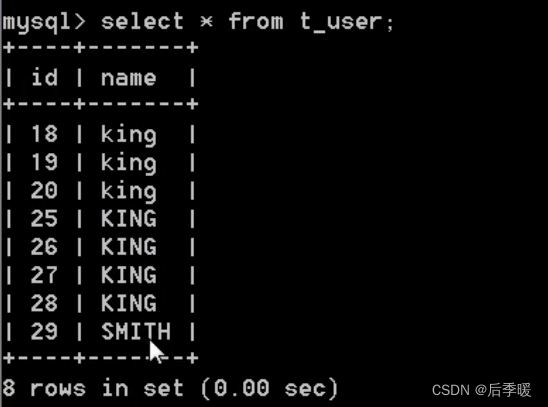
读已提交,顾名思义,就是可以读取到已经提交事务的内容。
这个级别很显然,当你只有提交事务的时候,别的地方才能读取到你的操作。
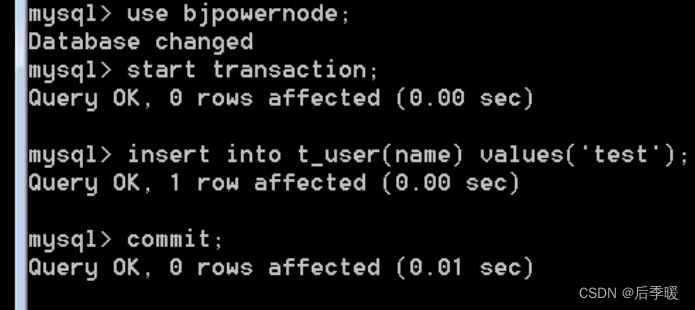
commit以后,左边就能读到了。
但是!这样的话,就不可重复读了!因为比如1时刻,你这个事务读取这个表的数据是张三,
2时刻另外有一个事务把张三改成了李四,并且提交了该事务。这样在你原来那个事务再次查询的
时候(4时刻),读到的就是李四了,导致两次读取结果不一致。
比如此时表中只有一条数据,id为1,name为张三。
一时刻,我们在左边表开启一个事务,查询这个表id为2的数据,发现没有。
二时刻,我们在右边表开启一个事务,并添加一条id=2,name=‘王五’的数据,并提交。
三时刻,我们在左表再次查询id为2的数据,发现还是没有,这就是幻读,读到的是幻象。
此时我们在左边表更新id=2的数据,name改为‘李四’,发现居然成功了?此时我们再查询id为2的数据,发现查询出来了,并且name已经改为李四。
可见,幻读就是没有读到的记录,以为不存在,但其实是可以更新成功的,并且,更新成功后,再次读取,就出现了。
是最严格的隔离级别。在Serializable隔离级别下,所有事务按照次序依次执行,因此,脏读、不可重复读、幻读都不会出现。
虽然Serializable隔离级别下的事务具有最高的安全性,但是,由于事务是串行执行,所以效率会大大下降,应用程序的性能会急剧降低。如果没有特别重要的情景,一般都不会使用Serializable隔离级别。
默认隔离级别
如果没有指定隔离级别,数据库就会使用默认的隔离级别。在MySQL中,如果使用InnoDB,默认的隔离级别是Repeatable Read。Oracle默认的隔离级别是read Committed。
另外补充事务的四种级别:原子性、一致性、隔离性、持久性。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
保存成功后可以回滚吗?让我有一个带有属性名称、电子邮件等的用户模型。例如u=User.newu.name="test_name"u.email="test@email.com"u.save现在记录将成功保存在数据库中,之后我想回滚我的事务(不是销毁或删除)。有什么想法吗? 最佳答案 您可以通过交易来做到这一点,请参阅http://markdaggett.com/blog/2011/12/01/transactions-in-rails/例子:User.transactiondoUser.create(:username=>'Nemu
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
我正在使用此代码在我的Sinatra应用程序中启用日志记录:log_file=File.new('my_log_file.log',"a")$stdout.reopen(log_file)$stderr.reopen(log_file)$stdout.sync=true$stderr.sync=true实际的日志记录是使用:logger.debug("Startingcall.Params=#{params.inspect}")事实证明,只有INFO或更高级别的日志消息被记录,而DEBUG消息没有被记录。我正在寻找一种将日志级别设置为DEBUG的方法。 最佳