只分享干货、不吹水,让我们一起加油!?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。
当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。打个比方,当它说不认识你时,肯定就不认识;当它说见过你时,可能根本就没见过面,不过因为你的脸跟它认识的人中某脸比较相似 (某些熟脸的系数组合),所以误判以前见过你。
套在上面的使用场景中,布隆过滤器能准确过滤掉那些已经看过的内容,那些没有看过的新内容,它也会过滤掉极小一部分 (误判),但是绝大多数新内容它都能准确识别。这样就可以完全保证推荐给用户的内容都是无重复的。
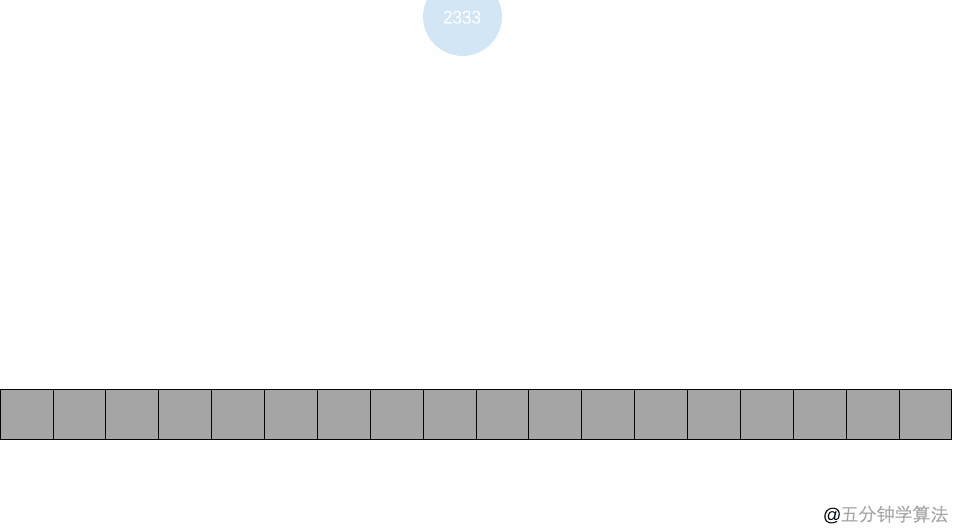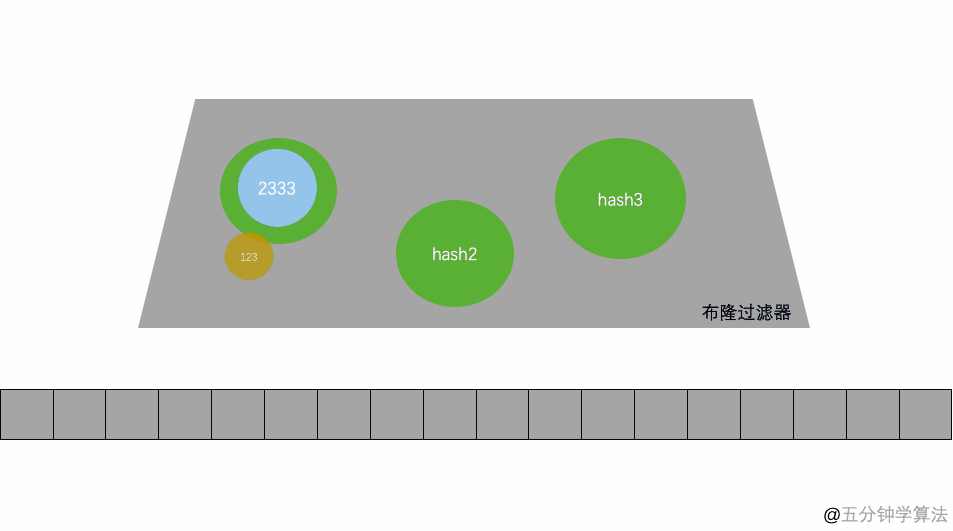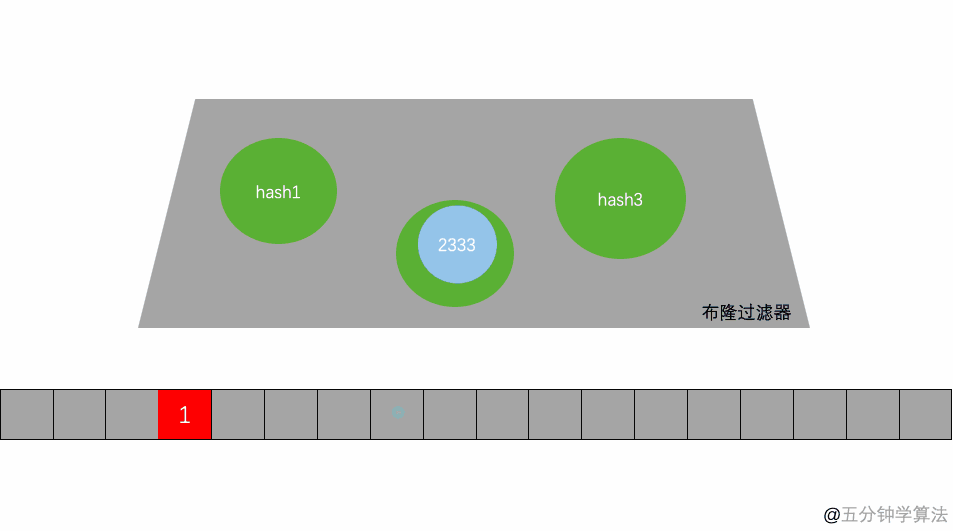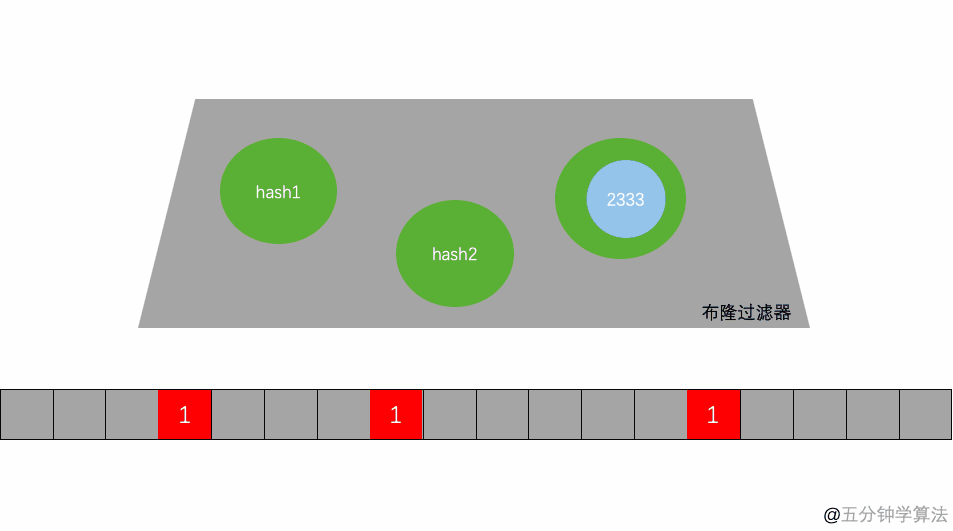
其本质就是一个只包含0和1的数组。具体操作当一个元素被加入到集合里面后,该元素通过K个Hash函数运算得到K个hash后的值,然后将K个值映射到这个位数组对应的位置,把对应位置的值设置为1。查询是否存在时,我们就看对应的映射点位置如果全是1,他就很可能存在(跟hash函数的个数和hash函数的设计有关),如果有一个位置是0,那这个元素就一定不存在。
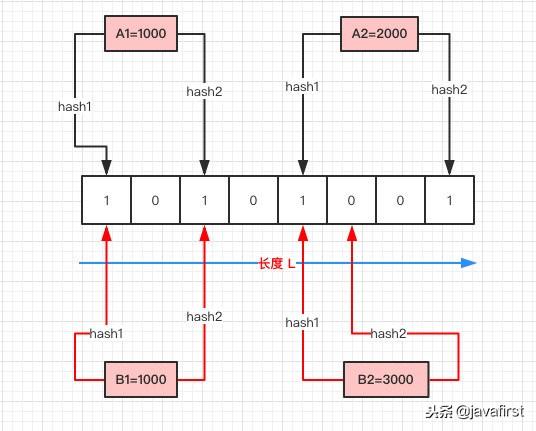
整个的写入、查询的流程就是这样,汇总起来就是:
对写入的数据做 H 次 hash 运算定位到数组中的位置,同时将数据改为 1 。当有数据查询时也是同样的方式定位到数组中。一旦其中的有一位为 0 则认为数据肯定不存在于集合,否则数据可能存在于集合中。
只要返回数据不存在,则肯定不存在。
返回数据存在,但只能是大概率存在。
同时不能清除其中的数据。
在有限的数组长度中存放大量的数据,即便是再完美的 Hash 算法也会有冲突,所以有可能两个完全不同的 A、B 两个数据最后定位到的位置是一模一样的。
删除数据也是同理,当我把 B 的数据删除时,其实也相当于是把 A 的数据删掉了,这样也会造成后续的误报。
基于以上的 Hash 冲突的前提,所以 Bloom Filter 有一定的误报率,这个误报率和 Hash 算法的次数 H,以及数组长度 L 都是有关的。
我们经常会把一部分数据放在Redis等缓存,比如产品详情。这样有查询请求进来,我们可以根据产品Id直接去缓存中取数据,而不用读取数据库,这是提升性能最简单,最普遍,也是最有效的做法。一般的查询请求流程是这样的:先查缓存,有缓存的话直接返回,如果缓存中没有,再去数据库查询,然后再把数据库取出来的数据放入缓存,一切看起来很美好。但是如果现在有大量请求进来,而且都在请求一个不存在的产品Id,会发生什么?既然产品Id都不存在,那么肯定没有缓存,没有缓存,那么大量的请求都怼到数据库,数据库的压力一下子就上来了,还有可能把数据库打死。
使用布隆过滤器的特点,只要返回数据不存在,则肯定不存在,返回数据存在,但只能是大概率存在,这种特点可以大批量的无效请求过滤掉,能够穿透缓存的知识漏网之鱼,无关紧要。
检查一个单词拼写是否正确,因为有海量的单词数量,每天可能有新的单词,使用布隆过滤器,可以将单词映射到很小的内存中,可以经过简单的几次hash运行就可以进行校验,只要返回数据不存在,则肯定不存在,返回数据存在,但只能是大概率存在,虽然可能有误报,但是对系统的提升是革命性的。
这就又要提起我们的Guava了,它是Google开源的Java包,提供了很多常用的功能。
Guava中,布隆过滤器的实现主要涉及到2个类,BloomFilter和BloomFilterStrategies,首先来看一下BloomFilter的成员变量。需要注意的是不同Guava版本的BloomFilter实现不同。
COPY/** guava实现的以CAS方式设置每个bit位的bit数组 */
private final LockFreeBitArray bits;
/** hash函数的个数 */
private final int numHashFunctions;
/** guava中将对象转换为byte的通道 */
private final Funnel<? super T> funnel;
/**
* 将byte转换为n个bit的策略,也是bloomfilter hash映射的具体实现
*/
private final Strategy strategy;
这是它的4个成员变量:
LockFreeBitArray是定义在BloomFilterStrategies中的内部类,封装了布隆过滤器底层bit数组的操作。
numHashFunctions表示哈希函数的个数。
Funnel,它和PrimitiveSink配套使用,能将任意类型的对象转化成Java基本数据类型,默认用java.nio.ByteBuffer实现,最终均转化为byte数组。
Strategy是定义在BloomFilter类内部的接口,代码如下,主要有2个方法,put和mightContain。
COPYinterface Strategy extends java.io.Serializable {
/** 设置元素 */
<T> boolean put(T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits);
/** 判断元素是否存在*/
<T> boolean mightContain(
T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits);
.....
}
创建布隆过滤器,BloomFilter并没有公有的构造函数,只有一个私有构造函数,而对外它提供了5个重载的create方法,在缺省情况下误判率设定为3%,采用BloomFilterStrategies.MURMUR128_MITZ_64的实现。
BloomFilterStrategies.MURMUR128_MITZ_64是Strategy的两个实现之一,Guava以枚举的方式提供这两个实现,这也是《Effective Java》书中推荐的提供对象的方法之一。
COPYenum BloomFilterStrategies implements BloomFilter.Strategy {
MURMUR128_MITZ_32() {//....}
MURMUR128_MITZ_64() {//....}
}
二者对应了32位哈希映射函数,和64位哈希映射函数,后者使用了murmur3 hash生成的所有128位,具有更大的空间,不过原理是相通的,我们选择相对简单的MURMUR128_MITZ_32来分析。
先来看一下它的put方法,它用两个hash函数来模拟多个hash函数的情况,这是布隆过滤器的一种优化。
COPYpublic <T> boolean put(
T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) {
long bitSize = bits.bitSize();
// 先利用murmur3 hash对输入的funnel计算得到128位的哈希值,funnel现将object转换为byte数组,
// 然后在使用哈希函数转换为long
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
// 根据hash值的高低位算出hash1和hash2
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
boolean bitsChanged = false;
// 循环体内采用了2个函数模拟其他函数的思想,相当于每次累加hash2
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
// 如果是负数就变为正数
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
// 通过基于bitSize取模的方式获取bit数组中的索引,然后调用set函数设置。
bitsChanged |= bits.set(combinedHash % bitSize);
}
return bitsChanged;
}
在put方法中,先是将索引位置上的二进制置为1,然后用bitsChanged记录插入结果,如果返回true表明没有重复插入成功,而mightContain方法则是将索引位置上的数值取出,并判断是否为0,只要其中出现一个0,那么立即判断为不存在。
COPYpublic <T> boolean mightContain(
T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) {
long bitSize = bits.bitSize();
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
// Flip all the bits if it's negative (guaranteed positive number)
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
// 和put的区别就在这里,从set转换为get,来判断是否存在
if (!bits.get(combinedHash % bitSize)) {
return false;
}
}
return true;
}
Guava为了提供效率,自己实现了LockFreeBitArray来提供bit数组的无锁设置和读取。我们只来看一下它的put函数。
COPYboolean set(long bitIndex) {
if (get(bitIndex)) {
return false;
}
int longIndex = (int) (bitIndex >>> LONG_ADDRESSABLE_BITS);
long mask = 1L << bitIndex; // only cares about low 6 bits of bitIndex
long oldValue;
long newValue;
// 经典的CAS自旋重试机制
do {
oldValue = data.get(longIndex);
newValue = oldValue | mask;
if (oldValue == newValue) {
return false;
}
} while (!data.compareAndSet(longIndex, oldValue, newValue));
bitCount.increment();
return true;
}
COPY<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
COPY
public class GuavaBloomFilter {
/**
* 设置布隆过滤器大小
*/
private static final int size = 100000;
/**
* 构建一个BloomFilter
* 第一个参数Funnel类型的参数
* 第二个参数 期望处理的数据量
* 第三个参数 误判率 可不加,默认 0.03D
*/
private static final BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), size);
public static void main(String[] args) {
//成功计数
float success = 0;
//失败计数
float fial = 0;
Set<String> stringSet = new HashSet<String>();
for (int i = 0; i < size; i++) {
//生成随机字符串
String randomStr = RandomStringUtils.randomNumeric(10);
//加入到set中
stringSet.add(randomStr);
//加入到布隆过滤器
bloomFilter.put(randomStr);
}
for (int i = 0; i < size; i++) {
//生成随机字符串
String randomStr = RandomStringUtils.randomNumeric(10);
//布隆过滤器校验存在
if (bloomFilter.mightContain(randomStr)) {
//set中存在
if (stringSet.contains(randomStr)) {
//成功计数
success++;
} else {
//失败计数
fial++;
}
//布隆过滤器校验不存在
} else {
// set中存在
if (stringSet.contains(randomStr)) {
//失败计数
fial++;
} else {
//成功计数
success++;
}
}
}
System.out.println("判断成功数:"+success + ",判断失败数:" + fial + ",误判率:" + fial / 100000);
}
输出
COPY判断成功数:97084.0,判断失败数:2916.0,误判率:0.02916
可以通过增加误判率的参数来调整误判率
COPY/**
* 构建一个BloomFilter
* 第一个参数Funnel类型的参数
* 第二个参数 期望处理的数据量
* 第三个参数 误判率 可不加,默认 0.03D
*/
private static final BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), size,0.00001);
输出
COPY判断成功数:100000.0,判断失败数:0.0,误判率:0.0
本文由
传智教育博学谷狂野架构师教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源
我有一个名为Post的类,我需要能够适应以下场景:如果用户选择了一个类别,则只显示该类别的帖子如果用户选择了一种类型,则只显示该类型的帖子如果用户选择了一个类别和类型,则只显示该类别中该类型的帖子如果用户没有选择任何内容,则显示所有帖子我想知道我的Controller是否不可避免地会因大量条件语句而显得粗糙...这是我解决此问题的错误方法-有谁知道我如何才能做到这一点?classPostsController 最佳答案 您最好遵循“胖模型,瘦Controller”的惯例,这意味着您应该将这种逻辑放在模型本身中。Post类应该能够报告
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
我仍然收到标题中的“错误”消息,但不知道如何解决。在ApplicationController中,classApplicationController在routes.rb#match'set_activity_account/:id/:value'=>'users#account_activity',:as=>:set_activity_account--thisdoesn'tworkaswell..resources:usersdomemberdoget:action_a,:action_bendcollectiondoget'account_activity'endend和User
对于用户模型,我有一个过滤器来检查用户的预订状态,该状态由整数值(0、1或2)表示。UserActiveAdmin索引页上的过滤器是通过以下代码实现的:filter:booking_status,as::select然而,这会导致下拉选项为0、1或2。当管理员用户从下拉列表中选择它们时,我更愿意自己将它们命名为“未完成”、“待定”和“已确认”之类的名称。有没有办法在不改变booking_status在模型中的表示方式的情况下做到这一点? 最佳答案 假设booking_status是模型中的枚举字段,您可以使用:过滤器:booking
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我来自C、php和bash背景,很容易学习,因为它们都有相同的C结构,我可以将其与我已经知道的联系起来。然后2年前我学了Python并且学得很好,Python对我来说比Ruby更容易学。然后从去年开始,我一直在尝试学习Ruby,然后是Rails,我承认,直到现在我还是学不会,讽刺的是那些打着简单易学的烙印,但是对于我这样一个老练的程序员来说,我只是无法将它
究竟如何使用Liquid中的map过滤器?我在Jekyll中使用它。---my_array:[apple,banana,orage]my_map:hello:worldfoo:barmy_string:"howdoesthiswork?"---{{page.my_map|map...}}这就是我迷路的地方。我似乎无法在文档或任何其他在线网站上找到任何关于它的用法示例。顺便说一下,我还不懂Ruby,所以sourcecode我也不清楚。来自filtertests看起来下面应该产生一些东西,但在GitHub上,我什么也没得到:{{site.posts|map:'title'|array_to
有道无术,术尚可求,有术无道,止于术。本系列SpringBoot版本3.0.4本系列SpringSecurity版本6.0.2本系列SpringAuthorizationServer版本1.0.2源码地址:https://gitee.com/pearl-organization/study-spring-security-demo文章目录前言1.OAuth2AuthorizationServerMetadataEndpointFilter2.OAuth2AuthorizationEndpointFilter3.OidcProviderConfigurationEndpointFilter4.N
我知道before_filter已被rails弃用。我没有调用它,但出于某种原因,我收到一条消息说我正在打电话。before_filterisdeprecatedandwillberemovedinRails5.1.Usebefore_actioninstead.(calledfromat/Users/intern/Desktop/Work/app/config/environment.rb:5)在那个文件中environment.rb在第5行,我不是在过滤器之前调用,而是这一行Rails.application.initialize!为什么它没有被调用时会说正在使用前置过滤器?任何帮