🚀1、要利用已训练过的词向量模型进行词语相似度计算,实验中采用的词向量模型已事先通过训练获取的。
🚀2、于数据采用的是 2020 年特殊年份的数据,“疫情”是主要 话题。
🚀3、在计算词语之间的相似度时,采用的词语与“疫情”相关
🚀1、加载已训练的词向量模型,直接调用 models.word2vec.Word2Vec.load 加载模型 wiki.model。
🚀2、计算多种形式的词语相似度
🚀3、model 计算不同方法下的词语相似度
**
**
🚀1、加载模型,获得某个词的词向量
代码:
# TODO 鸟欲高飞,必先展翅
# TODO 向前的人 :Jhon
import warnings
warnings.filterwarnings('ignore')
from gensim import models
model = models.word2vec.Word2Vec.load('wiki.model')
# TODO 步骤2.1 todo:获取某个词对应的词向量,了解词向量
word = '疫情' #注意:词库里面要有这个词,否则会报错
vector = model.wv[word] #获取单词的词向量
print('{}的词向量为:\n{}'.format(word,vector))
# print(vector.shape())
print(len(vector))
print("-"*66)
截图:
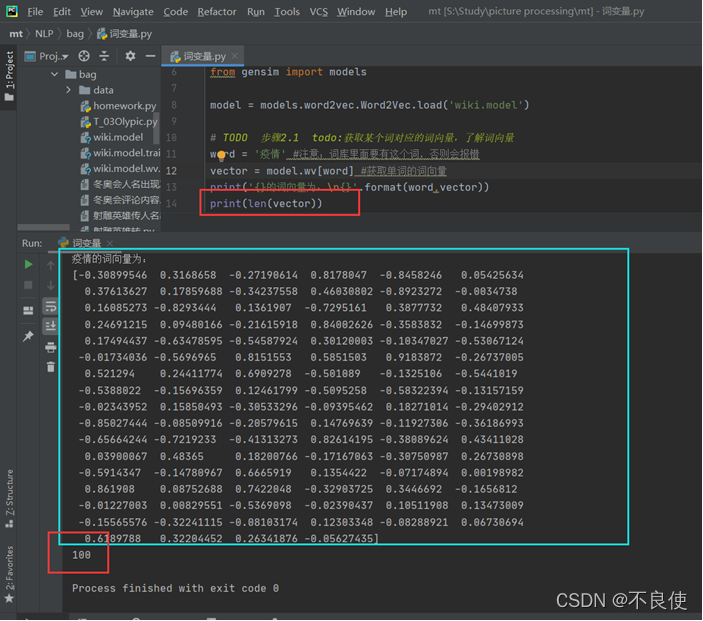
由上面的代码我们可以得出和疫情相关的100个词的相似度。我们可以发现有的相似度大于80%,但有的却是负相关。Ok,下面我们来使用wv.similarity计算两个词语的余弦相似度
🚀2、计算两个词语之间的相似度
# TODO 鸟欲高飞,必先展翅
# TODO 向前的人 :Jhon
import warnings
warnings.filterwarnings('ignore')
from gensim import models
model = models.word2vec.Word2Vec.load('wiki.model')
# TODO 步骤2.1 todo:获取某个词对应的词向量,了解词向量
word = '疫情' #注意:词库里面要有这个词,否则会报错
vector = model.wv[word] #获取单词的词向量
print('{}的词向量为:\n{}'.format(word,vector))
print(len(vector))
print("-"*66)
# TODO 步骤2.2 todo:使用wv.similarity计算两个词语的余弦相似度
word1 = '疫情'
word2 = '新冠'
distance = model.wv.similarity(word1,word2)
print('%s与%s的相似度为:%.4f'%(word1,word2,distance))
截图:
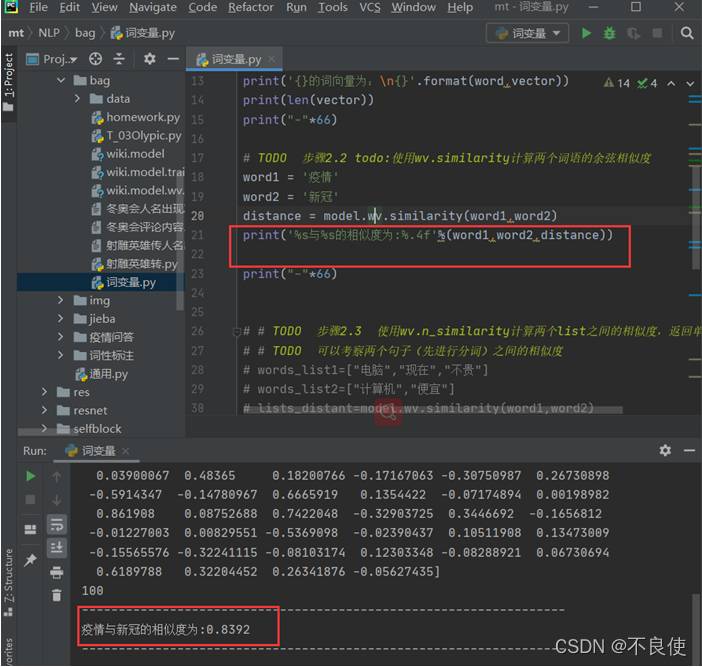
可以得出疫情与新冠的相似度为:0.8392这个结论。所以当出现疫情的时候我们就会不加思考的想到新冠。
🚀3、使用wv.n_similarity计算两个list之间的相似度
代码:
import warnings
warnings.filterwarnings('ignore')
from gensim import models
model = models.word2vec.Word2Vec.load('wiki.model')
# TODO 步骤2.3 使用wv.n_similarity计算两个list之间的相似度,返回单个值
# TODO 可以考察两个句子(先进行分词)之间的相似度
words_list1 = ['电脑', '现在', '不贵']
words_list2 = ['计算机', '便宜']
list_distant=model.wv.n_similarity(words_list1,words_list2)
print("%s与%s相似度为:%.4f" % (words_list1, words_list2, list_distant))
截图:
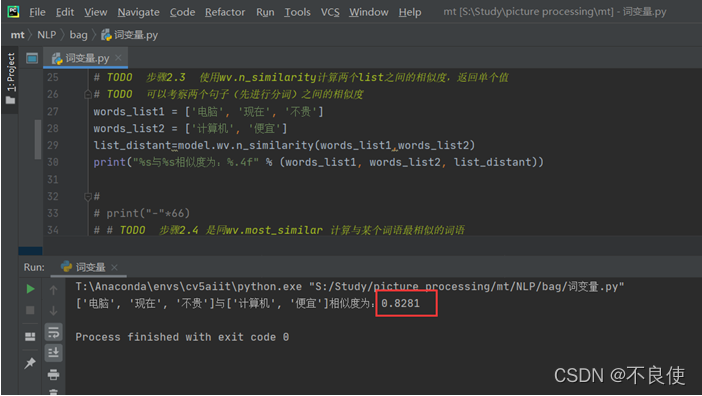
由上面的model模型中的wv.n_similarity计算两个list之间的相似度,[‘电脑’, ‘现在’, ‘不贵’]和[‘计算机’, ‘便宜’]之间的相似度为0.8281,很高的相似度了,与实际相符。
🚀4、计算与一个词语最相似的前topn个词语
代码:
# TODO 步骤2.4 是同wv.most_similar 计算与某个词语最相似的词语
# 步骤2.4.1 使用要搜索的词和topn参数,计算与一个词语最相似的前topn个词语
top_n=8
word="疫情"
model_word=model.wv.most_similar(word,topn=top_n)
print('\n文本字典中与\"{}\"最相似的前{}个词语依次是'.format(word,top_n))
print([{"词语":item[0],"相似度":"%.5f"%item[1]} for item in model.wv.most_similar(word,topn=top_n)])
截图:
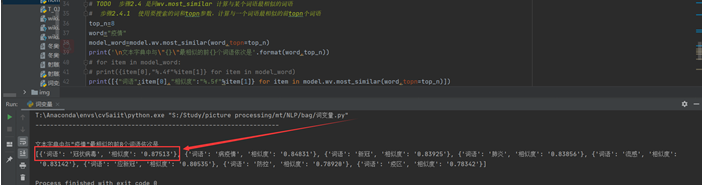
我们可以发现和疫情最相似的词语是冠状病毒。其次是病疫情,这应该是jieba分词的错误,第三个是新冠,和实际相符。
🚀5、计算其他形式的词语相似度
~👀5.1、最相似的五个词
代码:
list_1 = ['中国', '华盛顿']
list_2 = ['北京']
topn = 5
model_word =model.wv.most_similar(positive=list_1,negative=list_2,topn=topn)
print('\n与\"{}---{}+{}\"最相似的前5个词语为'.format(list_1[0],list_2[0],list_1[1],topn))
for item in model_word:
print(item[0],'%.4f'%item[1])
截图:
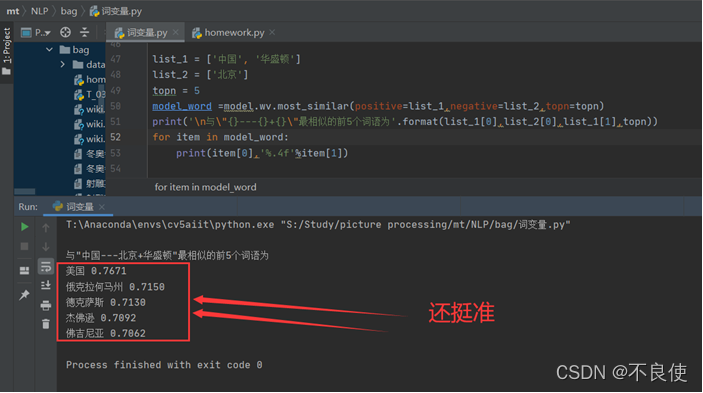
我们可以发现还是挺准的,说明这个模型还是挺成功的。达到预期效果。
~👀5.2、wv.doesnt_match 找出列表中不属于同一类的词语**
代码:
word_list=['北京','上海','广州','纽约']
Not_need_country=model.wv.doesnt_match(word_list)
print(r'{}中不属于同一类的词语为:{}'.format(word_list,Not_need_country))
截图:
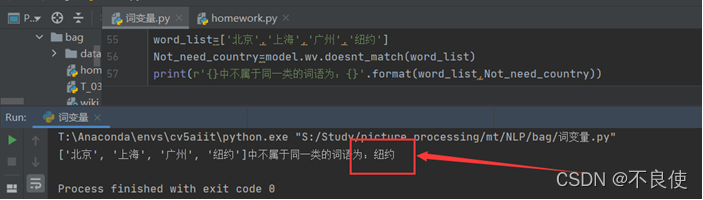
我们可以发现模型中的wv的doesn’t_match方法找到列表国家中不是同一类的国家。
我们计算其他形式的词语相似度,主要应用 model 的 most_similar 和 doesnt_match 方法来完成它。利用维基百科训练出来的模型效果还是比较理想的,可以计算出多种形式下的词语相似度。由于已训练的词向量模型采用的是 2020 年 8 月 5 日中文维基百科数据语 料,2020 年是较为的特殊年份,“疫情”是主要话题,因此在计算“疫情” 与“新冠”之间的相似度,其值约为 0.839;与疫情最相似的 8 个词语中 均符合认知但是“电脑 现在 不贵”与“计算机 便宜”的相似度为 0.8281,按照认知, 这两句话的相似度应该能达到 0.9 以上。综上可得模型结果依赖于模型采用的语料库通用性较差,而且计算相似度的词语必须都存在模型训练前的训练数据中,不然会出现所计算相似的的词语不存在模型中之类的报错。所以,这个模型还有缺陷,但是这是固性问题,毕竟就是我们要判断两者有没有关系,也要通过大脑接受一些文本信息进行判断,只不过这个过程你们忽视而已。
有问题可以评论区打出来,或者私聊也可以的
觉得有用的可以给个三连,关注一波!!!带你了解更多的自然语言处理小知识
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我看到这个错误:translationmissing:da.datetime.distance_in_words.about_x_hours我的语言环境文件:http://pastie.org/2944890我的看法:我已将其添加到我的application.rb中:config.i18n.load_path+=Dir[Rails.root.join('my','locales','*.{rb,yml}').to_s]config.i18n.default_locale=:da如果我删除I18配置,帮助程序会处理英语。更新:我在config/enviorments/devolpment
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------