文章目录
位图是一种非常常用的数据结构,本质其实是一个二进制数组。位图和哈希表类似,都是进行映射,但又有不同。位图的每一位都用于表示数据的某种状态,例如存在或者不存在,并不表示数据本身。而哈希表时用来存放关键字key。位图更加适用于海量数据处理及分析。
位图判断数据是否存在,则有两种状态,存在和不存在,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在,相当于哈希表的直接定址法。比如:
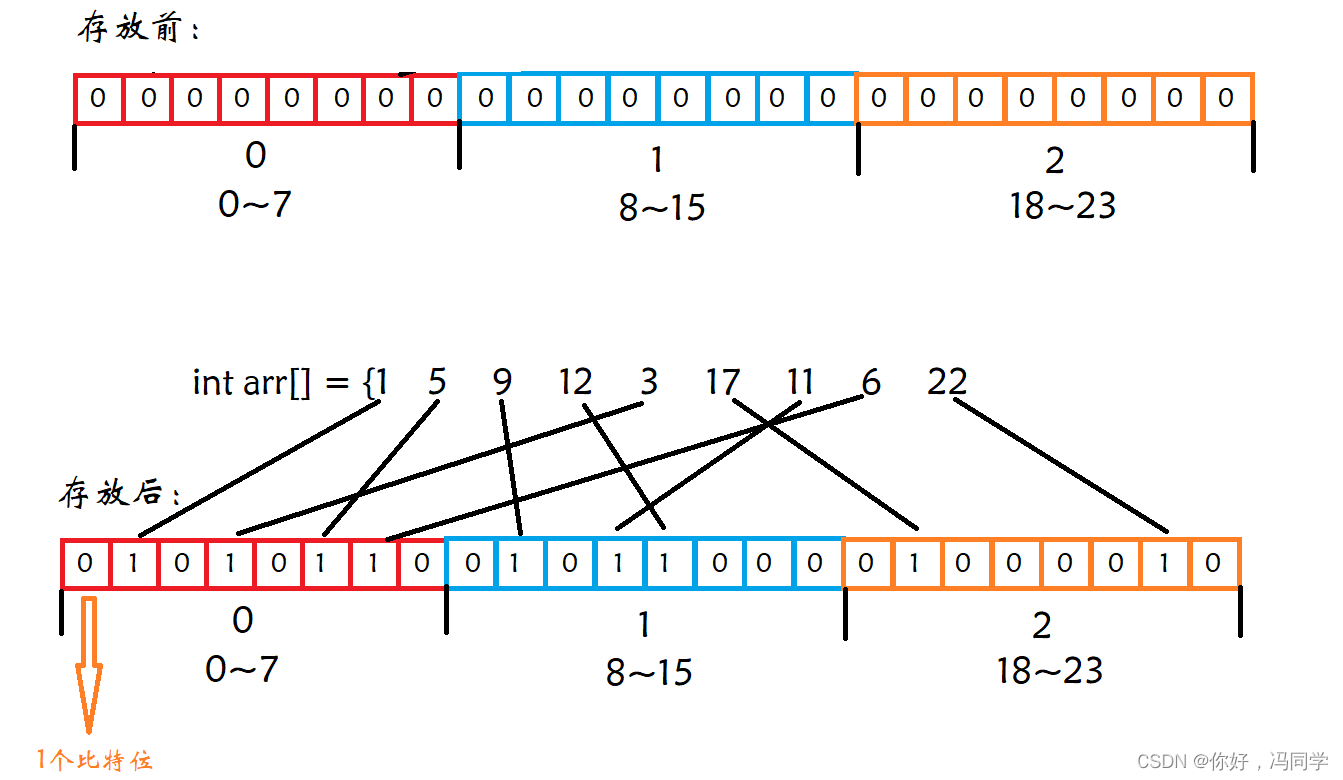
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中
方法1:遍历,时间复杂度O(N)
方法2:排序(O(Nlog2N)),利用二分查找: log2N
方法3:位图解决
方法1和方法2很简单,此时就不在进行过多赘述。
主要来看一下方法3:首先我们需要知道无符号整数表达的最大值为4294967295,虽然有40亿个数,但很多数都是重复的,也不会超过这个最大值。为了保证在无符号整数范围内每个数都不发生冲突,位图就需要4294967295比特位,最终换算相当于需要511M内存空间,对于现在的普通计算机而言,是完全可以承受的。空间开辟好后,对这40亿个数进行一一映射,将相应的比特位置为1即可。至于如何操作,请看后文。
template<size_t N>
class Biteset
{
public:
Biteset()
{
_bits.resize(N / 8 + 1, 0);//每次都要多开一个,例如需要表示0-16,需要17个比特位
}
//将n所对应的比特位置为1
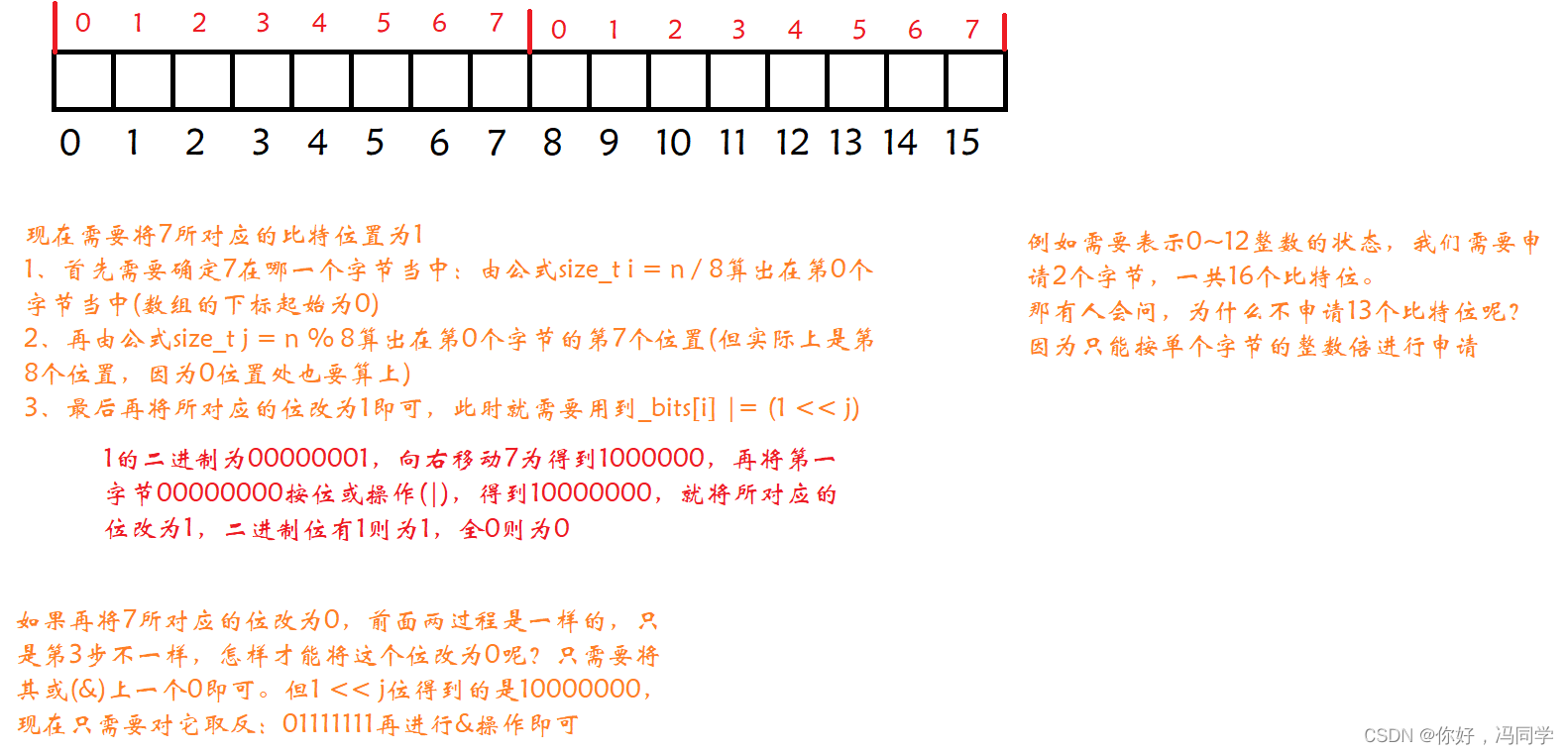
void set(size_t n)
{
size_t i = n / 8;
size_t j = n % 8;
_bits[i] |= (1 << j);//将对应的位置位1
}
//将n所对应的比特位置为0
void reset(size_t n)
{
size_t i = n / 8;
size_t j = n % 8;
_bits[i] &= (~(1 << j));//将对应的位置位0
}
//判断一个数是否存在
bool exist(size_t n)
{
size_t i = n / 8;
size_t j = n % 8;
return (_bits[i] & (1 << j));
}
std::vector<char> _bits;
};
因为C++申请空间不能按比特位的个数进行申请,只能按单个字节的整数倍进行申请。所以我们申请一个类型为char的vector,每一个char都有8个比特位,就能够表示8个数的存在状态。
在每个成员函数中,i都表示vector中第几个char(字节),j表示这个char(字节)的第几个比特位。对此可以进行画图分析:
代码测试:
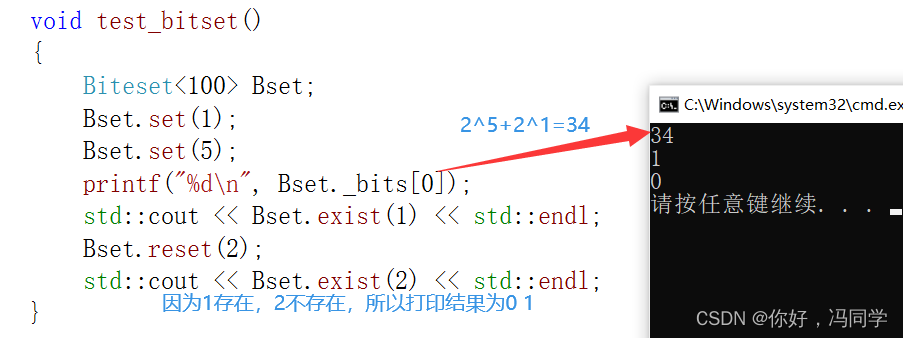
void test_bitset()
{
Biteset<100> Bset;
Bset.set(1);
Bset.set(5);
printf("%d\n", Bset._bits[0]);
std::cout << Bset.exist(1) << std::endl;
Bset.reset(2);
std::cout << Bset.exist(2) << std::endl;
}
上面的位图只适用于存在或者不存在两种状态,那怎么表示多种状态呢?有这么一道题:给定100亿个整数,设计算法找到只出现一次的整数。所以某个数可能出现2次、3次或者多次,此时就需要对位进行扩展。
template<size_t N>
class TowBiteSet
{
public:
void Set(size_t n)
{
//00 ---- 01
if (!_bit1.exist(n) && !_bit2.exist(n))
{
_bit2.set(n);
}
//01 ---- 10
else if (!_bit1.exist(n) && _bit2.exist(n))
{
_bit1.set(n);
_bit2.reset(n);
}
//10表示出现两次或者两次以上,不需要处理
}
void PrintOnceNum()
{
for (size_t i = 0; i < N; ++i)
{
if (!_bit1.exist(i) && _bit2.exist(i))//01
cout << i << " ";
}
cout << endl;
}
private:
fl::Biteset<N> _bit1;//表示第二位
fl::Biteset<N> _bit2;//表示第一位
};
如果一个数所对应的为01,那么它再次出现时,需要将对应的位改为10,其实类似于进位操作。
代码测试:
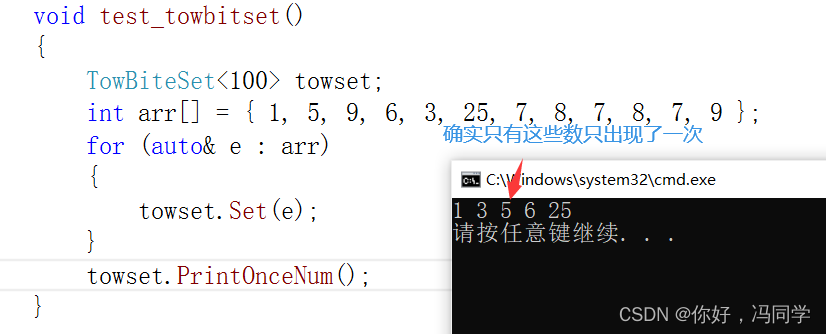
void test_towbitset()
{
TowBiteSet<100> towset;
int arr[] = { 1, 5, 9, 6, 3, 25, 7, 8, 7, 8, 7, 9 };
for (auto& e : arr)
{
towset.Set(e);
}
towset.PrintOnceNum();
}
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
位图只能用于整数的状态判断,如果需要判断小数或者字符串的状态呢?此时就需要用到布隆过滤器。那怎么实现的呢?粗略的讲就是将数据通过单个或者多个哈希函数映射到单个或多个位上。
优点:
缺点:
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录,对于这样的场景就使用到了布隆过滤器。类似的还有:
布隆过滤器实际上是一个二进制数组加上多个随机的哈希函数。将数据通过哈希函数计算映射到对应的比特位中。如果对应的比特位已经被置为1,那么就通过另外一个哈希函数计算映射到另一个比特位,但哈希函数的个数是有限的,因此在判断数据的状态时会存在一定的误判。
如下就是一个简单的布隆过滤器示意图:
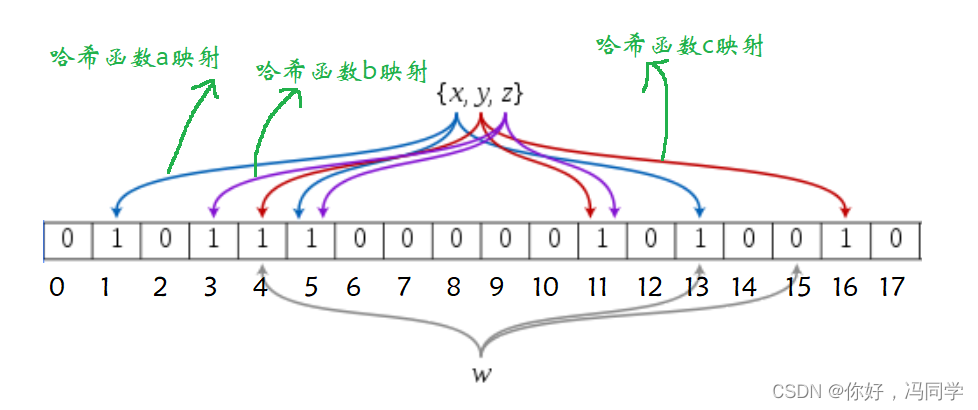
假设现在需要判断一个数据a和数据b是否存在,假设a通过哈希函数a,b,c映射到了位置3、位置5和位置13,这三个位置的状态都为存在,此时我们就认为数据a存在,但实际上是不存在的,这就是布隆过滤器的误判行为。假设b通过哈希函数a,b,c映射到了位置7、位置8和位置9,这三个位置的状态都为不存在,那么数据b肯定不存在。
所以:对于数据存在可能会存在误判,对于数据不存在,一定不会存在误判
布隆过滤器的误判是无法避免的,但是可以通过多种手段将误判率降低,比如布隆过滤器的长度,增加哈希函数的个数来映射多个位置。那么到底如何权衡布隆过滤器的长度和哈希函数的个数呢?有人通过计算给出了这么一个公式:

k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
虽然影响误判率的因素有3个,但我觉得最影响的还是布隆过滤器的长度
为什么是这样,本人学识浅薄,并不知道其中的奥秘。
#pragma once
#include<bitset>
#include<string>
#include<iostream>
using namespace std;
//哈希函数1
struct BKDRHash
{
size_t operator()(const string& s)
{
//BKDR哈希
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
//哈希函数2
struct APHash{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));
}
}
return hash;
}
};
//哈希函数3
struct DJBHash{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template<size_t N,
class K = string,
class HashFunc1 = BKDRHash,
class HashFunc2 = APHash,
class HashFunc3 = DJBHash>
class BloomFilter
{
public:
void Set(const K& key)
{
size_t len = 4 * N;
size_t index1 = HashFunc1()(key) % len;
size_t index1 = HashFunc2()(key) % len;
size_t index1 = HashFunc3()(key) % len;
_bs.set(index1);
_bs.set(index2);
_bs.set(index3);
}
//判断数据是否存在,存在可能会有误判
void Test(const K& key)
{
size_t len = 4 * N;
size_t index1 = HashFunc1()(key) % len;
if (_bs.test(index1) == false)
return false;
size_t index2 = HashFunc2()(key) % len;
if (_bs.test(index2) == false)
return false;
size_t index3 = HashFunc3()(key) % len;
if (_bs.test(index3) == false)
return false;
//当3个位置都存在时才存在,但是可能会误判
return true;
}
private:
bitset<4*N> _bs;//根据前面的公式可以算出1个数据对应4个比特位
};
这里我们没有写删除,为什么呢?请看下图:
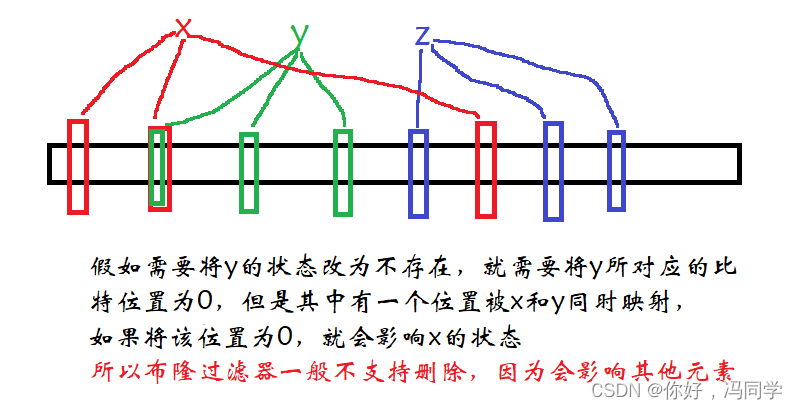
如果要实现删除也不是不行。使布隆过滤器的每个标记位用多个比特位表示,用来计算有多少个数据映射到该位,相当于引用计数。但整体而言,消耗的空间也就变多了,布隆过滤器的优势也下降了。
给定两个文件A和B,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?请给出精确算法
假如这100亿个query的大小为100个G,两个文件加起来就200个G
方法1:将每个文件分为大小相等的200个小文件,每个小文件占500M,将A
中的小文件分别和B中的小文件进行一一求交集,那么将求20100(200+199+…+2+1)次,计算量也是相当庞大,主要原因还是相同的query可能在不同的小文件中,例如一个在A1中,一个在B10中。
方法2:对于方法1的情况,可以使用哈希切分。将相近的query放在编号相同的小文件中,这样只需要A1和B1比较,A2和B2比较…一共只需要比较200次即可。
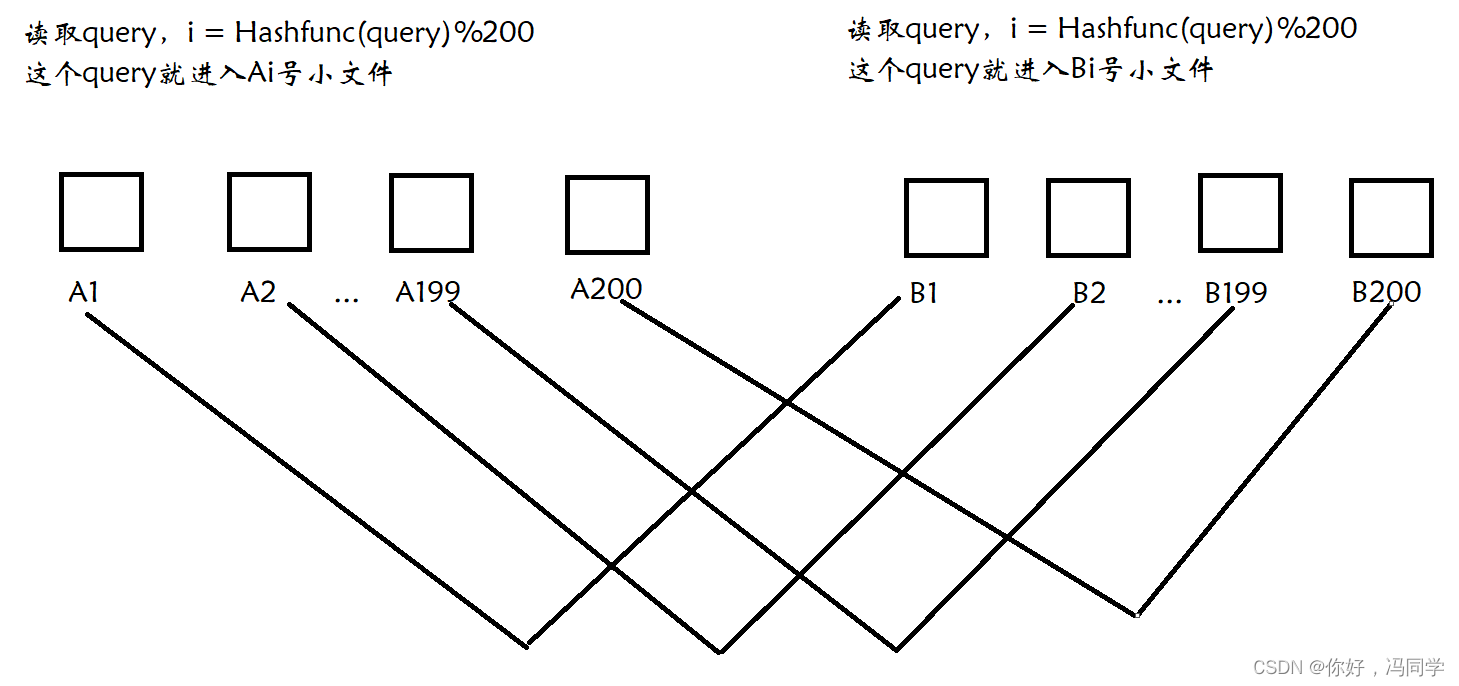
但这样还存在一个问题,就是单个文件太大,可能会超过1G,那么此时就需要换个哈希函数再切分,直到满足不再超过1G为止。
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解
我有一个名为Post的类,我需要能够适应以下场景:如果用户选择了一个类别,则只显示该类别的帖子如果用户选择了一种类型,则只显示该类型的帖子如果用户选择了一个类别和类型,则只显示该类别中该类型的帖子如果用户没有选择任何内容,则显示所有帖子我想知道我的Controller是否不可避免地会因大量条件语句而显得粗糙...这是我解决此问题的错误方法-有谁知道我如何才能做到这一点?classPostsController 最佳答案 您最好遵循“胖模型,瘦Controller”的惯例,这意味着您应该将这种逻辑放在模型本身中。Post类应该能够报告
我在搜索我的值是方法的散列时遇到问题。我只是不想运行plan_type与键匹配的方法。defmethod(plan_type,plan,user){foo:plan_is_foo(plan,user),bar:plan_is_bar(plan,user),waa:plan_is_waa(plan,user),har:plan_is_har(user)}[plan_type]end目前如果我传入“bar”作为plan_type,所有方法都会运行,我怎么能只运行plan_is_bar方法呢? 最佳答案 这个变体怎么样?defmethod
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu