目录
进入AR1和AR3分别配置安全提议(AR1与AR3需做相同的配置)
分别在AR1和AR3上创建安全策略,在安全策略中就可以调用之前所配置的acl和安全提议(均选择手工配置)
配置SA(安全联盟),实现IPsec对等体之间相关安全参数的协商
我的第二期博文承接上一期博文为大家带来IPsec VPN 的实际配置,在本期博文中我会详细展示如和采用隧道模式来配置IPsec VPN(本次实验ah协议和esp协议结合使用)。话不多说,一起来看吧!
软件ENSP
模拟设备:两台PC,三台AR1220路由器
注意事项:只有在AR型的路由才能在接口下调用ACL,AR1220必须使用千兆以太网接口,因为ethernet下无法配置接口IP地址。AR1220如果无法启动,最可能有以下两种原因:电脑配置过低或没有进行注册。第二种在工具-注册设备当中进行注册,至于第一种。。。我学校公共机房的电脑都能启,所以你们的电脑也应该没有问题。
网络拓扑如下:
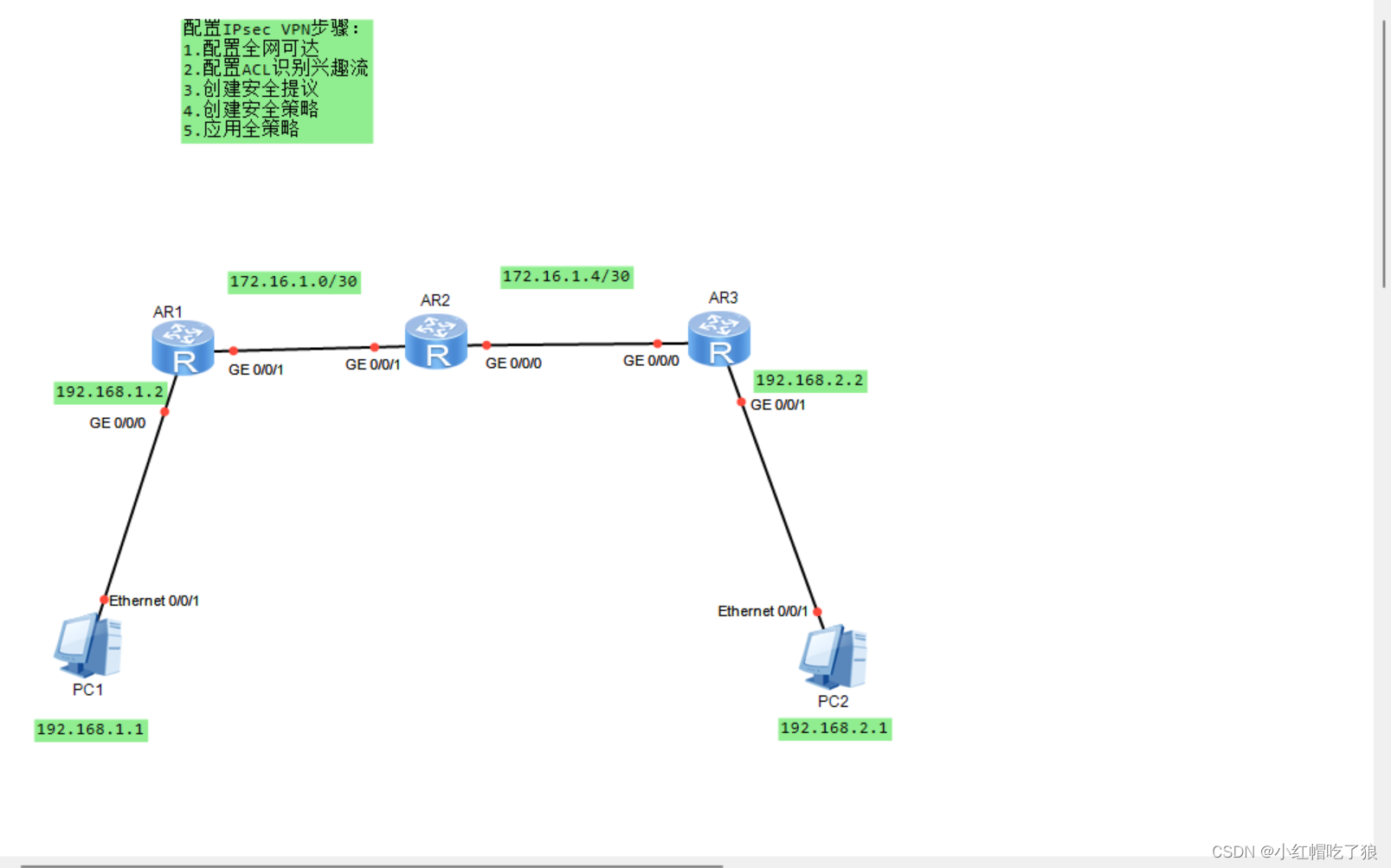
AR1-GE 0/0/1 IP:172.16.1.1
AR2-GE 0/0/1 IP:172.16.1.2 AR2-GE 0/0/0 IP:172.16.1.5
AR3-GE 0/0/0 IP:172.16.1.6
配置全网可达比较简单,分为两个步骤:1.配置两台PC和三台路由器每个接口的IP地址。2.在三台路由器上配置静态路由。这里需要注意的是,我们在AR1和AR3上只需分别配置一个指向AR3的默认路由就可以了。
AR1:

AR3:

AR2上进行常规配置就可以了,最后实现PC1ping通PC2
因为在AR1和AR3之间实现采用隧道模式的安全通信,所以需分别在AR1和AR3上配置ACL,配置acl识别兴趣流目的是:定义谁可以使用IPsec技术。
AR1:(设置步长为五,也可以不设)

192.168.1.0 / 192.168.2.0后面的 0.0.0.255 其中 0代表的是精确匹配,255表示从0~255的数都匹配。
AR3:

AR1:(设置协议封装模式为隧道模式,AR3做同样的操作这里就不单独演示了)

设置使用ah-esp(ah协议和esp协议结合使用)

设置ah的认证算法和esp的认证和加密算法
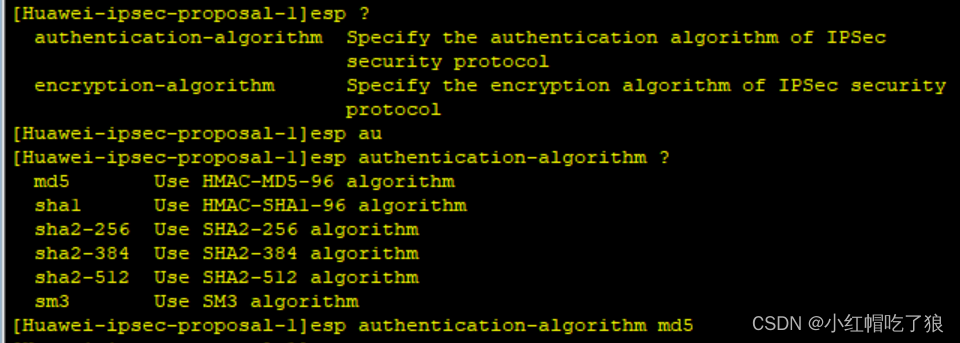
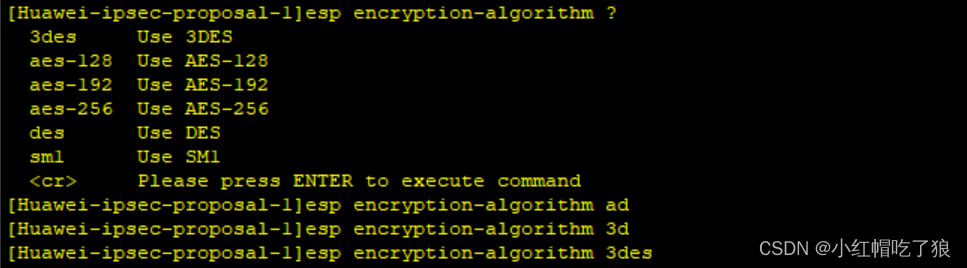
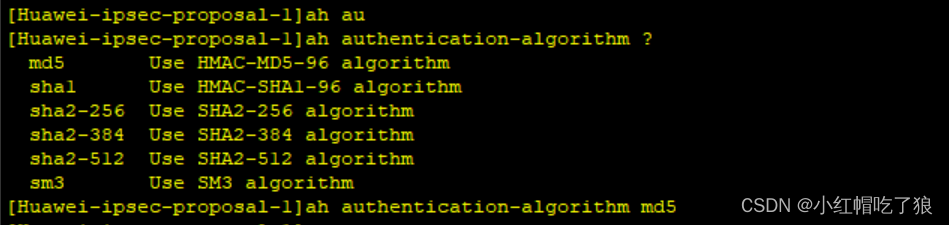
这里的加密算法随便选一个都可以,但在AR3配置安全提议时选择必须和AR1上相同。
AR1:

调用之前配置的acl和proposal

配置IPsec对等体

(1)配置esp协议出入接口密钥

(2)配置ah协议出入接口密钥

注意:在AR2上的配置需和AR1上的相反即AR1上的出接口密钥为AR2上的入接口密钥
[Huawei-ipsec-policy-manual-huawei-1]sa string-key inbound esp cipher huawei
[Huawei-ipsec-policy-manual-huawei-1]sa string-key outbound esp cipher huawei
[Huawei-ipsec-policy-manual-huawei-1]sa string-key inbound ah cipher huawei
[Huawei-ipsec-policy-manual-huawei-1]sa string-key outbound ah cipher huawei
注意:在AR2上配置的共享认证密钥也需与AR1的配置相反,即AR1上的出/入为AR2上的入/出
AR2上做相同的配置即可,这里就不再演示了
在AR1和AR3上做相同的配置即可
[Huawei-GigabitEthernet0/0/1]ipsec policy huawei
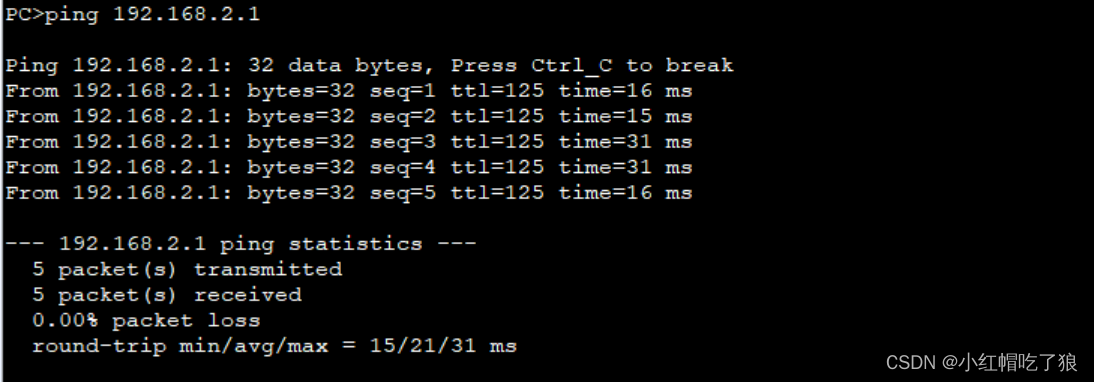
可以看到协议字段是esp说明实验成功,源ip和目的ip都被替换了客户机真实IP地址被隐藏,符合理论知识。
本篇博文仅仅为大家介绍了ipsec VPN 隧道模式的实际配置,若各位读者有所补充请一定私信我,我非常希望可以和大家一起交流,学习。
下期将为大家带来OSPF(最短路径优先)技术的理论知识。
最后,由衷感谢各位读者!
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl