
目录
前段时间研究了knative,今天专门来讲一下Knative 的 Serving模块
三言两语,不如细心探索。
本文理论偏多,希望读完此文,能帮助读者对Knative Serving组件有一个初步的了解
文章标记颜色说明:
- 黄色:重要标题
- 红色:用来标记结论
- 绿色:用来标记一级论点
- 蓝色:用来标记二级论点
knative的介绍,在这篇文章,如果想详细了解的话,可以阅读一下
我们来简单回忆一下Knative是什么。
Knative 发展历程如下

Knative构建在Kubernetes、Istio、Container的基础上,以K8S的CRD形式存在。
- 基础设施:Kubernetes作为基础设施:容器编排,解决应用编排和运行环境
- 通信设施:Isito作为通信基础设施层,保证服务的运行可检测、可配置、可追踪
- 模板+环境:Knative使用应用模板和统一的运行环境来标准化服务的构建、部署和管理
如下图所示:
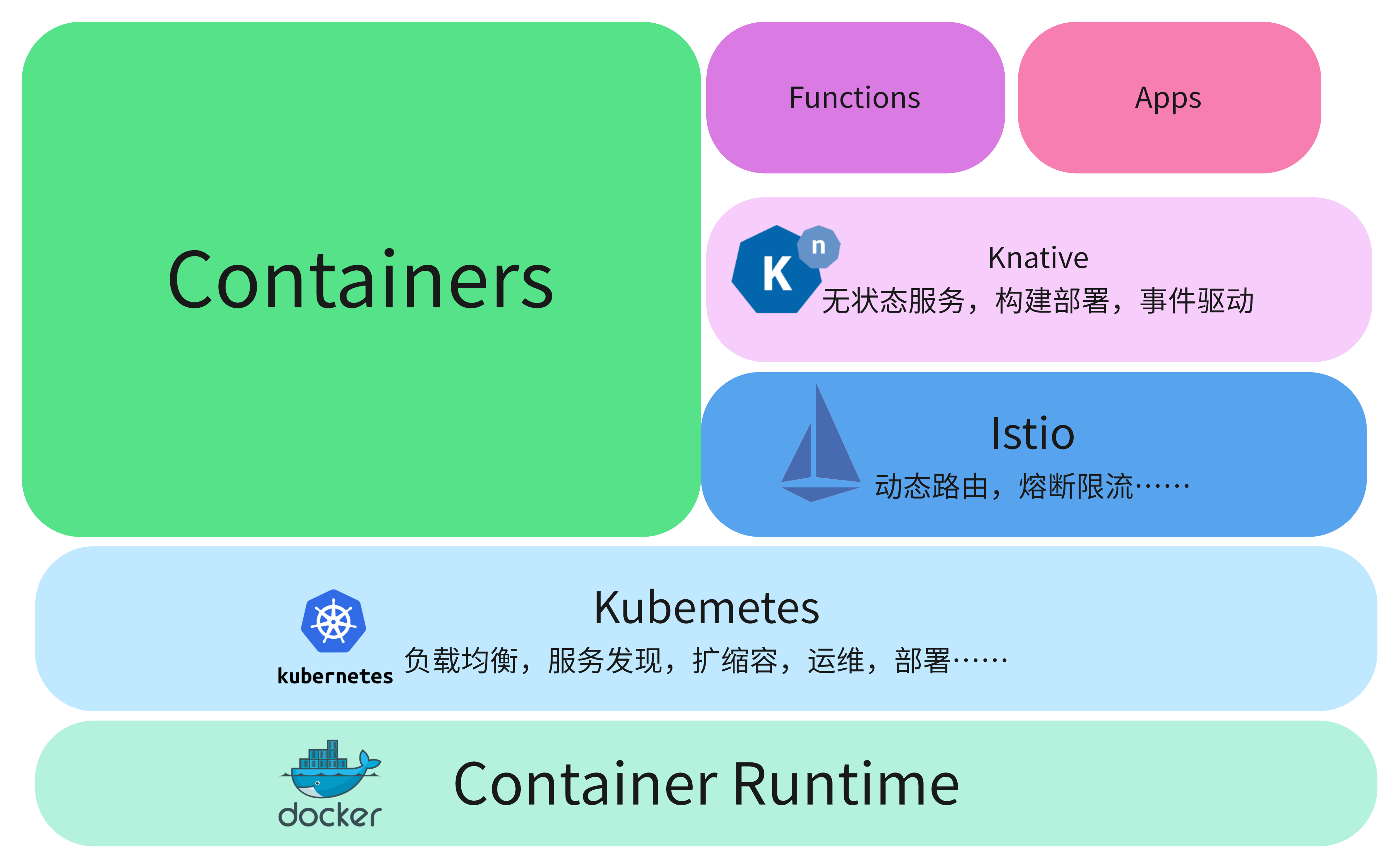
Knative 将kubernetes和istio的复杂度进行抽象和隔离,解决了繁琐的构建,部署,服务治理步骤,并且基于开放标准使得服务变得可移植
Knative 组件包含两个大的领域,分别是Serving和Event。现在讲一下Serving部分。
Serving:即服务
基于Kubernetes的crd提供缩容至零、请求驱动的计算功能。它本质上是无服务器平台的执行和扩展组件。主要有以下特性:
- 模型抽象:更高级层的抽象化,对象模型更易于理解。可快速部署无服务容器
- 自动扩容:基于 HTTP 请求的无缝自动扩缩,自动扩缩容机制,支持缩容到零
- 网络集成:自动集成网络和服务网格
- 可扩展:连接日志记录、监控、等其他平台
Knative Serving支持容器化的工作负载。
1.FaaS:传统FaaS的函数应用。
通过将传统FaaS平台运行时框架与函数应用一起封装到容器中,实现对FaaS函数应用的支持。
2.单一职责-微服务:满足单一职责原则、可独立部署升级的服务。
这一点上面,Knative很适合用来部署和管理微服务。
3.无状态-应用:主要指传统无状态的单体应用。
虽然Knative不是运行传统应用的最佳平台,但支持传统无状态应用的部署。
Knative Serving 有四个主要资源:
- Service(服务)
- Route(路由)
- Configuration(配置)
- Revision(修订)
Knative Serving定义了一套CRD对象。这些对象用于定义和控制Serverless工作负载在集群中的行为,其关系如下:
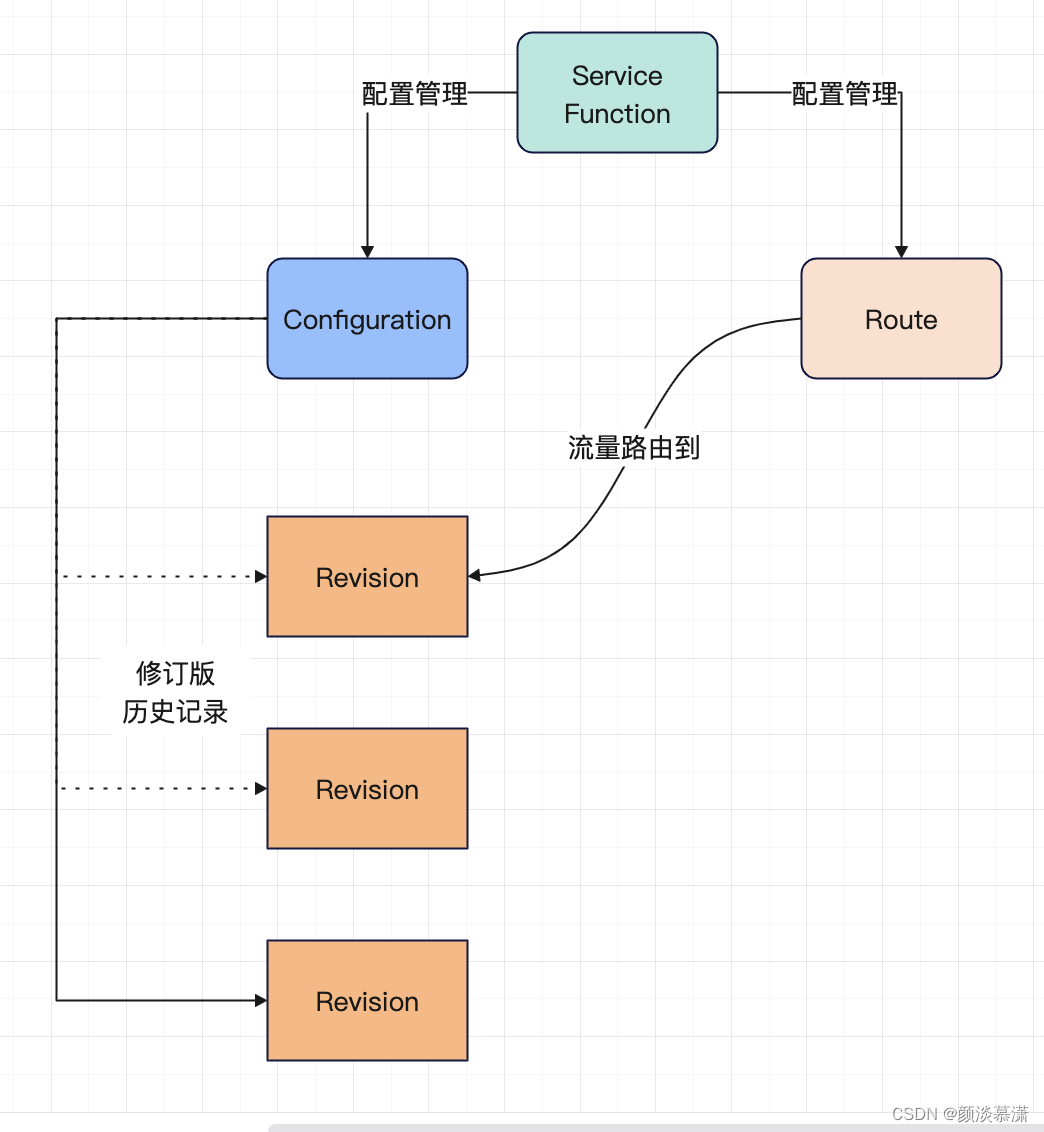
- Service:
service.serving.knative.dev资源会自动管理工作负载的整个生命周期。
它控制其他对象的创建,以确保应用为服务的每次更新都具有路由,配置和新修订版。
可以将服务定义为始终将流量路由到最新修订版或固定修订版。
创建服务时,它必须创建并拥有与服务同名的配置和路由、更新规范、元数据、标签和元数据。必须将服务注释复制到适当的配置或路由中,如下所示:
- 元数据更改必须复制到配置和路由。
- 路由和配置上的dev/service标签必须设置为服务的名称。
- 必须移除上面未指定的配置和路线上的其他标签和注释。
- 特定规范字段与配置和路由中相应字段的映射。
同样,服务必须根据其拥有的路由和配置的相应状态更新其状态字段。除一般就绪条件外,服务必须包括ConfigurationReady和RoutesReady条件;也可能存在其他条件。
- Route:
route.serving.knative.dev资源将网络端点映射到一个或多个修订版。可以通过几种方式管理流量,包括部分流量和命名路由。
- Configuration:
configuration.serving.knative.dev资源维护部署的所需状态。
它在代码和配置之间提供了清晰的分隔,并遵循了十二要素应用程序方法。
修改配置会创建一个新修订。
十二要素应用程序方法
- One codebase, one application - 一个代码库,一个应用程序
- Dependency management - 依赖管理
- Design, build, release, and run - 设计、构建、发布和运行
- Configuration, credentials, and code - 配置、证书和代码
- Logs - 日志
- Disposability - 易处理
- Backing services - 后端服务
- Environment parity - 环境等价
- Administrative processes - 管理进程
- Port binding - 端口绑定
- Stateless processes - 无状态进程
- Concurrency - 并发性
为了云原生应用程序而新增加3个因素:
- API first - API 优先
- Telemetry - 遥测
- Authentication and authorization - 认证和授权
- Revision:
reversion.serving.knative.dev资源是对工作负载进行的每次修改的代码和配置的时间点快照。
修订是不可变的对象,可以保留很长时间。也可以根据传入流量自动缩放实例数。
有关更多信息,请参见配置自动缩放器。
Knative Serving组件包含k8s的
- 4个kubernetes Service
- 2个Deployment
构成了Serving的整体管理能力。
1.autoscaler:接收请求指标数据并调整需要的Pod数量以处理流量负载。
2.activator:负责为不活跃状态的修订版接收并缓存请求,同时报告指标数据给autoscaler。在autoscaler扩展修订版之后,它还负责将请求重试到修订版
3.controller:协调所有公共Knative对象,自动扩展CRD。
当用户请求一个Knative service给Kubernetes API,controller将创建对应配置和路由,并将配置转换为revision,同时将revision转化为deployment和KPA。
4.webhook:拦截所有Kubernetes API调用以及所有CRD的插入和更新操作,用来设置默认值,拒绝不一致和无效的对象,验证和修改Kubernetes API调用。
1.networking-certmanager:协调集群的ingrese为证书管理对象。
2.networking-istio:协调集群的ingress为Istio的虚拟服务。
Serverless的重要特点之一就是事件驱动计算。
当没有请求时,系统不会分配相应的资源给服务。
因此,Knative Serving支持从零开始扩容,也支持缩容到零。
在初始状态下,修订版的副本是不存在的。客户端发起请求时,系统要完成工作负载的激活过程。
Knative的扩缩容的流程如下图所示:
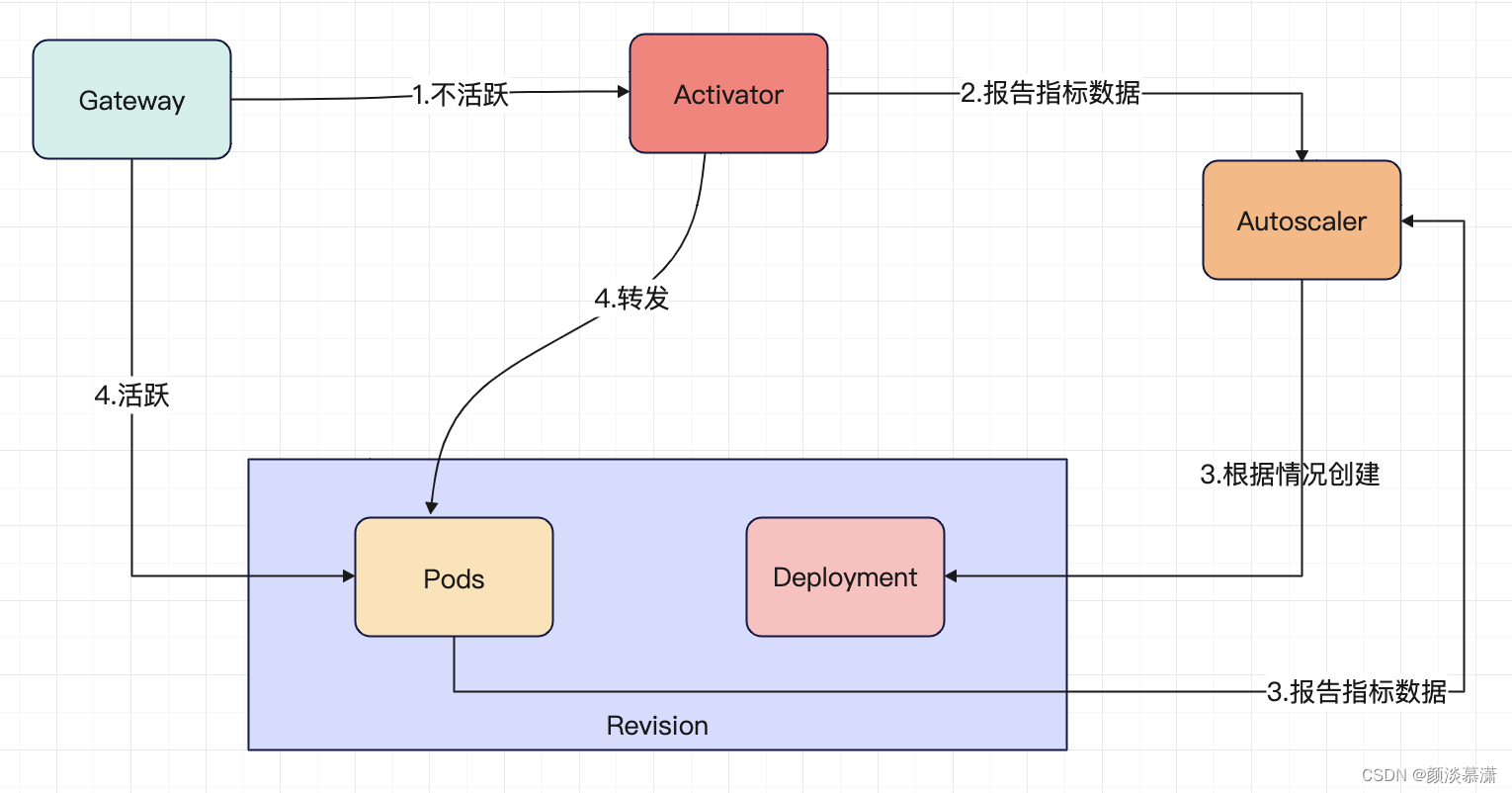
初次请求:
1.请求通过入口网关转发给Activator
2.Activator负责为不活跃状态的修订版接收并缓存请求,同时报告指标数据给Autoscaler;3.Autoscaler会创建修订版的Deployment对象;Deployment对象根据Autoscaler设定的扩展副本数创建相应数量的Pod副本。
一旦Pod副本的状态变为Ready,Activator会将缓存的客户端请求转发给对应的Pod副本。
4.Gateway然后会将新的请求直接转发给相应的Pod副本,不再转发给Activator。
缩容到零的流程:
当一定时间周期内没有请求时,Autoscaler会将Pod副本数设置为零,回收Pod所占资源。
同时Gateway会将后续请求路由到Activator,如果后续请求出现可以触发初次请求流程。
持续请求流程:
修订版副本中的Queue Proxy容器会不断报告指标数据给Autoscaler,Autoscaler会根据当前的指标数据情况以及扩缩容算法不断调整修订版的副本数量。
Queue Proxy:
Knative服务对应的Pod里有两个容器,分别是
- User Container
- Queue Proxy
User Container:为Knative服务中定义的业务容器,包含应用程序及其依赖的运行环境。Queue Proxy:是系统容器,以Sidecar方式存在。
Knative Serving为每个Pod注入Queue代理容器 (queue-proxy)。
queue-proxy容器负责向Autoscaler报告用户容器流量指标。
Autoscaler接收到这些指标之后,会根据流量指标及相应的算法调整Deployment的Pod副本数量,从而实现自动扩缩容。
扩缩容算法:
Autoscaler 默认基于Pod接收到的并发请求数扩缩容资源。
Pod并发请求数的目标值(target)默认为100。
计算公式是:Pod数=并发请求总数/Pod并发请求数的目标值。
如果Knative服务中配置并发请求数的目标值为10,那么如果加载了50个并发请求到Knative服务,Autoscaler 就会创建了5个 Pod。
Autoscaler实现了两种模式的缩放算法:
- 稳定模式(Stable)
- 恐慌模式(Panic)
稳定模式:
在稳定模式下,Autoscaler自动调整Deployment的大小,以实现每个Pod所需的平均并发数。
Pod的并发数是根据60秒窗口期内接收到的所有数据请求的平均数来计算得出。
恐慌模式:
1.Autoscaler计算60秒窗口期内的平均并发数,系统需要60秒内稳定在所需的并发级别。
2.同时,Autoscaler 也会计算6秒的窗口期
当6秒窗口期内达到了目标并发数的2倍,则会进入恐慌模式。
在恐慌模式下,Autoscaler将在时间更短、对请求更敏感的紧急窗口上工作。一旦紧急情况持续 60 秒,Autoscaler 将返回初始的 60 秒稳定窗口。
Knative Serving组件是Knative的核心组件,它完成了一个Serverless计算平台最重要的能力,即服务的部署与弹性伸缩。
Knative Service资源对象集成了配置管理、版本管理、流量控制以及扩缩容控制,极大地简化了Serverless的服务管理。
容器的主要限制:
- 必须是无状态的HTTP服务
- 允许挂载configmap,secret,projected,但不允许挂载持久卷pvc
- 一个Service只能有一个用户容器
若表达不当的地方,欢迎各位大佬评论区留言讨论~
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我使用irb。下面是我写的代码。“斧头”..“bc”我期待"ax""ay""az""ba"bb""bc"但结果只是“斧头”..“bc”我该如何纠正?谢谢。 最佳答案 >puts("ax".."bc").to_aaxayazbabbbc 关于ruby-从结束值创建一系列字符串,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7617092/
目录SpringBootStarter是什么?以前传统的做法使用SpringBootStarter之后starter的理念:starter的实现: 创建SpringBootStarter步骤在idea新建一个starter项目、直接执行下一步即可生成项目。 在xml中加入如下配置文件:创建proterties类来保存配置信息创建业务类:创建AutoConfiguration测试如下:SpringBootStarter是什么? SpringBootStarter是在SpringBoot组件中被提出来的一种概念、简化了很多烦琐的配置、通过引入各种SpringBootStarter包可以快速搭建出一
使用RubyonRails,我使用给定的增量(例如每30分钟)用时间填充“选择”。目前我正在YAML文件中写出所有的可能性,但我觉得有一种更巧妙的方法。我想我想提供一个开始时间、一个结束时间、一个增量,并且目前只提供一个名为“关闭”的选项(想想“business_hours”)。所以,我的选择可能会显示:'Closed'5:00am5:30am6:00am...[allthewayto]...11:30pm谁能想出更好的方法,或者只是将它们全部“拼写”出来的最佳方法? 最佳答案 此答案基于@emh的答案。defcreate_hour
有道无术,术尚可求,有术无道,止于术。本系列SpringBoot版本3.0.4本系列SpringSecurity版本6.0.2本系列SpringAuthorizationServer版本1.0.2源码地址:https://gitee.com/pearl-organization/study-spring-security-demo文章目录前言1.OAuth2AuthorizationServerMetadataEndpointFilter2.OAuth2AuthorizationEndpointFilter3.OidcProviderConfigurationEndpointFilter4.N
我在/usr/local/lib中安装了一些本地库。我现在正在尝试安装一个需要这些的gem,以便正确构建,但是gem构建失败,因为它找不到图书馆。gem的extconf.rb文件试图确认它可以找到库have_library()但由于某种原因失败了。我尝试设置一堆环境变量,但似乎没有任何效果:irb(main):003:0>require'mkmf'=>trueirb(main):004:0>have_library('gecodesearch')checkingformain()in-lgecodesearch...no=>falseirb(main):005:0>ENV['LD_LI
我使用geokit和geokit-railsgemforrails有一段时间了,但我还没有找到答案的一个问题是如何找到一组点的计算聚合中心。我知道如何计算两点之间的距离,但不会超过2。我的理由是,我在同一个城市中有一系列的点……一切都完美的城市会有一个我可以使用的中心,但有些城市,比如柏林没有一个完美的中心。他们有多个中心,我只想使用我数据库中的所有地点列表来计算特定分布的中心。还有其他人遇到过这个问题吗?有什么建议吗?谢谢 最佳答案 之前从未使用过Geokit,这个操作背后的数学原理相对容易自己实现。假设这些点由纬度和经度组成,您