 作者列表:王治海*,李希君*,王杰**,匡宇飞,袁明轩,曾嘉,张勇东,吴枫论文链接:https://openreview.net/forum?id=Zob4P9bRNcK开源数据集:https://drive.google.com/drive/folders/1LXLZ8vq3L7v00XH-Tx3U6hiTJ79sCzxY?usp=sharingPyTorch 版本开源代码:https://github.com/MIRALab-USTC/L2O-HEM-TorchMindSpore 版本开源代码:https://gitee.com/mindspore/models/tree/master/research/l2o/hem-learning-to-cut天筹(OptVerse)AI求解器:https://www.huaweicloud.com/product/modelarts/optverse.html
作者列表:王治海*,李希君*,王杰**,匡宇飞,袁明轩,曾嘉,张勇东,吴枫论文链接:https://openreview.net/forum?id=Zob4P9bRNcK开源数据集:https://drive.google.com/drive/folders/1LXLZ8vq3L7v00XH-Tx3U6hiTJ79sCzxY?usp=sharingPyTorch 版本开源代码:https://github.com/MIRALab-USTC/L2O-HEM-TorchMindSpore 版本开源代码:https://gitee.com/mindspore/models/tree/master/research/l2o/hem-learning-to-cut天筹(OptVerse)AI求解器:https://www.huaweicloud.com/product/modelarts/optverse.html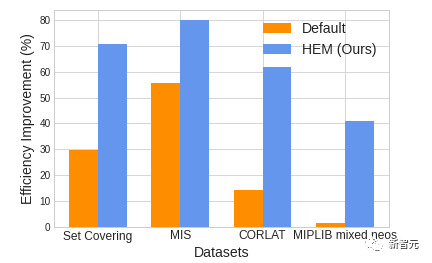 图1. HEM 与求解器默认策略(Default)求解效率对比,HEM 求解效率最高可提升 47.28%
图1. HEM 与求解器默认策略(Default)求解效率对比,HEM 求解效率最高可提升 47.28%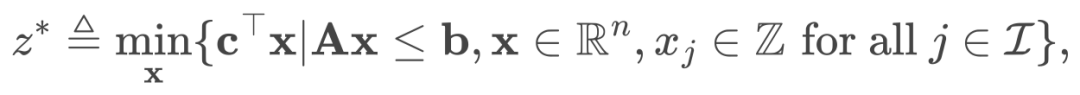 (1)
(1)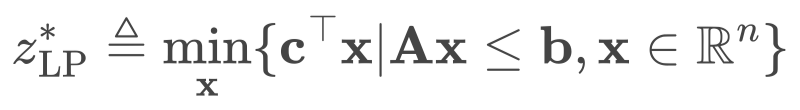 (2)
(2)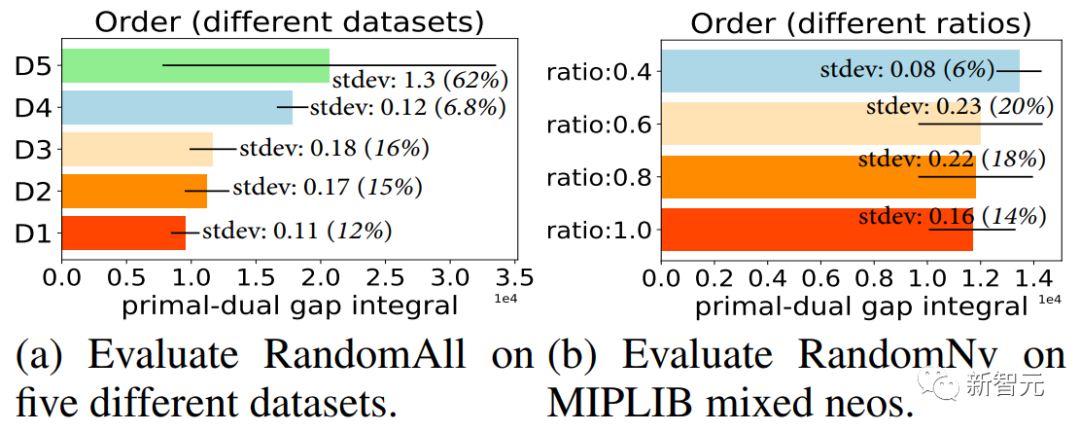 图2. 每一个柱子代表在求解器中,选定相同的一批割平面,以10轮不同的顺序添加这些选定割平面,求解器最终的求解效率的均值,柱子中的标准差线代表不同顺序下求解效率的标准差。标准差越大,代表顺序对求解器求解效率影响越大。
图2. 每一个柱子代表在求解器中,选定相同的一批割平面,以10轮不同的顺序添加这些选定割平面,求解器最终的求解效率的均值,柱子中的标准差线代表不同顺序下求解效率的标准差。标准差越大,代表顺序对求解器求解效率影响越大。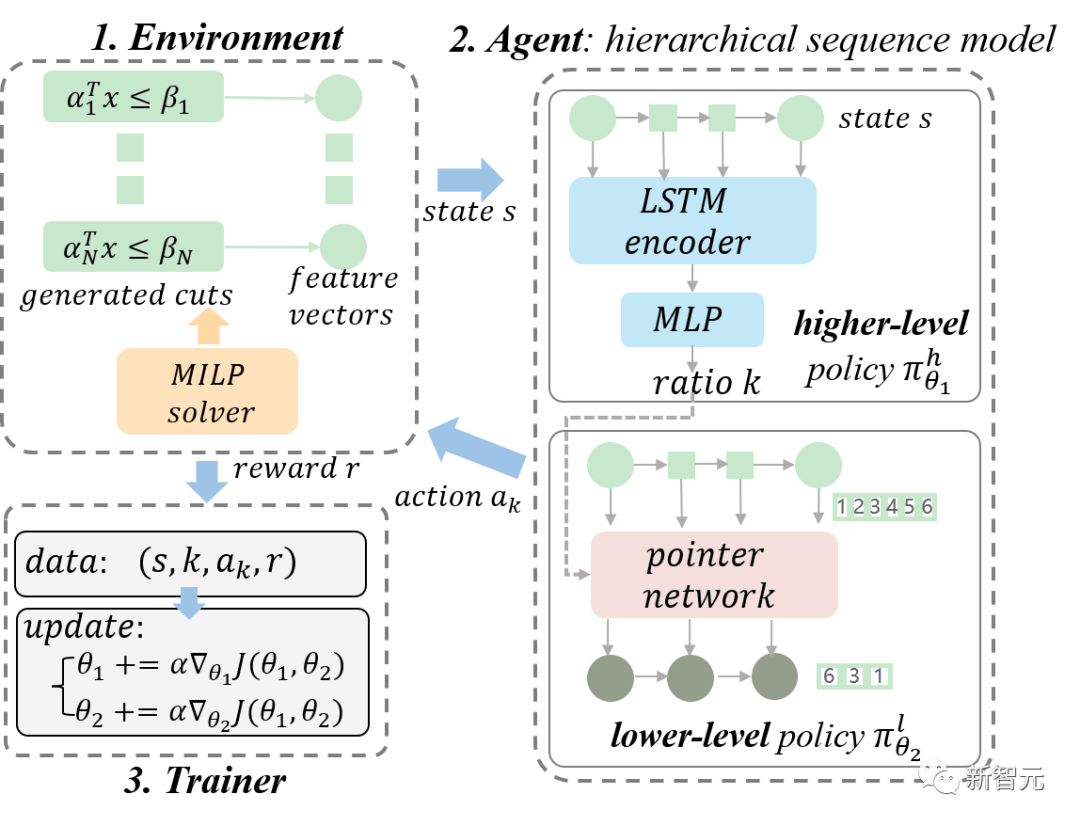 图3. 我们所提出的整体 RL 框架图。我们将 MILP 求解器建模为环境,将 HEM 模型建模为智能体。我们通过智能体和环境不断交互采集训练数据,并使用分层策略梯度训练 HEM 模型。
图3. 我们所提出的整体 RL 框架图。我们将 MILP 求解器建模为环境,将 HEM 模型建模为智能体。我们通过智能体和环境不断交互采集训练数据,并使用分层策略梯度训练 HEM 模型。
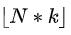 ,其中
,其中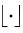 表示向下取整函数。我们定义
表示向下取整函数。我们定义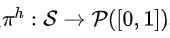 。
其次,下层策略学习选择给定大小的有序子集。下层策略可以定义
。
其次,下层策略学习选择给定大小的有序子集。下层策略可以定义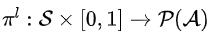 ,其中
,其中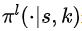 表示给定状态S和比例K的动作空间上的概率分布。具体来说,我们将下层策略建模为一个序列到序列模型(sequence to sequence model, sequence model)。
最后,通过全概率定律推导出 cut 选择策略,即
表示给定状态S和比例K的动作空间上的概率分布。具体来说,我们将下层策略建模为一个序列到序列模型(sequence to sequence model, sequence model)。
最后,通过全概率定律推导出 cut 选择策略,即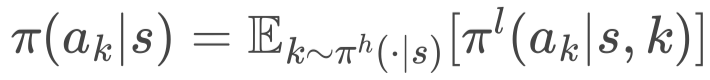
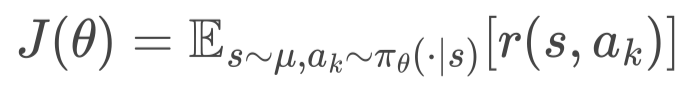 图4. 分层策略梯度。我们以此随机梯度下降的方式优化 HEM 模型。
图4. 分层策略梯度。我们以此随机梯度下降的方式优化 HEM 模型。
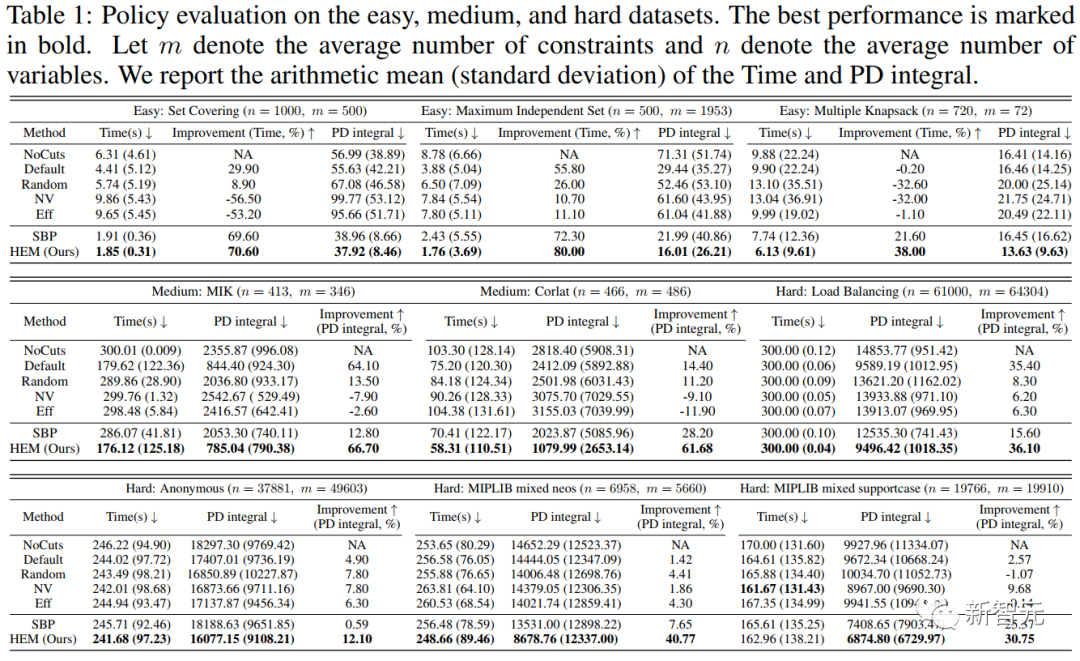 图5. 对easy、medium 和 hard 数据集的策略评估。最优性能我们用粗体字标出。以m表示约束条件的平均数量,n表示变量的平均数量。我们展示了求解时间和primal-dual gap 积分的算术平均值(标准偏差)。
图5. 对easy、medium 和 hard 数据集的策略评估。最优性能我们用粗体字标出。以m表示约束条件的平均数量,n表示变量的平均数量。我们展示了求解时间和primal-dual gap 积分的算术平均值(标准偏差)。 我这样做(在我看来):#myUserisaUserinActiveRecordwith:has_many:postsmyUser.posts.eachdo|post|end如果用户有10个帖子,这会调用10次数据库吗?这些循环应该像(不那么漂亮)吗?:myPosts=myUser.postsmyPosts.eachdo|post|endHere是我测试的ruby文件的粘贴箱。编辑修改了粘贴箱。这让我想起了Java中的代码for(inti=0;i应该是(除非数组被修改)for(inti=0,len=someExpensiveFunction();i我错过了什么吗?我看到一堆Rails
catch在Ruby中是为了跳出深度嵌套的代码。在Java中,例如Java用于处理异常的try-catch可以实现同样的效果,但它被认为是糟糕的解决方案,而且效率也很低。在用于处理异常的Ruby中,我们有begin-raise-rescue,我认为将它用于其他任务也很昂贵。Ruby的catch-throw真的是比begin-raise-rescue更有效的解决方案吗?或者还有其他原因可以使用它来打破嵌套block而不是begin-raise-rescue? 最佳答案 除了是摆脱控制结构的“正确”方式之外,catch-throw也明显
ruby中有这样的东西吗?send(+,1,2)我想让这段代码看起来不那么冗余ifop=="+"returnarg1+arg2elsifop=="-"returnarg1-arg2elsifop=="*"returnarg1*arg2elsifop=="/"returnarg1/arg2 最佳答案 是的,只需像这样使用send(或者更好的是public_send):arg1.public_send(op,arg2)这是可行的,因为Ruby中的大多数运算符(包括+、-、*、/、andmore)只需调用方法。所以1+2与1.+(2)相同
情况:我正在编写一个程序来求解素数。我需要解决4x^2+y^2=n的问题,其中n是一个已知变量。是的,必须是Ruby。我愿意在这个项目上花费大量时间。我最好自己编写方程式的求解算法,并将其作为该项目的一部分。我真正喜欢的是:如果任何人都可以向我提供指南、网站的链接,或者关于与求解代数方程特别相关的形式算法的构造的歧义消除,或者向我提供似乎你是读者它会帮助我完成任务。请不要建议我使用其他语言。如果您在回答之前接受我真的非常想这样做,我将不胜感激。该项目没有范围或时间限制,也不以营利为目的。这是为了我自己的教育。注意:我并不直接反对为Ruby实现和使用现存的数学库/模块/其他东西,但我更喜
我发现许多Rails应用程序主要针对企业、社交网络类型的Web应用程序。我看到有人将Ruby与一些出色的OOPS语言(如Java和C#)进行了比较,但我确实发现很难获得一些数学密集型应用程序。非常感谢任何知识渊博的输入(指向示例程序的链接等),其中轻松显示了语言的用法,就像快速启动或显示该语言如何用于各种数学问题一样。 最佳答案 不幸的是,Ruby并没有在数学和科学计算领域涉足太多。目前,有一个名为SciRuby的pre-alpha库它试图为Ruby带来更多面向数学的功能。他们正试图构建一个NumPy/SciPy等价物。SciRub
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们
目录1古彝文与古典保护2古文识别的挑战2.1西文与汉文OCR2.2古彝文识别难点3合合信息:古彝文保护新思路3.1图像矫正3.2图像增强3.3语义理解3.4工程技巧4总结1古彝文与古典保护彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。古彝文字义对照图(网络资料+邵文苑供图)古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、
【动态规划】一、背包问题1.背包问题总结1)动规四部曲:2)递推公式总结:3)遍历顺序总结:2.01背包1)二维dp数组代码实现2)一维dp数组代码实现3.完全背包代码实现4.多重背包代码实现一、背包问题1.背包问题总结暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!背包问题是动态规划(DynamicPlanning)里的非常重要的一部分,关于几种常见的背包,其关系如下:在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。1)动规四部曲:(1)确定dp数组及其下标的含义(2)确定递推公式(3)dp数组的初始化(4)确定遍历顺
论文常见数学符号及其含义(科研必备)返回论文和资料目录数学符号在数学领域是非常重要的。在论文中,使用数学符号可以使得论文更加简洁明了,同时也能够准确地描述各种概念和理论。在本篇博客中,我将介绍一些常见的数学符号及其含义(省去特别简单的符号),希望能够帮助读者更好地理解数学论文。高等数学∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi(求和符号):表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x2,…,xn中的所有数相加,例如∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x
集合和数组在运算效率上有何不同?例子:查找迭代包括? 最佳答案 在Ruby中,Set是使用底层的Hash编写的,它通常应该与Hash等效。因此:include?:集合复杂度为O(1),数组复杂度为O(n)枚举:两者都是O(n)删除:集合复杂度为O(1),数组复杂度为O(n)...等等如果您所说的“查找”是指按索引查找,我会注意到默认的Set实现是无序的,因此它不像数组那样支持该操作。 关于ruby-on-rails-ruby中集合操作与数组操作的效率,我们在StackOverflow上找