目录
四、动态SQL---choose和wen和otherwise标签
由于这是动态SQL,和先前得有些不一样,这里我们新建一个持久层接口UserMapper2和Mybatis映射文件UserMapper2.xml,测试类TestUserMapper2
持久层接口UserMapper2
package com.mybatisstudy.mapper; import com.mybatisstudy.pojo.User; public interface UserMapper2 { }
Mybatis映射文件UserMapper2.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.mybatisstudy.mapper.UserMapper2"> </mapper>
测试类TestUserMapper2
import com.mybatisstudy.mapper.UserMapper2; import com.mybatisstudy.pojo.User; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.InputStream; public class TestUserMapper2 { InputStream is = null; SqlSession session = null; UserMapper2 userMapper2 = null; //前置方法,不必重复代码 @Before public void before() throws Exception { System.out.println("前置方法执行·············"); // (1)读取核心配置文件 is = Resources.getResourceAsStream("SqlMapConfig.xml"); // (2)创建SqlSessionFactoryBuilder对象 SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); // (3)SqlSessionFactoryBuilder对象获取SqlSessionFactory对象 SqlSessionFactory factory = builder.build(is); // (4)SqlSessionFactory对象获取SqlSession对象 session = factory.openSession(); // (5)SqlSession对象获取代理对象 userMapper2 = session.getMapper(UserMapper2.class); } //后置方法,释放资源 @After public void after() throws Exception { System.out.println("后置方法执行·············"); session.close(); is.close(); } }
一个查询的方法的Sql语句不一定是固定的。比如电商网站的查询商品,用户使用不同条件查询,Sql语句就会添加不同的查询条件。此时就需要在方法中使用动态Sql语句。
<if> 标签内的Sql片段在满足条件后才会添加,用法为: <if test="条件"> 。例如:根据不同条件查询用户:
// 用户通用查询
List<User> findByCondition(User user);<!-- 动态_if -->
<select id="findByCondition" parameterType="com.mybatisstudy.pojo.User" resultType="com.mybatisstudy.pojo.User">
select * from user where 1 = 1
<if test="username != null and username.length()!=0">
and username like #{username}
</if>
<if test="sex != null and sex.length() != 0">
and sex = #{sex}
</if>
<if test="address != null and address.length() != 0">
and address = #{address}
</if>
</select>这里肯定就会有读者会问 where 后面为什么要加1 = 1,因为单单使用if标签的话,第一个条件是不用 and 关键字的,而后续的条件是需要加 and 关键字的。但是用户添加条件是随机的,没办法判断哪一个是第一个条件,因此在这里先添加1 = 1,就无需考虑后续的条件是否是第一个条件啦,但是后面还有更好的办法解决这个问题,在这里只是可以用这个方法解决目前的问题。
// 测试通用查询方法
@Test
public void testFindByCondition(){
User user = new User();
System.out.println("----------没有限制条件查询---------");
List<User> users = userMapper2.findByCondition(user);
users.forEach(System.out::println);
System.out.println("----------用户名带有name限制条件查询---------");
user.setUsername("%name%");
List<User> users1 = userMapper2.findByCondition(user);
users1.forEach(System.out::println);
System.out.println("----------姓名带有name和性别是man限制条件查询---------");
user.setSex("woman");
List<User> users3 = userMapper2.findByCondition(user);
users3.forEach(System.out::println);
}
if中的条件不能使用&&/||,而应该使用and/or
if中的条件可以直接通过属性名获取参数POJO的属性值,并且该值可以调用方法。
OK,上述的问题的彩蛋来了,就是这个where标签,
<where> 可以代替sql中的where 1=1 和第一个and,更符合程序员的开发习惯,使用 <where> 后的映射文件如下:
<!-- 动态_if用where -->
<select id="findByCondition" resultType="User" parameterType="User">
select * from user
<where>
<if test="username != null and username.length()!=0">
username like #{username}
</if>
<if test="sex != null and sex.length() != 0">
and sex = #{sex}
</if>
<if test="address != null and address.length() != 0">
and address = #{address}
</if>
</where>
</select>这里不用新增,直接测试即可

因此我们以后就不用添加那个什么1 = 1了
<set> 标签用在update语句中。借助 <if> ,可以只对有具体值的字段进行更新。 <set> 会自动添加set关键字,并去掉最后一个if语句中多余的逗号。
// 更新用户
void update(User user);<!-- 动态_set 更新用户 -->
<update id="update" parameterType="User">
update user
<set>
<if test="username != null and username.length()!=0">
username = #{username}
</if>
<if test="sex != null and sex.length() != 0">
and sex = #{sex}
</if>
<if test="address != null and address.length() != 0">
and address = #{address}
</if>
</set>
<where>
id = #{id}
</where>
</update>// 测试更新用户方法
@Test
public void testUpdate(){
User user = new User();
user.setId(4);
user.setUsername("man4");
userMapper2.update(user);
session.commit();
}
这里想整一个效果图,但是没想到帧率不够,最后居然绿屏了,但是不影响我们继续学习哈哈哈,理解到位即可害嗨嗨
这些标签表示多条件分支,类似JAVA中的 switch...case 。 <choose> 类似switch , <when> 类似 case , <otherwise> 类似 default ,用法如下:
这里就沿用那个通用查询方法即可
<select id="findByCondition" resultType="User" parameterType="user">
select * from user
<where>
<choose>
<when test="username.length() < 5">
username like #{username}
</when>
<when test="username.length() < 10">
username = #{username}
</when>
<otherwise>
id = 1
</otherwise>
</choose>
</where>
</select>这段代码的含义就是当用户名的长度小于(不等于)5的时候,使用模糊查询,查询返回的是泛型为USer的List集合对象,list长度不定;当用户名大于等于5,小于10的时候,使用精确查询,查询指定用户名的用户,返回的是泛型为USer的List集合对象,list长度为1或者0;当用户名长度大于等于10的时候,返回的是id为1的用户。
// 测试通用查询方法——用户名
@Test
public void testFindByCondition1(){
User user = new User();
System.out.println("------------设用户名字长度为2------------");
user.setUsername("%on%");
List<User> users = userMapper2.findByCondition(user);
users.forEach(System.out::println);
System.out.println("------------设用户名字长度为5------------");
user.setUsername("%lions%");
users = userMapper2.findByCondition(user);
users.forEach(System.out::println);
System.out.println("------------设用户名字长度为9------------");
user.setUsername("T_no_name");
users = userMapper2.findByCondition(user);
users.forEach(System.out::println);
System.out.println("------------设用户名字长度为10------------");
user.setUsername("dddddddddd");
users = userMapper2.findByCondition(user);
users.forEach(System.out::println);
System.out.println("------------设用户名字长度为12------------");
user.setUsername("programmer_1");
users = userMapper2.findByCondition(user);
users.forEach(System.out::println);
}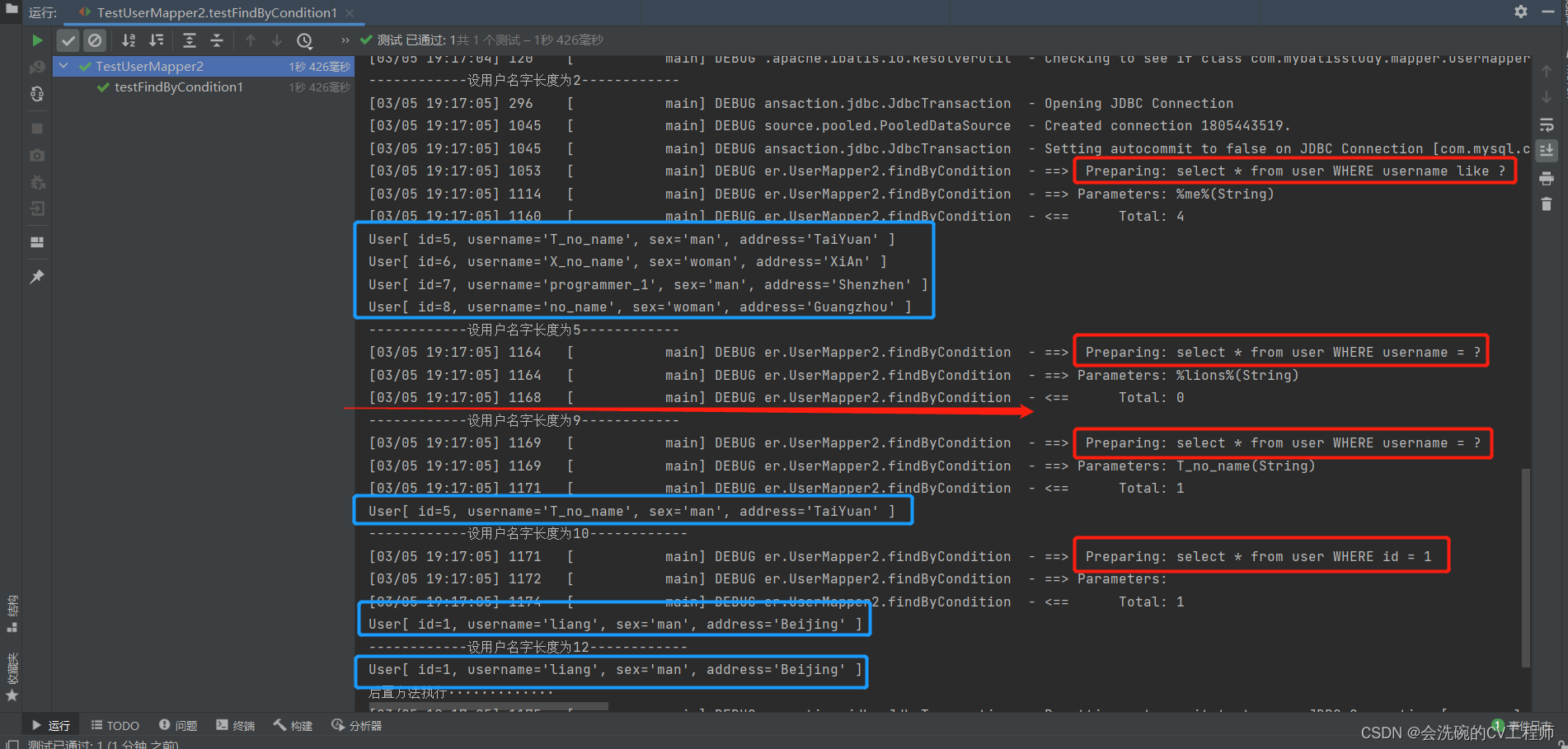
OK,其实从结果集和运行的SQL语句我们都可以得出,该映射文件的标签确实是验证了咱们刚刚的说法
<foreach> 类似JAVA中的for循环,可以遍历集合或数组。 <foreach> 有如
下属性:
- collection:遍历的对象类型
- open:开始的sql语句
- close:结束的sql语句
- separator:遍历每项间的分隔符
- item:表示本次遍历获取的元素,遍历List、Set、数组时表示每项元素,遍历map时表示键值对的值。
- index:遍历List、数组时表示遍历的索引,遍历map时表示键值对的键。
// 用户批量删除
void deleteBatch(int[] ids);<!-- 批量删除 遍历数组-->
<delete id="deleteBatch" parameterType="int">
delete from user
<where>
<foreach collection="array" item="id" open="id in(" close=")" separator=",">
#{id}
</foreach>
</where>
</delete>其实这里对应的SQL语句就是:
delete from user in (?,?,?,...)
// 测试用户批量删除方法
@Test
public void testDeleteBatch(){
int[] ids = {4,8};
userMapper2.deleteBatch(ids);
session.commit();
}运行前和运行后进行对比


运行后,四和八对应的记录确实是被删除了
<foreach> 遍历List和Set的方法是一样的,我们使用 <foreach> 遍历List进行批量添加。
// 批量增加用户
void insertBatch(List<User> users);<!-- 批量增加用户 -->
<insert id="insertBatch" parameterType="User">
insert into user values
<foreach collection="list" item="user" separator=",">
(null,#{user.username},#{user.sex},#{user.address})
</foreach>
</insert>这里对应的SQL语句则是:
insert into user values(null,username,sex,address)*N
N可以为大于或等于1的数
其中肯定会有人问到了,为什么id要为null,其实这里id是主键,我们建库建表的时候就已经设置了这里是自增字段,因此我们无需重复操作,如果设置有和表里面的id重复,说不定还会报错
// 测试批量增加用户方法
@Test
public void testInsertBatch(){
List<User> list = new ArrayList<>();
list.add(new User("man1","man","Beijing"));
list.add(new User("man1","man","Beijing"));
list.add(new User("man1","man","Beijing"));
list.add(new User("man1","man","Beijing"));
list.add(new User("man1","man","Beijing"));
list.add(new User("man1","man","Beijing"));
userMapper2.insertBatch(list);
session.commit();
}运行前和运行后进行对比


OK,通过对比,确实是增加了相关记录,这里的id是因为我测试过很多次了,所以比较大,大家不用在意这些哈哈哈,侧面反映我是很认真在写的,期待小伙伴的支持
下面我们使用 <foreach> 遍历Map进行多条件查询。
/**
* 多条件查询
* @param map 查询的键值对 键:属性名 值:属性值
* @return
*/
List<User> findUser(@Param("queryMap") Map<String,Object> map);<!-- 多条件查询 遍历map-->
<select id="findUser" parameterType="map" resultType="User">
select * from user
<where>
<foreach collection="queryMap" separator="and" index="key" item="value">
${key} = #{value}
</foreach>
</where>
</select>这里对应的代码段其实就是:
select * from user where (? = ?) and (? = ?)
就像我们在淘宝,拼多多和京东上买东西使用筛选一样
// 测试多条件查询方法
@Test
public void testFindUser(){
Map<String,Object> map = new HashMap<>();
// 这里筛选性别为man和地址为Beijing的结果集
map.put("sex","man");
map.put("address","Beijing");
List<User> users = userMapper2.findUser(map);
users.forEach(System.out::println);
// 再测试一下
map.clear();
// 这里筛选地址为Beijing和用户名为man1的结果集
map.put("address","Beijing");
map.put("username","man1");
users = userMapper2.findUser(map);
users.forEach(System.out::println);
}先看用户表数据

执行方法,观察结果是否一致 (是的,确实一致),不一致怎么会放出来呢
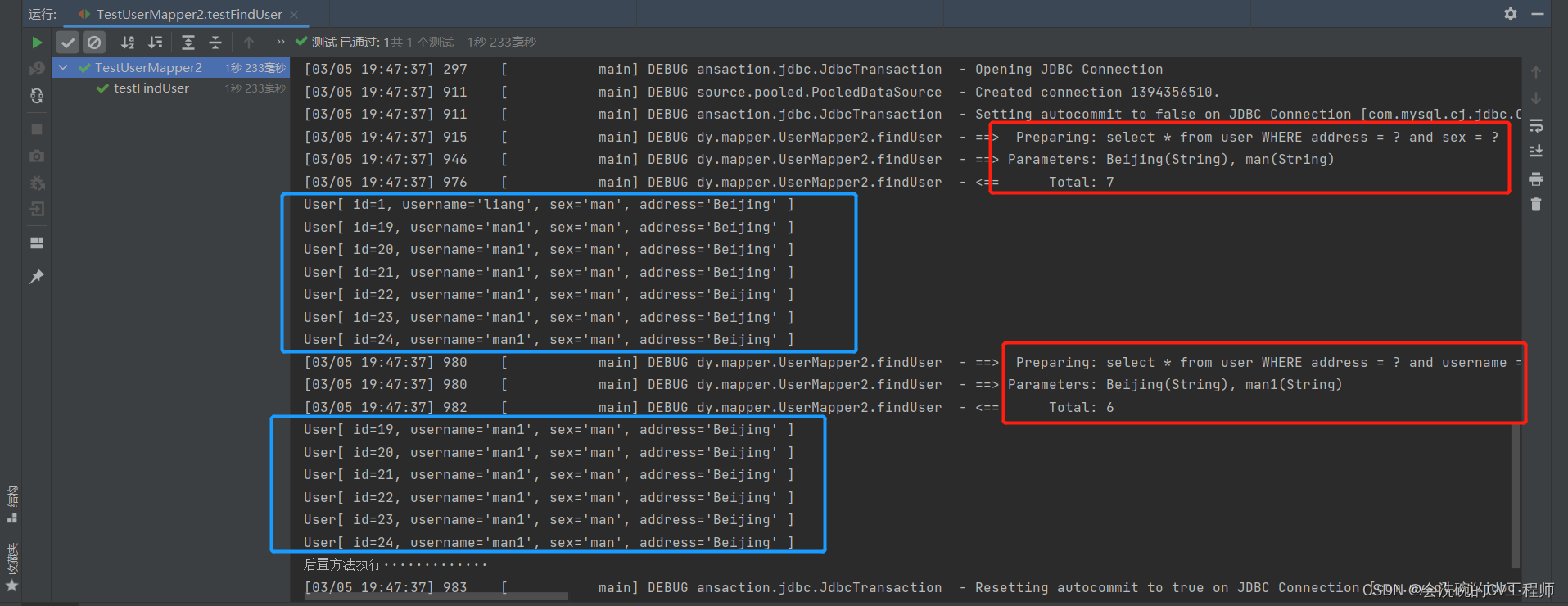
OK,这里确实保持一致,动态查询就学到这里了,后续会继续更新相关内容滴,敬请关注! !!
如果执行过程中有错误的话,不妨看看有没有导错包和导错类,下面就是上面用到相关的类用到的导包
持久层接口用到的包
package com.mybatisstudy.mapper; import com.mybatisstudy.pojo.User; import org.apache.ibatis.annotations.Param; import java.util.List; import java.util.Map;
测试类用到的包
import com.mybatisstudy.mapper.UserMapper2; import com.mybatisstudy.pojo.User; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.InputStream; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map;
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
有没有办法在Ruby中动态创建数组?例如,假设我想遍历用户输入的书籍数组:books=gets.chomp用户输入:"TheGreatGatsby,CrimeandPunishment,Dracula,Fahrenheit451,PrideandPrejudice,SenseandSensibility,Slaughterhouse-Five,TheAdventuresofHuckleberryFinn"我把它变成一个数组:books_array=books.split(",")现在,对于用户输入的每一本书,我想用Ruby创建一个数组。伪代码来做到这一点:x=0books_array.
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params