经过数月网心云运行与跑量,反复在定向——非定向业务中的反复横跳,踩遍无数坑子,下面总结一些容易忽略的调优点/注意点,供各位参考。
一,官方对于4k读的测试方法纯属胡扯
磁盘读iops检测 | 硬盘配置参考 | 网心云 (onethingcloud.com),按照此文中描述的信息,AS SSD中的iops应为磁盘单线程4k读速度,而大量定向业务对该性能指标的要求动辄≥30000iops,20000iops。根据读取4k大小文件来计算,IOPSx4÷1024=MB/s,即使仅满足2万iops也需要单线程4k读取速度达到惊人的78.125MB/s——而这一速度目前只有傲腾这一类的顶级固态可以达到(P4800X 375G版本该项指标可达187MB/s,参考Intel P4800X 375G SSD性能评测-网烁信息科技有限公司 (waso.com.cn)),即使走PCIE4.0x4的铠侠CD6也望尘莫及(铠侠CD6 3.84TB版本单线程4k读速度不过39.7MB/s,参考铠侠固态硬盘怎么样 铠侠固态硬盘评测_什么值得买 (smzdm.com)),甚至连PM983的继任者——三星PM9A3也无法达到如此变态的要求(三星PM9A3 1.92TB版本该项指标也不过54.19MB/s,参考固态硬盘 篇四:捡矿盘垃圾——星星星 PM9A3 1.92T评测_固态硬盘_什么值得买 (smzdm.com))。本着不如摆烂的心态入了一块Intel S3520 480GB版本(单线程4k读速度仅有25MB/s左右,约合6400),但是实际上机后测试结果如下:
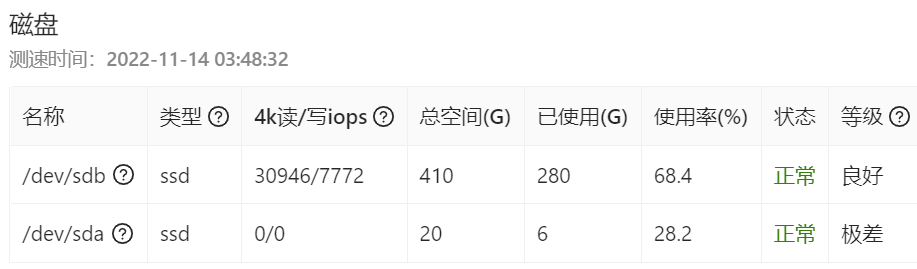
在前期4k读测出来的甚至可以摸到4万,令人百思不得其解,唯一合理的解释就是:
实际跑量中4k读并非单线程
官方测试方式只针对4k单线程读进行测试
而这两者并非线性的乘数关系!
用人话说就是:官方给的测试方法和实际网心云跑量时的测量方法完全不一致,结果甚至也无法换算,没有任何参考价值!根据实测,靠谱的SATA3固态基本都能达到3到4万iops,走NVMe的雷克沙NM610Pro甚至都能跑出14万,同时值得注意的是,iops与跑的业务类型,地区调度也密切相关(平均读写文件大小,读写频率有差异,会导致iops参数不准)。
二,对于X86设备,CPU负载类型为典型的多核低频类型
网心云追求的是尽可能多的线程进行同时读写,如果纯粹用于网心云,高IPC/高主频除了浪费钱和浪费电以外意义不大。对于拥有大量带宽资源,并且需要全新采购服务器用于跑量的大户,一般建议的最佳解为E5-2651v2(12C24T,1.8Ghz-2.0Ghz)+C602(俗称双路X79)+DDR3 REG ECC(简称D3RECC),充分利用好C602廉价的2651v2以及白菜价D3RECC,同时提供尽可能多的PCIE供阵列卡、U2盘使用。如果只是小规模运行,不考虑插大量PCIE设备,建议采购二手Xeon-D 1581一体板(火神革命的板子非常符合要求)。由于吃到了制程红利,1581的性能约为单颗2651v2的1.67倍(典型的多核低频低功耗CPU,Intel当时设计此CPU正是为了网络类型的负载,原话为“可在空间和电源受限的环境中提供工作负载优化的性能,从数据中心到智能边缘。这些创新的系统级芯片处理器支持高密度、单插槽网络、存储和云边缘计算解决方案,具有一系列集成安全性、网络和加速功能”),但是考虑到火神板子极差的扩展性,谜一般的BIOS,整板入手价格不建议超过300元,当成一个大玩具处理。
三,跑量特性:
一般而言上午8点到9点为结算时间点,上午10点逐渐开始大量上行,午高峰为11:00到下午1:30,晚高峰为晚8:00-晚10:00,半夜11:30开始上行呈现断崖式下跌,转入下行缓存部署状态,每日上行流量最低时间出现在凌晨3:00-4:00。
四,单根宽带使用一台网心云一般无法完美跑满,同时不建议顶着上行带宽极限设置带宽数据
同一根宽带下建议拿到公网ip-打开pnp-调整为全锥形网络,至少上两台网心云机器跑量,可以充分利用足带宽资源;另外如果实际上行带宽为10MB/s,一般建议设置的上行带宽控制在9MB/s左右(80%-90%)原则,否则在晚高峰可能会引起线路丢包。
五,机械磁盘不建议跑非定向(又称智能业务)
非定向业务反而对于磁盘IO要求非常高,机械盘到后期iowait基本铁定爆表,引起CPU负载激增,导致降权降低收益。如果使用机械磁盘,建立老老实实堆容量跑B/B1网盘,此两项业务对于机械磁盘有负载优化,猜测是连续对大文件进行读写,可非常有效避免CPU负载过高的问题。
本文首发博客园,如在其它网站上发现均为抄袭,特此声明
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我在我的rails应用程序中安装了来自github.com的acts_as_versioned插件,但有一段代码我不完全理解,我希望有人能帮我解决这个问题class_eval我知道block内的方法(或任何它是什么)被定义为类内的实例方法,但我在插件的任何地方都找不到定义为常量的CLASS_METHODS,而且我也不确定是什么here,并且有问题的代码从lib/acts_as_versioned.rb的第199行开始。如果有人愿意告诉我这里的内幕,我将不胜感激。谢谢-C 最佳答案 这是一个异端。http://en.wikipedia
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
我在Ruby中遇到了一个关于Dir[]和File.join()的简单程序,blobs_dir='/path/to/dir'Dir[File.join(blobs_dir,"**","*")].eachdo|file|FileUtils.rm_rf(file)ifFile.symlink?(file)我有两个困惑:首先,File.join(@blobs_dir,"**","*")中的第二个和第三个参数是什么意思?其次,Dir[]在Ruby中有什么用?我只知道它等价于Dir.glob(),但是,我对Dir.glob()确实不是很清楚。 最佳答案
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L