1.问题简述
今天给新电脑配置pytorch深度学习环境,最后调用python打印print(torch.cuda.is_available())一直出现false的情况(也就是说无法使用GPU),最后上网查找资料得出报错的原因:下载的pytorch是CPU版本,而非GPU版本。
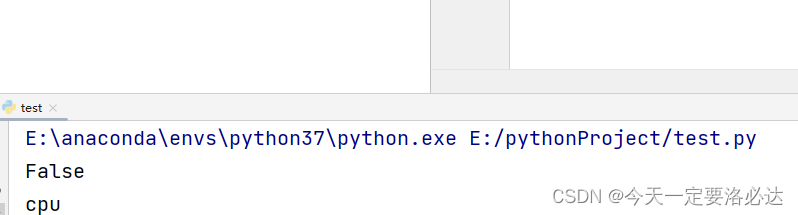
2.报错原因
按照最开始的方法,在pytorch的官网上根据自己的cuda版本(笔者为cuda11.5)使用对应的指令在conda prompt中在线下载:conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch。为了使下载速度加快,我们一般会将后面的-c python删除,采用清华镜像源地址进行安装,例如:
conda install pytorch torchvision torchaudio cudatoolkit=11.3
(清华源加速需要提前部署好,可参考其他博客)。
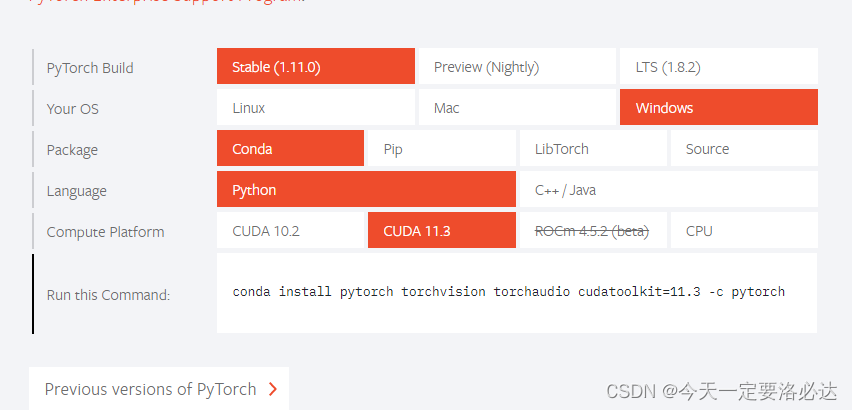
然鹅错误就出在清华镜像源这里,从网上查资料可得,镜像源下载的一般为CPU版本,也是这导致前面所说一直返回false。如果不使用清华源,在官网下载速度又太慢,这个时候我们考虑pip安装。
3.解决办法
首先进入离线文件的下载地址:link.

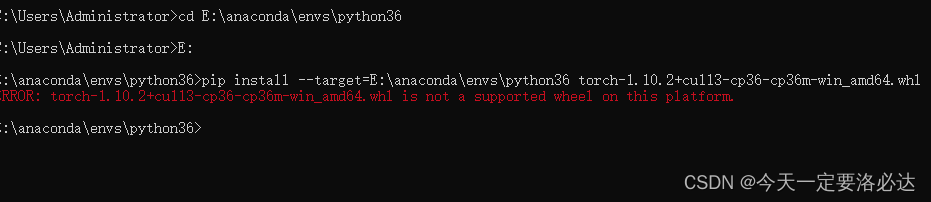
在其中找到符合自己的那个文件。注意看清要下载的包的名字,torch还是其他啥。cuxxx一般是支持cuda的包。看好自己环境中的python处理器是什么版本的,不要下载错了,比如python3.6就是cp36。window,linux版本区分清楚。如下图所示就是python对应版本出错后的结果(后续安装离线文件报错)
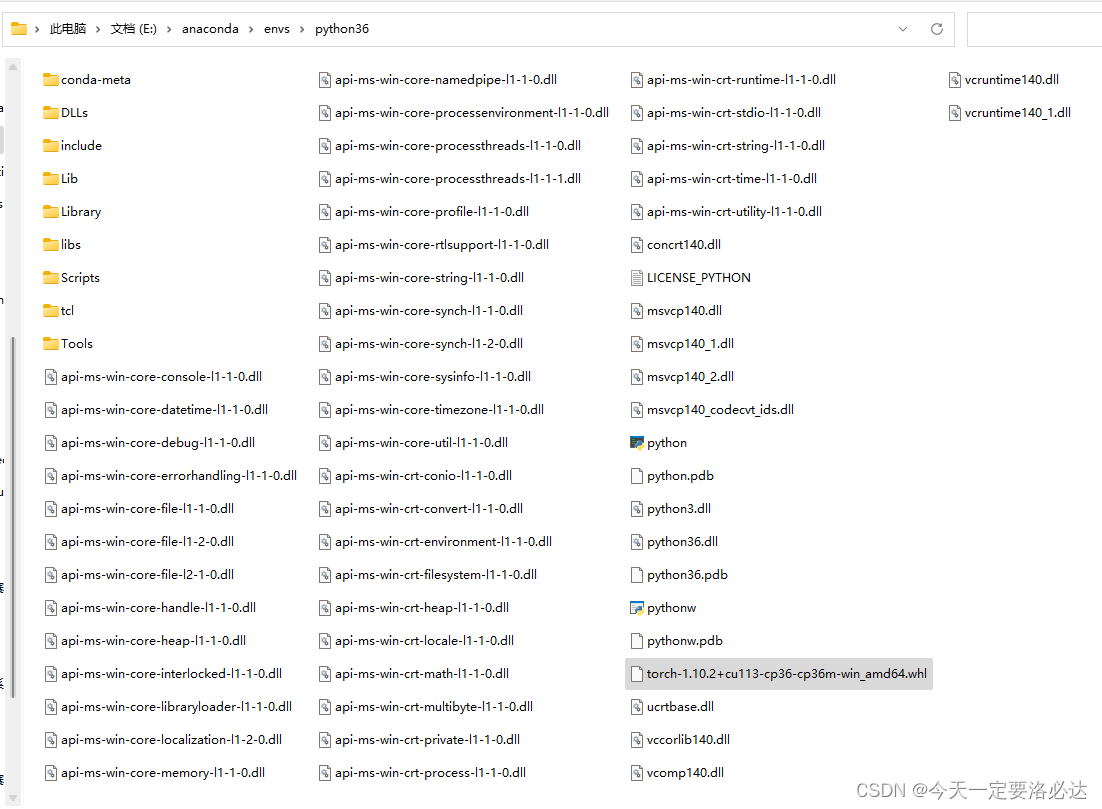
下载完离线文件后,将离线文件放在你需要安装的环境中,如下图,我放在了我自己的深度学习环境python36中,在anconda的envs中。
最后一步就是打开conda prompt ,从base环境切到你自己的环境里,通过cd命令切换到那个环境的文件地址中(切cd操作可以参考其他文章),同时最后输入指令pip install 文件名,例如:pip install torch-1.10.2+cu113-cp36-cp36m-win_amd64.whl

最后静等不到一分钟,就安装好了。去python测试,终于不报错了,也能显示存在一张工作的显卡
检查GPU是否可用的代码:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.cuda.device_count())
最后结果:
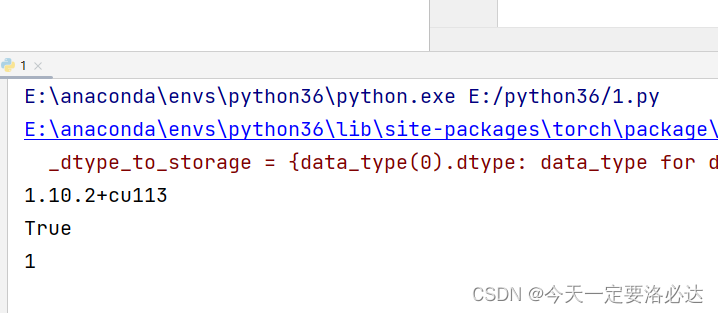
这里有一个报错是numpy的版本不对,后面卸载了重装就是了。
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
这是在Ruby中设置默认值的常用方法:classQuietByDefaultdefinitialize(opts={})@verbose=opts[:verbose]endend这是一个容易落入的陷阱:classVerboseNoMatterWhatdefinitialize(opts={})@verbose=opts[:verbose]||trueendend正确的做法是:classVerboseByDefaultdefinitialize(opts={})@verbose=opts.include?(:verbose)?opts[:verbose]:trueendend编写Verb
我有一个包含多个键的散列和一个字符串,该字符串不包含散列中的任何键或包含一个键。h={"k1"=>"v1","k2"=>"v2","k3"=>"v3"}s="thisisanexamplestringthatmightoccurwithakeysomewhereinthestringk1(withspecialcharacterslike(^&*$#@!^&&*))"检查s是否包含h中的任何键的最佳方法是什么,如果包含,则返回它包含的键的值?例如,对于上面的h和s的例子,输出应该是v1。编辑:只有字符串是用户定义的。哈希将始终相同。 最佳答案
所以我开始关注ruby,很多东西看起来不错,但我对隐式return语句很反感。我理解默认情况下让所有内容返回self或nil但不是语句的最后一个值。对我来说,它看起来非常脆弱(尤其是)如果你正在使用一个不打算返回某些东西的方法(尤其是一个改变状态/破坏性方法的函数!),其他人可能最终依赖于一个返回对方法的目的并不重要,并且有很大的改变机会。隐式返回有什么意义?有没有办法让事情变得更简单?总是有返回以防止隐含返回被认为是好的做法吗?我是不是太担心这个了?附言当人们想要从方法中返回特定的东西时,他们是否经常使用隐式返回,这不是让你组中的其他人更容易破坏彼此的代码吗?当然,记录一切并给出
我在Rails应用程序中使用CarrierWave/Fog将视频上传到AmazonS3。有没有办法判断上传的进度,让我可以显示上传进度如何? 最佳答案 CarrierWave和Fog本身没有这种功能;你需要一个前端uploader来显示进度。当我不得不解决这个问题时,我使用了jQueryfileupload因为我的堆栈中已经有jQuery。甚至还有apostonCarrierWaveintegration因此您只需按照那里的说明操作即可获得适用于您的应用的进度条。 关于ruby-on-r
为什么以下不同?Time.now.end_of_day==Time.now.end_of_day-0.days#falseTime.now.end_of_day.to_s==Time.now.end_of_day-0.days.to_s#true 最佳答案 因为纳秒数不同:ruby-1.9.2-p180:014>(Time.now.end_of_day-0.days).nsec=>999999000ruby-1.9.2-p180:015>Time.now.end_of_day.nsec=>999999998
在Ruby1.9.3(可能还有更早的版本,不确定)中,我试图弄清楚为什么Ruby的String#split方法会给我某些结果。我得到的结果似乎与我的预期相反。这是一个例子:"abcabc".split("b")#=>["a","ca","c"]"abcabc".split("a")#=>["","bc","bc"]"abcabc".split("c")#=>["ab","ab"]在这里,第一个示例返回的正是我所期望的。但在第二个示例中,我很困惑为什么#split返回零长度字符串作为返回数组的第一个值。这是什么原因呢?这是我所期望的:"abcabc".split("a")#=>["bc"
相信很多人在录制视频的时候都会遇到各种各样的问题,比如录制的视频没有声音。屏幕录制为什么没声音?今天小编就和大家分享一下如何录制音画同步视频的具体操作方法。如果你有录制的视频没有声音,你可以试试这个方法。 一、检查是否打开电脑系统声音相信很多小伙伴在录制视频后会发现录制的视频没有声音,屏幕录制为什么没声音?如果当时没有打开音频录制,则录制好的视频是没有声音的。因此,建议在录制前进行检查。屏幕上没有声音,很可能是因为你的电脑系统的声音被禁止了。您只需打开电脑系统的声音,即可录制音频和图画同步视频。操作方法:步骤1:点击电脑屏幕右下侧的“小喇叭”图案,在上方的选项中,选择“声音”。 步骤2:在“声
首先回顾一下拉格朗日定理的内容:函数f(x)是在闭区间[a,b]上连续、开区间(a,b)上可导的函数,那么至少存在一个,使得:通过这个表达式我们可以知道,f(x)是函数的主体,a和b可以看作是主体函数f(x)中所取的两个值。那么可以有, 也就意味着我们可以用来替换 这种替换可以用在求某些多项式差的极限中。方法: 外层函数f(x)是一致的,并且h(x)和g(x)是等价无穷小。此时,利用拉格朗日定理,将原式替换为 ,再进行求解,往往会省去复合函数求极限的很多麻烦。使用要注意:1.要先找到主体函数f(x),即外层函数必须相同。2.f(x)找到后,复合部分是等价无穷小。3.要满足作差的形式。如果是加
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal