好消息:与上题的Emergency是同样的方法。坏消息:又错了&&c++真的比c方便太多太多。
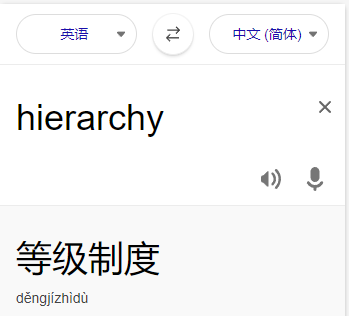
A family hierarchy is usually presented by a pedigree tree. Your job is to count those family members who have no child.
Each input file contains one test case. Each case starts with a line containing 0<N<100, the number of nodes in a tree, and M (<N), the number of non-leaf nodes. Then M lines follow, each in the format:
ID K ID[1] ID[2] ... ID[K]
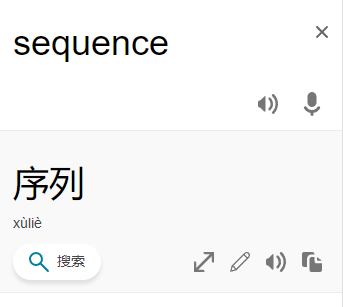
where ID is a two-digit number representing a given non-leaf node, K is the number of its children, followed by a sequence of two-digit ID's of its children. For the sake of simplicity, let us fix the root ID to be 01.
The input ends with N being 0. That case must NOT be processed.
For each test case, you are supposed to count those family members who have no child for every seniority level starting from the root. The numbers must be printed in a line, separated by a space, and there must be no extra space at the end of each line.
The sample case represents a tree with only 2 nodes, where 01 is the root and 02 is its only child. Hence on the root 01 level, there is 0 leaf node; and on the next level, there is 1 leaf node. Then we should output 0 1 in a line.
2 1
01 1 02
0 1
分析家族族谱,算出非叶子节点,就是非孩子数量。,所有的节点用两位数字表示,例如:01,02,06等,其中为了方便,令01为根节点。
输入: N(100个以内的的节点) M(非叶子节点数)
【接下的M行内】 ID(非叶子节点)K(所连的叶子 / 孩子节点个数)ID[0] ID[1]...ID[K](K个叶子节点)
输出:(每层的叶子节点个数)中间用空格隔开————>注意,pat对输出有着固定且严格的格式,所以最后结果的第一个数字前是没有空格的。
就是用广度优先或深度优先遍历每一层,同时标记每层叶子节点并记录,最后数组输出
其实一开始,我觉得很简单,既然只看叶子节点个数,那每次输入ID[0-K]时,我进行记录不就行了吗,每次输入ID都是不同的层级,最后得到的的不就是每层孩子数,所以我在写输入的时候加了一点点变量,最后输出。
1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<string.h>
4
5 int ID[101];
6 int book[101];//记录输出每层叶节点个数
7 int b; //每层的叶节点数
8
9 int main() {
10 int N, M;
11 scanf("%d%d", &N, &M);
12 int K;
13 int a = 1;
14 for (int i = 1; i <= N; i+=K+1) {
15 scanf("%d%d", &ID[i], &K);
16 if( K != 0)
17 for (int j = i+1; j <= i+K; j++) {
18 scanf("%d", &ID[j]);
19 b++; //没输入一次叶节点数就增加一个
20 }
21 book[a] = b;//记录
22 b = 0;//归零进行下次计算
23 a++;//记录数组下标移动
24 }
25 printf("%d", book[0]);//输出第一层
26 for (int i = 1; i <= M; i++) {
27 printf(" %d", book[i]);//输出接下来的每层,并于上一个数字隔开
28
29 }
30 return 0;
31 } 最后得分13分。。。意料之中,举例思考的时候都只考虑了二叉树,编写的过程中便觉的那如果一个节点有有多个非叶节点甚至没有叶节点应该怎么填写。回过头来再看这段,更是觉得搞笑,如果这样可行,那直接记录K就好了。于是尝试着写了第二种,先构建一颗完整的树,然后深度遍历。
首先,变量的设置
1 int N, M;//同题目N,M
2 int K;
3 typedef struct NODE{
4 int nodes;//记录每个节点拥有的叶子节点数
5 int ID[101]; //记录各个叶子节点
6 };
7 struct NODE child[101];//树
8 int book[101];//保存、输出每层叶子节点数
9 int max; //比较和更新每层的叶子节点数,因为左边的遍历完,右边的还要遍历并记录这里使用了结构体而不是简单的数组或者二维数组记录,是因为退出递归的条件需要知道此时节点后续有无别的节点。对比之前的深度遍历我们可以知道,在每次递归的结束条件语句中,会判断后续“无路可走”后才停止并return,1003中是
if (curlen > mindis[curcity])return; ,即如果所求的路径走这时变长就停止这条路。在此题则是你所谈的节点后面无节点就说明是叶子节点,那么就停止遍历,并记录数量。但是我开始在这使用二维数组,判定条件:
if(child[curnode]==0) return;认为全局变量初始化为0,而这样判断说明此行均为0时就说明它是空的是叶子节点,但是实际运行出现了死循环,因为你在输入的for语句中都会因为默认给每一行赋值,导致你输入的值令每行都不是全为0(有点混乱)。而c++中用 child.[curnode]size()【child是vector型】判断长度,如果等于0 ,则进入叶子节点的计数。所以对c语言使用结构体记录每个节点的叶子节点数和叶子节点编号。
1 void dfs(int curnode ,int curlevel);
2 int main() {
3 int a;
4 scanf("%d%d", &N, &M);
5 for (int i = 0; i < M; i++) {
6 scanf("%d%d", &a, &K);
7 child[a].node = K;//非叶节点ID,所有的叶子节点数
8 for (int j = 0; j <K; j++) {
9 scanf("%d", &child[a].ID[j]); //叶子节点序号
10 }
11 }
12 dfs(1, 0);//从 1 开始是因为01为根节点,所有存放元素的是child[01]不是child[0]
13 printf("%d", book[0]);
14 for (int i = 1; i <= max; i++) {
15 printf(" %d", book[i]);
16
17 }
18 return 0;
19 }
20 void dfs(int curnode, int curlevel) {
21 if (child[curnode].node == 0) { //判断有无叶节点,无则进入此记录保存
22 if(max<curlevel)
23 max = curlevel; //更新当前遍历所在的叶子节点层数
24 book[curlevel]++; //没到该层,叶子节点数加 1
25 return;
26 }
27 for (int i = 0; i < child[curnode].node; i++) { //因为对该节点进行遍历,所以在它有的叶子节点数范围内循环
28 dfs(child[curnode].ID[i], curlevel + 1); //把当前的某个叶子节点的数值带入下一个节点的索引,层级加1.
29 }
30 }
<-----------------------------------完整代码----------------------------------->
1 #define _CRT_SECURE_NO_WARNINGS
2 #include<stdio.h>
3 #include<stdlib.h>
4 #include<string.h>
5
6
7 int N, M;
8 int K;
9 typedef struct NODE{
10 int node;
11 int ID[101];
12 };
13 struct NODE child[101];
14 int book[101];
15 int max;
16
17 void dfs(int curnode ,int curlevel);
18 int main() {
19 int a;
20 scanf("%d%d", &N, &M);
21 for (int i = 0; i < M; i++) {
22 scanf("%d%d", &a, &K);
23 child[a].node = K;
24 for (int j = 0; j <K; j++) {
25 scanf("%d", &child[a].ID[j]);
26 }
27 }
28 dfs(1, 0);
29 printf("%d", book[0]);
30 for (int i = 1; i <= max; i++) {
31 printf(" %d", book[i]);
32
33 }
34 return 0;
35 }
36 void dfs(int curnode, int curlevel) {
37 if (child[curnode].node == 0) {
38 if(max<curlevel)
39 max = curlevel;
40 book[curlevel]++;
41 return;
42 }
43 for (int i = 0; i < child[curnode].node; i++) {
44 dfs(child[curnode].ID[i], curlevel + 1);
45 }
46 }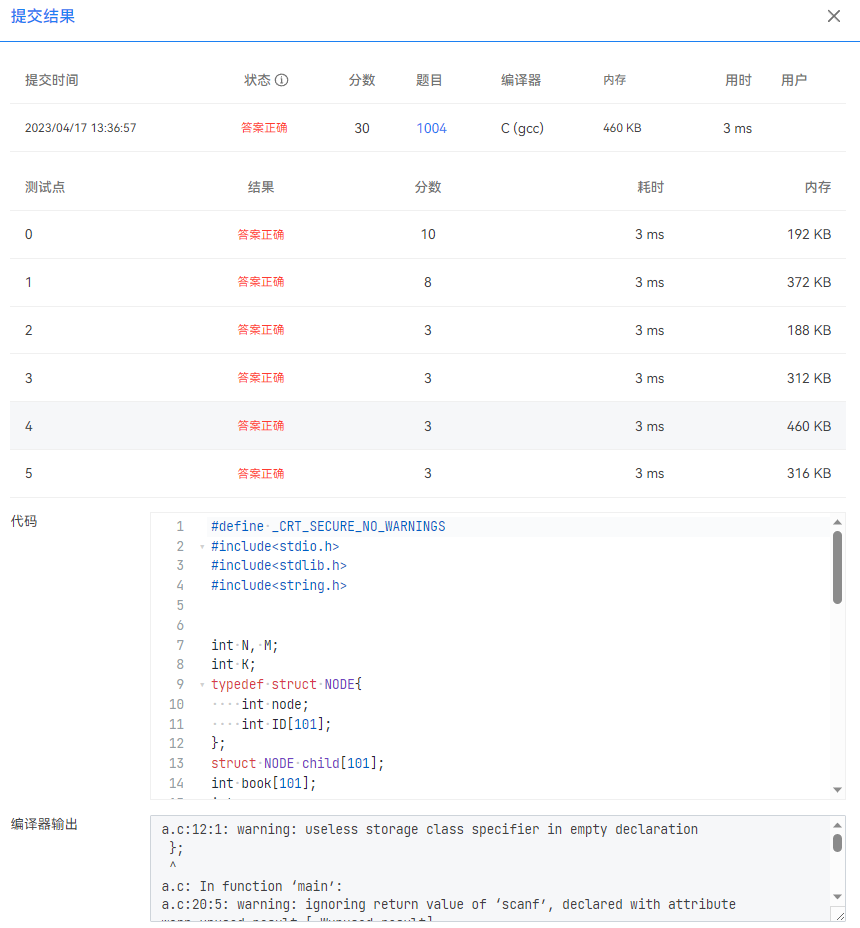
其实掌握深度遍历总体大概的流程,结合题目改变判定条件写出总体的框架基本都能得分,然后调试以后进行修改就大差不差了。


我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO