目录
书接上回,C++中用字符数组来存储字符串在C语言中很常见。请看上回分解链接。
这次我们就来讲C没有的,用string类变量来存储字符串。文章若有更好的排版、或有错误、或内容排布有问题,希望各位读者指出,博主第一时间改正。
string类是在ISO/ANSI C++98标准通过后添加到C++类库中的,因此我们可以使用string类创建变量来存放字符串,而不是使用字符数组。string类的头文件是<string>,名称空间在std中。

最初,我们用string类创建了变量str,没有进行初始化,str的长度是0,也用字符串常量给类变量赋值。然后我们使用输入对象cin为str输入字符串,还用cout对str的内容进行输出。总结来说就是:
| 功能/对象 | str | arr |
|---|---|---|
| 使用C-风格字符串来初始化 | 可以 | 可以 |
| 使用cin输入字符串来赋值 | 可以 | 可以 |
| 使用数组下标的方式访问 | 可以 | 可以 |
| 使用cout显示内容 | 可以 | 可以 |
提一嘴数组下标形式来访问类的元素,我这个们看到代码str[2],我们知道,str是一个类创建出来的变量,一个变量怎么能有下标呢,更别提用下标来访问元素了,其实这是因为,string类隐藏了字符串的数组性质,让我们使用的是一个普通变量,实际上是有内部操作的,待会的代码就会让你对类有更清晰一点的了解。

string类变量的初始化也和有遵从C++11等新方式,比如单值变量用{}列表初始化,''=''可以省略,size是用来计算str的长度的和C语言用strlen来求字符串长度一样,看到str.size为0我们就能理解没有初始化的时候,创建一个长度为0的string对象了,对比str3用{}来初始化,显示出来也一样,这说明什么呢?我们知道在创建数组的时候int arr[10]{};的意思是初始化10个整型元素为0,所以其实str和str3都应该是被初始化为'\0'了。

我们加上打印的来看一下:

这样可以理解的更深刻一些。

把这段代码给理解了,就差不多啦(doge),举例子而已哈(bush)。

处理string对象的语法通常比C字符串函数简单。
补充:假如我们在追加charr1的时候,目的地的空间不够就会造成数组外的数据被破坏,导致程序终止,而string类具有自动调整大小的功能,可以避免。如果我们使用strncat()的话,又有点复杂,增加了编写的难度,所以其实类变量是更有优势的。
用cin对string类的输入和字符数组的输入是一样的,cin>>str;cin>>arr;不一样的是读取一行字符串的时候string类的句法是getline(cin, str);
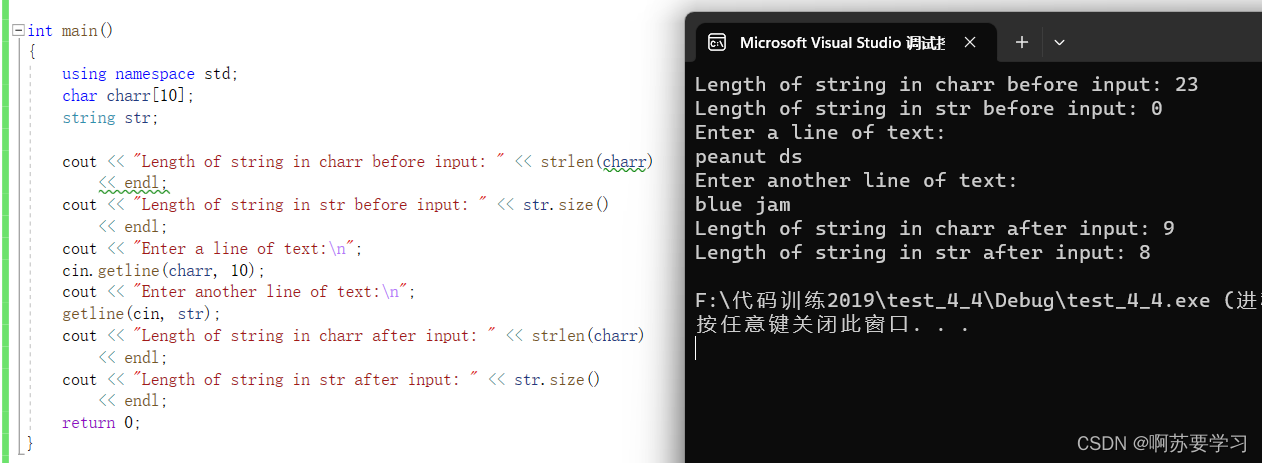
charr没输入之前是23的长度为什么呢,明明数组只有10的空间大小,这是因为没有初始化,是随机值,只有遇到\0才停止计算长度,而str虽然没有初始化,长度为0的原因是string对象的长度被自动设置位0,并根据你为对象输入的字符串大小而随时调整。
geline(cin, str)没有使用.(点),这说明getline()在这里不是一个类方法,它将cin作为参数,指出到哪里去查输入。那为什么一个getline()是istream的类方法,另一个不是呢,这是因为在引入string类之前就有了getline()了,当时getline()在设计的时候考虑到了诸如double和int等基本类型,但没有考虑string类型,那你可能会问,没有处理string对象的类的方法,cin>>str是如何实现的呢?这是因为在处理string对象的代码使用的是string类的一个友元函数,另外我们可以是cin和cout于string对象而不用考虑如何实现的。

除char类型外,C++还有类型wchar_t, C++11又增加了char16_t和char32_t,可以创建这些类型的字符常量和字符串字面值。C++分别使用前缀L,u,U来表示对应的类型的字符常量或字符串字面值。

 这些还在发展中!通用字符名与上面的char16_t和char32_t有联系。
这些还在发展中!通用字符名与上面的char16_t和char32_t有联系。

当我们想cout出"的时候,可不可以不要用\"转义序列来输出,因外那样将会把一个输出字符串增加得很难看或难懂。答案是有的,通过原始(raw)字符串来实现。
原始字符串:在原始字符串中,字符表示的就是字符本身,例如,\n在原始字符串中不是换行的意思,就是\和n字符,"也是一个字符,可以放在字符串字面值里,因此,就不能再使用它来表示字符串的开头和结尾,而是将"(和)"用做界定符,并使用前缀R来标识原始字符串。

假如我们在原始字符串中包含)",该怎么做?我们用R"(来表示原始字符串的开始,当编译器遇到第一个")时,会不会认为是字符串的结束呢,无疑是会的,和C的注释一样,不能嵌套,其实我们可以在"与(间添加其它字符,这意味着表示字符串结尾的时候也要在)和"间添上字符才能结尾。

ok啦,终于讲完字符串复合类型啦!
希望你看完有所收获,求点赞,求点赞,求点赞!
你的点赞是我更新的动力,一起加油!
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
在Ruby1.9.3(可能还有更早的版本,不确定)中,我试图弄清楚为什么Ruby的String#split方法会给我某些结果。我得到的结果似乎与我的预期相反。这是一个例子:"abcabc".split("b")#=>["a","ca","c"]"abcabc".split("a")#=>["","bc","bc"]"abcabc".split("c")#=>["ab","ab"]在这里,第一个示例返回的正是我所期望的。但在第二个示例中,我很困惑为什么#split返回零长度字符串作为返回数组的第一个值。这是什么原因呢?这是我所期望的:"abcabc".split("a")#=>["bc"
玩转ruby,我已经:#!/usr/bin/ruby-w#WorldweatheronlineAPIurlformat:http://api.worldweatheronline.com/free/v1/weather.ashx?q={location}&format=json&num_of_days=1&date=today&key={api_key}require'net/http'require'json'@api_key='xxx'@location='city'@url="http://api.worldweatheronline.com/free/v1/weather.
我有代码:classScenedefinitialize(number)@number=numberendattr_reader:numberendscenes=[Scene.new("one"),Scene.new("one"),Scene.new("two"),Scene.new("one")]groups=scenes.inject({})do|new_hash,scene|new_hash[scene.number]=[]ifnew_hash[scene.number].nil?new_hash[scene.number]当我启动它时出现错误:freq.rb:11:in`[]'
我的Ruby代码中有一个看起来有点像这样的结构Parameter=Struct.new(:name,:id,:default_value,:minimum,:maximum)稍后,我使用创建了这个结构的一个实例freq=Parameter.new('frequency',15,1000.0,20.0,20000.0)在某些时候,我需要这个结构的精确副本,所以我调用newFreq=freq.clone然后,我更改newFreq的名称newFreq.name.sub!('f','newF')奇迹般地,它也改变了freq.name!像newFreq.name='newFrequency'这样
我正在重构一个西洋跳棋程序,我正在尝试将玩家移动请求(例如以“3、3、5、5”的形式)处理到一个int数组中。我有以下方法,但感觉不像我所知道的那样像Ruby:deftranslate_move_request_to_coordinates(move_request)return_array=[]coords_array=move_request.chomp.split(',')coords_array.each_with_indexdo|i,x|return_array[x]=i.to_iendreturn_arrayend我用它进行了以下RSpec测试。it"translatesa
每当我尝试运行该程序时,都会弹出一条错误消息“条件字符串文字(第10行)”。我做错了什么?puts"Welcometothebestcalculatorthereis.Wouldyouliketo(a)calculatetheareaofageometricshapeor(b)calculatetheequationofaparabola?Pleaseenteran'a'ora'b'togetstarted."response=gets.chompifresponse=="a"or"A"puts"ok."elsifresponse=="b"or"B"puts"awesome."else
我用这个错误搜索了jekyll。jekyll处理页面时似乎出现了ruby错误,但我根本不了解ruby。杰基尔版本1.3.1我什至重新安装了ruby和jekyll,但结果没有改变。更新:在我将jekyll从1.31降级到1.20后,这个错误消失了注意:我的网站是用jekyll1.20创建的,所以它不能用1.3.1构建?这是核心问题吗?E:\GitHub\sample>jekyll服务--trace:Configurationfile:E:/GitHub/sample/_config.ymlSource:E:/GitHub/sampleDestination:E:/GitHub
String#match和Regexp#match在匹配成功时返回一个MatchData:"".match(//)#=>#//.match("")#=>#//.match(:"")#=>#但是Symbol#match返回匹配位置(如String#=~)::"".match(//)#=>0为什么Symbol#match表现不同?有用例吗? 最佳答案 我将其报告为Ruby核心中的错误:https://bugs.ruby-lang.org/issues/11991.让我们看看他们会怎么说。更新被质疑的行为似乎是一个错误。似乎从Ruby2.
我有以下代码:classProfileLookup基本上包含大量查找数据,按类别拆分。目的是为数据库中的每个类别创建一个方法。通过Rails控制台,此代码按预期工作:ruby-1.9.3@hub:002>ProfileLookup.available_gendersProfileLookupLoad(0.6ms)SELECT"profile_lookups".*FROM"profile_lookups"WHERE"profile_lookups"."category"='gender'ORDERBYvalue=>["Female","Male"]但是,我的规范不合格。以下规范:requ