由于性能压测以及后续对全链路压测的探索需要,对公司的架构需要有一定的了解,以此来记录一些运维相关的知识
无论是在阿里云服务器上亦或者是在亚马逊服务器上,当存在多个ECS服务器时,往往都会在用户请求前进入一个叫负载均衡服务器的东西,在阿里云上被称作SLB(Server Load Balancer)在亚马逊上被称作ELB(Elastic Load Balance),实际上他们的作用都是一样的
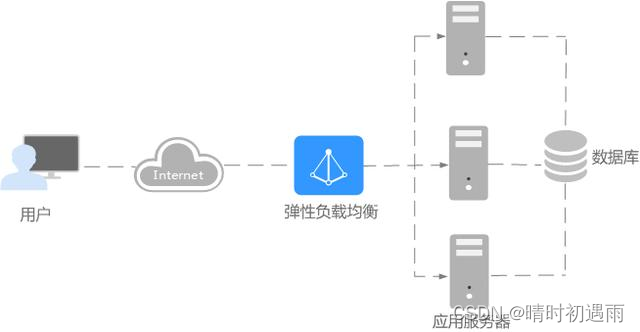
对于业务量访问较大的业务,可以通过ELB设置相应的分配策略,将访问量均匀的分到多个后端服务器处理。例如大型门户网站,移动应用市场等。
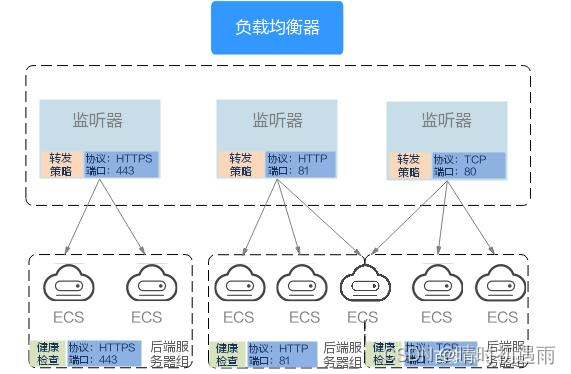
同时您还可以开启会话保持功能,保证同一个客户请求转发到同一个后端服务器。从而提升访问效率,如图1所示。
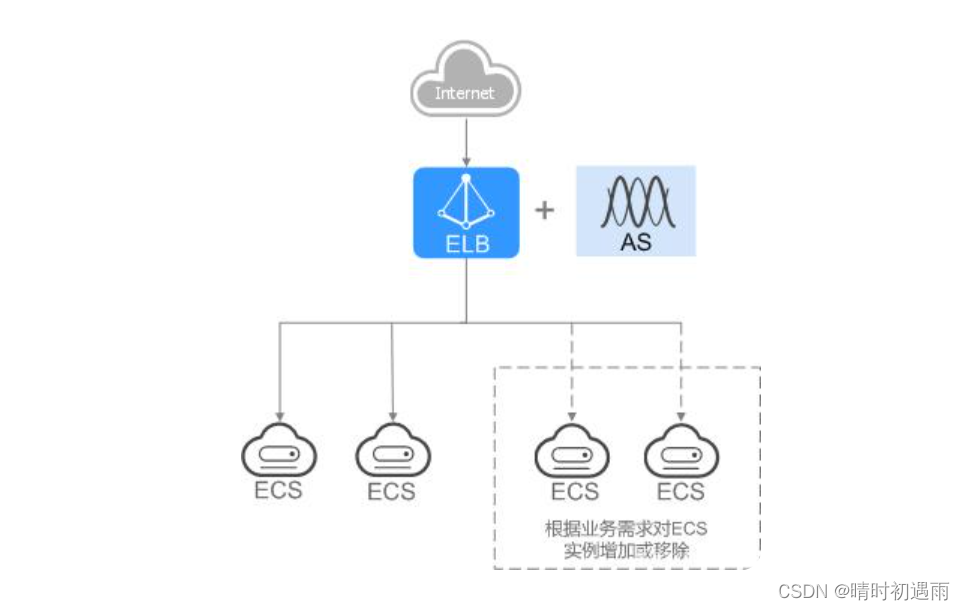
对于存在潮汐效应的业务,结合弹性伸缩服务,随着业务量的增长和收缩,弹性伸缩服务自动增加或者减少的ECS实例,可以自动添加到ELB的后端云服务器组或者从ELB的后端云服务器组移除。负载均衡实例会根据流量分发、健康检查等策略灵活使用ECS实例资源,在资源弹性的基础上大大提高资源可用性,如图2所示。例如电商的“双11”、“双12”、“618”等大型促销活动,业务的访问量短时间迅速增长,且只持续短暂的几天甚至几小时。使用负载均衡及弹性伸缩能最大限度的节省IT成本。
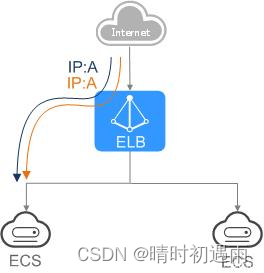
对于可靠性有较高要求的业务,可以在负载均衡器上添加多个后端云服务器。负载均衡器会通过健康检查及时发现并屏蔽有故障的云服务器,并将流量转发到其他正常运行的后端云服务器,确保业务不中断,如图3所示。
例如官网,计费业务,Web业务等。
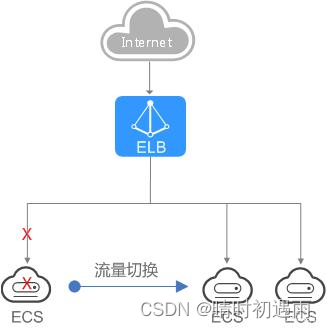
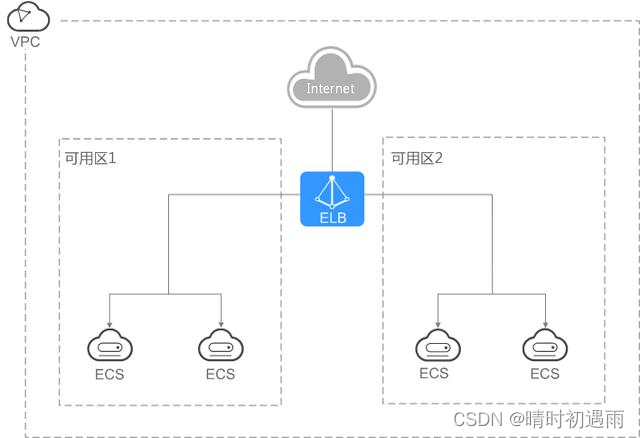
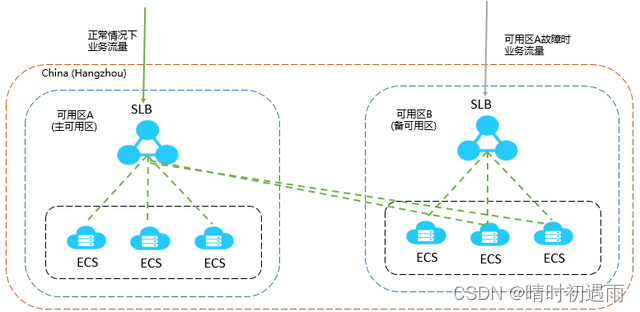
对于可靠性和容灾有很高要求的业务,弹性负载均衡可将流量跨可用区进行分发,建立实时的业务容灾部署。即使出现某个可用区网络故障,负载均衡器仍可将流量转发到其他可用区的后端云服务器进行处理,如图4所示。
例如银行业务,警务业务,大型应用系统等。
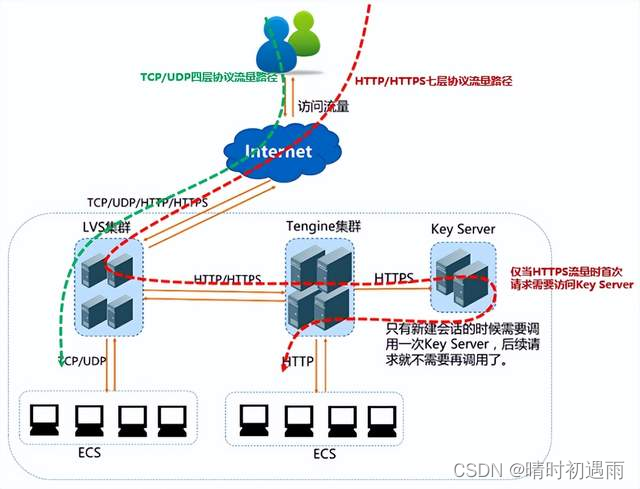
对于入网流量,负载均衡会根据用户在控制台或API上配置的转发策略,对来自前端的访问请求进行转发和处理,数据流转如下图所示
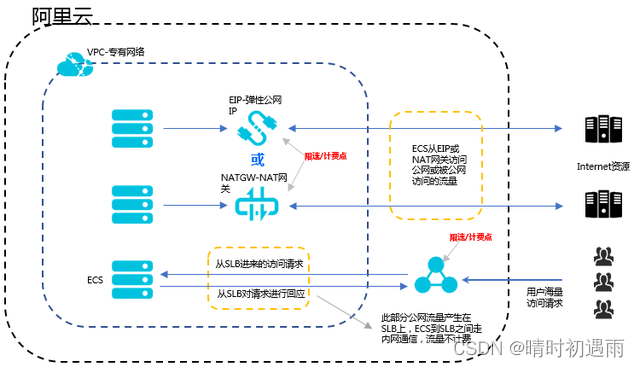
负载均衡SLB和后端ECS之间是通过内网进行通信的
同城容灾 是在同城或相近区域内 ( ≤ 200K M )建立两个数据中心 : 一个为数据中心,负责日常生产运行 ; 另一个为灾难备份中心,负责在灾难发生后的应用系统运行。同城灾难备份的数据中心与灾难备份中心的距离比较近,通信线路质量较好,比较容易实现数据的同步 复制 ,保证高度的数据完整性和数据零丢失。同城灾难备份一般用于防范火灾、建筑物破坏、供电故障、计算机系统及人为破坏引起的灾难。
处理机制:
异地容灾 主备中心之间的距离较远 (> 200KM ) , 因此一般采用异步镜像,会有少量的数据丢失。异地灾难备份不仅可以防范火灾、建筑物破坏等可能遇到的风险隐患,还能够防范战争、地震、水灾等风险。由于同城灾难备份和异地灾难备份各有所长,为达到最理想的防灾效果,数据中心应考虑采用同城和异地各建立一个灾难备份中心的方式解决。
处理机制:
本地容灾 是指在本地机房建立容灾系统,日常情况下可同时分担业务及管理系统的运行,并可切换运行;灾难情况下可在基本不丢失数据的情况下进行灾备应急切换,保持业务连续运行。与异地灾备模式相比较,本地双中心具有投资成本低、建设速度快、运维管理相对简单、可靠性更高等优点;异地灾备中心是指在异地建立一个备份的灾备中心,用于双中心的数据备份,当双中心出现自然灾害等原因而发生故障时,异地灾备中心可以用备份数据进行业务的恢复。
高可用
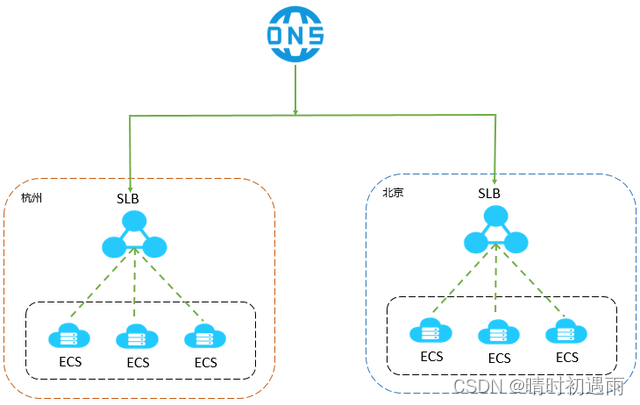
采用全冗余设计,无单点,支持同城容灾。搭配DNS可实现跨地域容灾,可用性高达99.95%。
根据应用负载进行弹性扩容,在流量波动情况下不中断对外服务。
可扩展
您可以根据业务的需要,随时增加或减少后端服务器的数量,扩展应用的服务能力。
低成本
与传统硬件负载均衡系统高投入相比,成本可下降60%。
安全
结合云盾,可提供5Gbps的防DDoS攻击能力。
高并发
集群支持亿级并发连接,单实例提供千万级并发能力。
我有一个EC2实例正在运行。我有一个负载均衡器,它与EC2实例相关联。PingTarget:HTTP:3001/healthCheckTimeout:5secondsInterval:24secondsUnhealthythreshold:2Healthythreshold:10现在该实例显示为OutofService。我什至尝试更改监听端口等等。一切正常,直到重新启动我的EC2实例。任何帮助将不胜感激。仅供引用:我有一个在端口3001上运行的Rails应用程序,我有一个用于HTTP:80(loadbalancer)到HTTP:3001的监听器。我还在终端中通过ssh检查了正在运行的应
我对为我的RubyonRails3.1.3应用优化我的Unicorn设置的方法很感兴趣。我目前正在高CPU超大实例上生成14个工作进程,因为我的应用程序在负载测试期间似乎受CPU限制。在模拟负载测试中,每秒大约20个请求重放请求,我的实例上的所有8个内核都达到峰值,盒子负载飙升至7-8个。每个unicorn实例使用大约56-60%的CPU。我很好奇可以通过哪些方式对其进行优化?我希望能够每秒将更多请求汇集到这种大小的实例上。内存和所有其他I/O一样完全正常。在我的测试过程中,CPU越来越低。 最佳答案 如果您受CPU限制,您希望使用
我每12小时在我的亚马逊EC2微型实例上运行一次cron作业。它下载118MB的文件并使用json库解析它。这当然会使实例内存不足。我的实例有416MB的可用内存,但随后我运行脚本,它下降到6MB,然后被操作系统杀死。我想知道我在这里有什么选择?是否可以通过Ruby有效地解析它,或者我是否必须下降到像C这样的低级东西?我可以获得一个功能更强大的亚马逊实例,但我真的很想知道是否可以通过Ruby做到这一点。更新:我看过yajl。它可以在解析时为您提供json对象,但问题是,如果您的JSON文件仅包含1个根对象,那么它将被迫解析所有文件。我的JSON看起来像这样:--Root-Obj1-Ob
文章目录Kubernetes(k8s)工作负载一、Workloads二、Pod三、Deployment四、RC、RS、DaemonSet、StatefulSet五、Job、CronJob1、Job2、CronJob六、GCKubernetes(k8s)工作负载一、Workloads什么是工作负载(Workloads)工作负载是运行在Kubernetes上的一个应用程序。一个应用很复杂,可能由单个组件或者多个组件共同完成。无论怎样我们可以用一组Pod来表示一个应用,也就是一个工作负载Pod又是一组容器(Containers)所以关系又像是这样工作负载(Workloads)控制一组PodPod控制
Nginx的6种负载均衡策略【轮询/加权轮询weight/ip_hash/least_conn/urlhash/fair】总结:nginx负载均衡策略1、轮询策略轮询策略其实是一个特殊的加权策略,不同的是,服务器组中的各个服务器的权重都是1upstreambackend{server192.168.136.136weight=1;server192.168.136.136:81weight=1;server192.168.136.136:82weight=1;server192.168.136.136:83weight=1;}server{listen80;server_namelocalho
我正在尝试为模块实现懒惰加载。该模块有一堆儿童路线独特的出口名称。当我尝试访问路线时,这似乎不起作用。从我保存的这个示例中,这似乎可以:https://plnkr.co/edit/nnxaozitm00riixzemts?p=preview您可以看到我有孩子的路线{path:'list',component:HeroListComponent,outlet:'abc'},在hero-routing.module.ts和路由器出口:在hero.com.ponent.ts当我在本地运行时,我应该能够访问Localhost:3000/Heroes/(ABC:List),但似乎不起作用。注意:您可以通
我们在CentOS6上使用2个Web服务器和1个数据库服务器运行一个具有ROR的网站。有时它会显示消息“网站负载过重”...请帮忙检查一下。我们将Passenger4.0.21与Ruby1.8.7和Apache2.2.15一起使用。Web服务器以默认设置运行。下面是passenger-status的一些输出:#乘客状态Version:4.0.21Date:ThuDec1202:02:44-05002013Instance:20126-----------Generalinformation-----------Maxpoolsize:6Processes:6Requestsintop-
我发现这个javascript很奇怪,当我在我的控制台浏览器上运行时,它会给我一个带有以下消息的警告'AlwaysbewaryofJavascriptcontainingquotes.Noquotes=safe!'我很好奇(真的不知道这是不是一个东西,有什么用吗?)如果你们中有人愿意分享关于这种“技术”的知识,我将不胜感激!:)for(Ain{A????????????????????????????????????????????????????????????????:0}){alert(unescape(escape(A).replace(/u.{8}/g,[])))};
我很难弄清楚为什么会这样,但基本上ReduxPromise在返回类似内容时对我来说工作正常:return{type:STORY_ACTIONS.STORY_SPOTIFY_REQUEST,payload:request}但是,我现在需要像这样传递另一个信息return{order:0,//Newfieldtype:STORY_ACTIONS.STORY_SPOTIFY_REQUEST,payload:request}这导致Unresolvedpromise而不是数据。我尝试将order重命名为position或index之类的东西......仍然没有。 最佳
提供源代码及说明文档伸手党走远点儿。上来就口吐莲花的请自重,注意自己的素质和境界。恒模盲均衡算法(CMA) 在各种盲均衡算法中,恒模算法(CMA)是一种重要的盲信道均衡方法,广泛地应用在了数字通信系统中,这种算法隐含地利用了接收信号的高阶统计量。结构框图可由下图所示。误差函数可定义为:其中R2是一个依赖于信源序列高阶统计量的一个实常数,可定义如下式,p由信源序列决定:(目前见到的QAM信号,P=2)抽头系数更新可由下式表示: 系统均衡输出可表示为:修正MCMA算法MCMA针对CMA的代价函数进行改进,将其分为实部和虚部两部分,通过对实部和虚部同时进行信道均衡实现对载波相位恢复。MCMA的