昨天没有清空pool直接删除osd节点,导致今天ceph挂掉了…
执行
ceph -s
显示
2022-05-07 08:10:08.273 7f998ddeb700 -1 asok(0x7f9988000bf0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/guests/ceph-client.admin.230947.140297388437176.asok': (2) No such file or directory
cluster:
id: 0efd6fbe-870b-41c4-92b1-d1a028d397f1
health: HEALTH_WARN
5 pool(s) have no replicas configured
Reduced data availability: 640 pgs inactive
1/3 mons down, quorum node1,node2
services:
mon: 3 daemons, quorum node1,node2 (age 14h), out of quorum: node1_bak
mgr: node1(active, since 14h), standbys: node2
osd: 6 osds: 6 up (since 14h), 6 in (since 22h)
data:
pools: 5 pools, 640 pgs
objects: 0 objects, 0 B
usage: 8.4 GiB used, 5.2 TiB / 5.2 TiB avail
pgs: 100.000% pgs unknown
640 unknown
可以看到:pgs: 100.000% pgs unknown数据异常
执行
ceph df
显示
2022-05-07 08:15:56.872 7f96a3477700 -1 asok(0x7f969c000bf0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/guests/ceph-client.admin.54160.140284839079608.asok': (2) No such file or directory
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 5.2 TiB 5.2 TiB 2.4 GiB 8.4 GiB 0.16
TOTAL 5.2 TiB 5.2 TiB 2.4 GiB 8.4 GiB 0.16
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
images 1 128 0 B 0 0 B 0 0 B
volumes 2 128 0 B 0 0 B 0 0 B
backups 3 128 0 B 0 0 B 0 0 B
vms 4 128 0 B 0 0 B 0 0 B
cache 5 128 0 B 0 0 B 0 0 B
存储池分配的空间都是0
说明osd节点挂掉了
查看一下osd节点情况
ceph osd tree
2022-05-07 08:17:38.461 7f917c55c700 -1 asok(0x7f9174000bf0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/guests/ceph-client.admin.54288.140262693154488.asok': (2) No such file or directory
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-9 0 root vm-disk
-8 0 root cache-disk
-7 0 root hdd-disk
-1 3.25797 root default
-15 1.62898 host computer
1 hdd 0.58600 osd.1 up 1.00000 1.00000
3 hdd 0.16399 osd.3 up 1.00000 1.00000
5 hdd 0.87900 osd.5 up 1.00000 1.00000
-13 1.62898 host controller
0 hdd 0.58600 osd.0 up 1.00000 1.00000
2 hdd 0.16399 osd.2 up 1.00000 1.00000
4 hdd 0.87900 osd.4 up 1.00000 1.00000
-3 0 host node1
-5 0 host node2
可以看到node1和node2都不存在osd了,变成了外网IP的computer和controller上
可能是因为crush map设置不对,之前编译的newcrushmap在/etc/ceph下
cd /etc/ceph
ceph osd setcrushmap -i newcrushmap
再执行
ceph df
可以看到存储信息恢复
2022-05-07 08:26:48.930 7f946fa78700 -1 asok(0x7f9468000bf0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/guests/ceph-client.admin.54898.140275376729784.asok': (2) No such file or directory
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 5.2 TiB 5.2 TiB 2.4 GiB 8.4 GiB 0.16
TOTAL 5.2 TiB 5.2 TiB 2.4 GiB 8.4 GiB 0.16
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
images 1 128 1.7 GiB 222 1.7 GiB 0.15 1.1 TiB
volumes 2 128 495 MiB 146 495 MiB 0.04 1.1 TiB
backups 3 128 19 B 3 19 B 0 1.1 TiB
vms 4 128 0 B 0 0 B 0 3.5 TiB
cache 5 128 104 KiB 363 104 KiB 0 317 GiB
执行
ceph -s
2022-05-07 08:27:01.426 7f7cf23db700 -1 asok(0x7f7cec000bf0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/guests/ceph-client.admin.54928.140174512107192.asok': (2) No such file or directory
cluster:
id: 0efd6fbe-870b-41c4-92b1-d1a028d397f1
health: HEALTH_WARN
5 pool(s) have no replicas configured
Reduced data availability: 128 pgs inactive
application not enabled on 3 pool(s)
1/3 mons down, quorum node1,node2
services:
mon: 3 daemons, quorum node1,node2 (age 14h), out of quorum: node1_bak
mgr: node1(active, since 14h), standbys: node2
osd: 6 osds: 6 up (since 14h), 6 in (since 22h)
data:
pools: 5 pools, 640 pgs
objects: 734 objects, 2.2 GiB
usage: 8.4 GiB used, 5.2 TiB / 5.2 TiB avail
pgs: 20.000% pgs unknown
512 active+clean
128 unknown
可以看到还有pgs: 20.000% pgs unknown20%的数据异常
这就是当初直接删除osd没清理vms导致的了
防止之后操作出现异常
先修改主机名
节点1:
hostnamectl set-hostname node1
节点2:
hostnamectl set-hostname node2
节点1上操作
执行删除pool命令
ceph osd pool delete vms vms --yes-i-really-really-mean-it
查看池情况:
ceph osd pool ls
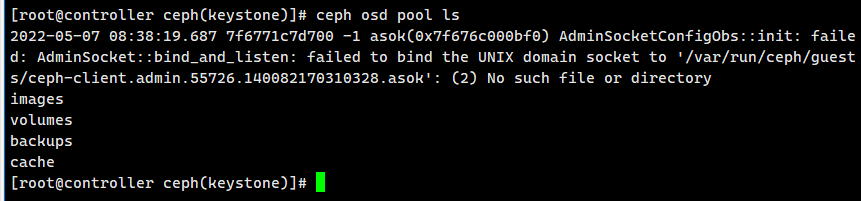
可以看到vms已经删除了
再查看ceph -s
[root@controller ceph(keystone)]# ceph -s
2022-05-07 08:40:41.131 7f86eb0dc700 -1 asok(0x7f86e4000bf0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/guests/ceph-client.admin.55936.140217327562424.asok': (2) No such file or directory
cluster:
id: 0efd6fbe-870b-41c4-92b1-d1a028d397f1
health: HEALTH_WARN
4 pool(s) have no replicas configured
application not enabled on 3 pool(s)
1/3 mons down, quorum node1,node2
services:
mon: 3 daemons, quorum node1,node2 (age 14h), out of quorum: node1_bak
mgr: node1(active, since 14h), standbys: node2
osd: 6 osds: 6 up (since 14h), 6 in (since 22h)
data:
pools: 4 pools, 512 pgs
objects: 734 objects, 2.2 GiB
usage: 8.4 GiB used, 5.2 TiB / 5.2 TiB avail
pgs: 512 active+clean
可以看到数据异常已经解决,剩下就是重建vms
ceph osd pool create vms 128 128
修改存储池规则
ceph osd pool set vms crush_rule vm-disk
查看osd分配情况
ceph osd tree
发现已经应用正常了
[root@controller ceph(keystone)]# ceph osd tree
2022-05-07 08:44:36.093 7fcf9ed4c700 -1 asok(0x7fcf98000bf0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/guests/ceph-client.admin.56195.140529585106616.asok': (2) No such file or directory
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-9 1.74597 root vm-disk
4 hdd 0.87299 osd.4 up 1.00000 1.00000
5 hdd 0.87299 osd.5 up 1.00000 1.00000
-8 1.74597 root cache-disk
2 hdd 0.87299 osd.2 up 1.00000 1.00000
3 hdd 0.87299 osd.3 up 1.00000 1.00000
-7 1.09000 root hdd-disk
0 hdd 0.54500 osd.0 up 1.00000 1.00000
1 hdd 0.54500 osd.1 up 1.00000 1.00000
-1 3.25800 root default
-3 1.62900 host node1
0 hdd 0.58600 osd.0 up 1.00000 1.00000
2 hdd 0.16399 osd.2 up 1.00000 1.00000
4 hdd 0.87900 osd.4 up 1.00000 1.00000
-5 1.62900 host node2
1 hdd 0.58600 osd.1 up 1.00000 1.00000
3 hdd 0.16399 osd.3 up 1.00000 1.00000
5 hdd 0.87900 osd.5 up 1.00000 1.00000
剩下就是解决一直报的鉴权文件异常问题
2022-05-07 08:44:36.093 7fcf9ed4c700 -1 asok(0x7fcf98000bf0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/guests/ceph-client.admin.56195.140529585106616.asok': (2) No such file or directory
编写重启ceph的脚本
cd /opt/sys_sh/
vi restart_ceph.sh
#!/bin/bash
mondirfile=/var/lib/ceph/mon/ceph-node1/store.db
mondir=/var/lib/ceph/mon/*
runguest=/var/run/ceph/guests/
logkvm=/var/log/qemu/
crushmap=/etc/ceph/newcrushmap
host=node1
host2=controller
echo "修改主机名为$host"
hostnamectl set-hostname $host
cd /etc/ceph
echo "检测ceph-mon服务异常并恢复重启"
if [ "$(netstat -nltp|grep ceph-mon|grep 6789|wc -l)" -eq "0" ]; then
sleep 1
if [ -e "$mondirfile" ]; then
sleep 1
else
sleep 1
rm -rf $mondir
ceph-mon --cluster ceph -i $host --mkfs --monmap /etc/ceph/monmap --keyring /etc/ceph/monkeyring -c /etc/ceph/ceph.conf
chown -R ceph:ceph $mondir
fi
systemctl reset-failed ceph-mon@node1.service
systemctl start ceph-mon@node1.service
else
sleep 1
fi
if [ "$(netstat -nltp|grep ceph-mon|grep 6781|wc -l)" -eq "0" ]; then
sleep 1
ceph-mon -i node1_bak --public-addr 10.0.0.2:6781
else
sleep 1
fi
echo "重启ceph-osd和相关所有服务"
if [ "$(ps -aux|grep ceph-mgr|wc -l)" -eq "1" ]; then
sleep 1
systemctl reset-failed ceph-mgr@node1.service
systemctl start ceph-mgr@node1.service
else
sleep 1
fi
if [ "$(ps -e|grep ceph-osd|wc -l)" -eq "$(lsblk |grep osd|wc -l)" ]; then
sleep 1
else
sleep 1
systemctl reset-failed ceph-osd@0.service
systemctl start ceph-osd@0.service
systemctl reset-failed ceph-osd@2.service
systemctl start ceph-osd@2.service
systemctl reset-failed ceph-osd@4.service
systemctl start ceph-osd@4.service
fi
if [ -d "$runguest" -a -d "$logkvm" ]; then
sleep 1
else
sleep 1
mkdir -p $runguest $logkvm
chown 777 -R $runguest $logkvm
fi
echo "重写ceph存储规则"
ceph osd setcrushmap -i $crushmap
echo "修改主机名为$host2"
hostnamectl set-hostname $host2
再执行ceph -s
可以看到错误解决
[root@node1 sys_sh(keystone)]# ceph -s
cluster:
id: 0efd6fbe-870b-41c4-92b1-d1a028d397f1
health: HEALTH_WARN
5 pool(s) have no replicas configured
application not enabled on 3 pool(s)
services:
mon: 3 daemons, quorum node1,node2,node1_bak (age 70s)
mgr: node1(active, since 15h), standbys: node2
osd: 6 osds: 6 up (since 15h), 6 in (since 23h)
data:
pools: 5 pools, 640 pgs
objects: 734 objects, 2.2 GiB
usage: 8.4 GiB used, 5.2 TiB / 5.2 TiB avail
pgs: 640 active+clean
来到节点2执行ceph -s
2022-05-07 09:51:13.625 7f1bb62a0700 -1 asok(0x7f1bb0000bf0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/guests/ceph-client.admin.259739.139756893646520.asok': (2) No such file or directory
cluster:
id: 0efd6fbe-870b-41c4-92b1-d1a028d397f1
health: HEALTH_WARN
5 pool(s) have no replicas configured
application not enabled on 3 pool(s)
services:
mon: 3 daemons, quorum node1,node2,node1_bak (age 48m)
mgr: node1(active, since 15h), standbys: node2
osd: 6 osds: 6 up (since 15h), 6 in (since 23h)
data:
pools: 5 pools, 640 pgs
objects: 734 objects, 2.2 GiB
usage: 8.4 GiB used, 5.2 TiB / 5.2 TiB avail
pgs: 640 active+clean
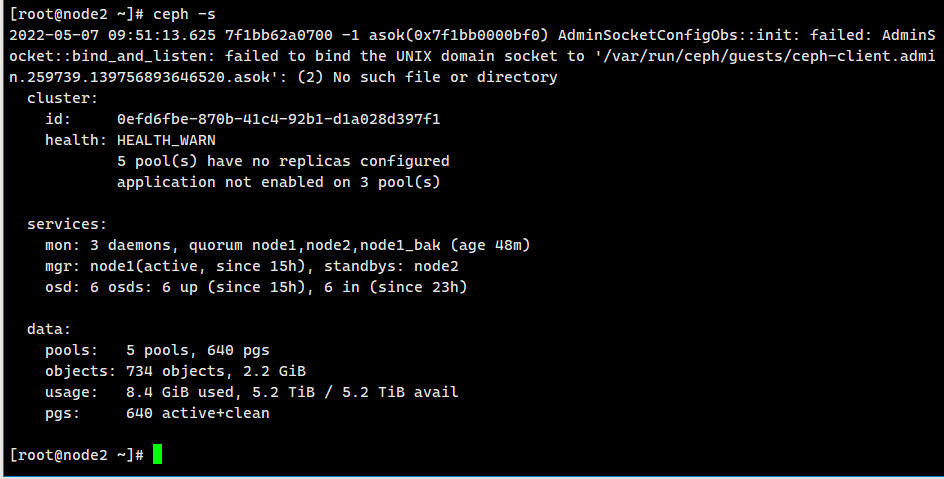
也是提示
2022-05-07 09:51:13.625 7f1bb62a0700 -1 asok(0x7f1bb0000bf0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/guests/ceph-client.admin.259739.139756893646520.asok': (2) No such file or directory
编写重启ceph的代码
cd /opt/sys_sh/
vi restart_ceph.sh
#!/bin/bash
mondirfile=/var/lib/ceph/mon/ceph-node1/store.db
mondir=/var/lib/ceph/mon
runguest=/var/run/ceph/guests/
logkvm=/var/log/qemu/
crushmap=/etc/ceph/newcrushmap
host=node2
host2=computer
echo "修改主机名为$host"
hostnamectl set-hostname $host
cd /etc/ceph
echo "检测ceph-mon服务异常并恢复重启"
if [ "$(netstat -nltp|grep ceph-mon|grep 6789|wc -l)" -eq "0" ]; then
sleep 1
if [ -e "$mondirfile" ]; then
sleep 1
else
sleep 1
rm -rf $mondir
ceph-mon --cluster ceph -i $host --mkfs --monmap /etc/ceph/monmap --keyring /etc/ceph/monkeyring -c /etc/ceph/ceph.conf
chown -R ceph:ceph $mondir
fi
systemctl reset-failed ceph-mon@node2.service
systemctl start ceph-mon@node2.service
else
sleep 1
fi
echo "重启ceph-osd和相关所有服务"
if [ "$(ps -aux|grep ceph-mgr|wc -l)" -eq "1" ]; then
sleep 1
systemctl reset-failed ceph-mgr@node2.service
systemctl start ceph-mgr@node2.service
else
sleep 1
fi
if [ "$(ps -e|grep ceph-osd|wc -l)" -eq "$(lsblk |grep osd|wc -l)" ]; then
sleep 1
else
sleep 1
systemctl reset-failed ceph-osd@1.service
systemctl start ceph-osd@1.service
systemctl reset-failed ceph-osd@3.service
systemctl start ceph-osd@3.service
systemctl reset-failed ceph-osd@5.service
systemctl start ceph-osd@5.service
fi
if [ -d "$runguest" -a -d "$logkvm" ]; then
sleep 1
else
sleep 1
mkdir -p $runguest $logkvm
chown 777 -R $runguest $logkvm
fi
echo "修改主机名为$host2"
hostnamectl set-hostname $host2
执行ceph -s可以发现问题解决
[root@node2 sys_sh]# ceph -s
cluster:
id: 0efd6fbe-870b-41c4-92b1-d1a028d397f1
health: HEALTH_WARN
5 pool(s) have no replicas configured
application not enabled on 3 pool(s)
services:
mon: 3 daemons, quorum node1,node2,node1_bak (age 59m)
mgr: node1(active, since 16h), standbys: node2
osd: 6 osds: 6 up (since 16h), 6 in (since 24h)
data:
pools: 5 pools, 640 pgs
objects: 734 objects, 2.2 GiB
usage: 8.4 GiB used, 5.2 TiB / 5.2 TiB avail
pgs: 640 active+clean
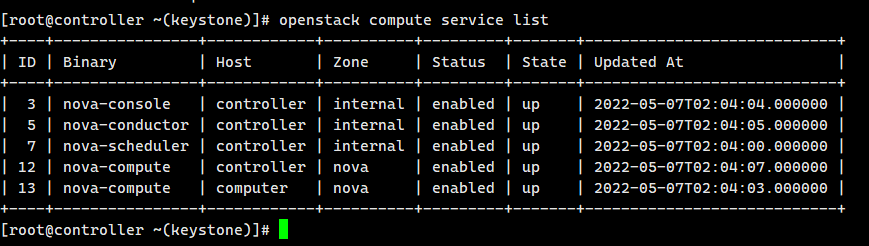
回主节点查看计算服务,可以看到计算节点连接正常
openstack compute service list
[root@controller ~(keystone)]# openstack compute service list
+----+----------------+------------+----------+---------+-------+----------------------------+
| ID | Binary | Host | Zone | Status | State | Updated At |
+----+----------------+------------+----------+---------+-------+----------------------------+
| 3 | nova-console | controller | internal | enabled | up | 2022-05-07T02:04:04.000000 |
| 5 | nova-conductor | controller | internal | enabled | up | 2022-05-07T02:04:05.000000 |
| 7 | nova-scheduler | controller | internal | enabled | up | 2022-05-07T02:04:00.000000 |
| 12 | nova-compute | controller | nova | enabled | up | 2022-05-07T02:04:07.000000 |
| 13 | nova-compute | computer | nova | enabled | up | 2022-05-07T02:04:03.000000 |
+----+----------------+------------+----------+---------+-------+----------------------------+
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
相信很多人在录制视频的时候都会遇到各种各样的问题,比如录制的视频没有声音。屏幕录制为什么没声音?今天小编就和大家分享一下如何录制音画同步视频的具体操作方法。如果你有录制的视频没有声音,你可以试试这个方法。 一、检查是否打开电脑系统声音相信很多小伙伴在录制视频后会发现录制的视频没有声音,屏幕录制为什么没声音?如果当时没有打开音频录制,则录制好的视频是没有声音的。因此,建议在录制前进行检查。屏幕上没有声音,很可能是因为你的电脑系统的声音被禁止了。您只需打开电脑系统的声音,即可录制音频和图画同步视频。操作方法:步骤1:点击电脑屏幕右下侧的“小喇叭”图案,在上方的选项中,选择“声音”。 步骤2:在“声
首先回顾一下拉格朗日定理的内容:函数f(x)是在闭区间[a,b]上连续、开区间(a,b)上可导的函数,那么至少存在一个,使得:通过这个表达式我们可以知道,f(x)是函数的主体,a和b可以看作是主体函数f(x)中所取的两个值。那么可以有, 也就意味着我们可以用来替换 这种替换可以用在求某些多项式差的极限中。方法: 外层函数f(x)是一致的,并且h(x)和g(x)是等价无穷小。此时,利用拉格朗日定理,将原式替换为 ,再进行求解,往往会省去复合函数求极限的很多麻烦。使用要注意:1.要先找到主体函数f(x),即外层函数必须相同。2.f(x)找到后,复合部分是等价无穷小。3.要满足作差的形式。如果是加
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手