目录
在"a b c d"的b后面插入3个e f g
[root@www test]# echo "a b c d" | awk '{$2=$2" e f g ";print}'
a b e f g c d
[root@www test]# echo "a b c d" | awk '{$2=$2" e f g";print}' #在awk中重新赋值后,awk会重新构建$0,也就是重构后的一行的数据
a b e f g c d
移除每行的前缀、后缀空白,并将各部分左对齐
[root@www test]# cat 2.txt #查看2.txt文件中的内容
aaaa bbbb cccc
bbb aaa ccc
ddd fff eee ggg hhhh iii jjj
[root@www test]# awk '{$1=$1;print}' 2.txt #通过$1=$1的方式来进行格式化空白,默认输出的格式为一个空格,因此看到的是每个字段之间都是通过一个空格来进行分隔
aaaa bbbb cccc
bbb aaa ccc
ddd fff eee ggg hhhh iii jjj
[root@www test]# awk 'BEGIN{OFS="\t"}{$1=$1;print}' 2.txt #通过将输出字段分隔符修改为制表符\t来进行格式化,因此看到的是每个字段之间都是通过一个制表符来进行分隔
aaaa bbbb cccc
bbb aaa ccc
ddd fff eee ggg hhhh iii jjj
[root@www test]#
从ifcofig命令的结果中筛选出除了lo网卡外的所有IPV4地址
本机的所有网卡的IP地址
[root@www test]# ifconfig
br-4d64a44d0b5a: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.18.0.1 netmask 255.255.0.0 broadcast 172.18.255.255
ether 02:42:05:3f:6a:7f txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:64:72:b8:e9 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.75.142 netmask 255.255.255.0 broadcast 192.168.75.255
inet6 fe80::e78c:a86e:3457:f77b prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:b5:49:c8 txqueuelen 1000 (Ethernet)
RX packets 37520 bytes 3100182 (2.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 99410 bytes 7526954 (7.1 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 2448 bytes 274656 (268.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2448 bytes 274656 (268.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 52:54:00:f7:4f:47 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@www test]# ifconfig | awk '/inet / && !($2 ~ /^127/){print $2}' #通过判断是否有/inet /关键字和匹配第二列不包含127开头的数字来进行匹配,满足前面的两个条件则打印第二列
172.18.0.1
172.17.0.1
192.168.75.142
192.168.122.1[root@www test]# ifconfig | awk 'BEGIN{RS=""}!/lo/{print $6}' #RS=""代表是以段落划分,此时每个网卡算是一个整体,也就是以每个段落之间的空行来作为分隔符,因此第6列就是我们需要找的IPV4地址。
172.18.0.1
172.17.0.1
192.168.75.142
192.168.122.1[root@www test]# ifconfig | awk 'BEGIN{RS="";FS="\n"}/ens33/{$0=$2;FS=" ";$0=$0;print $2}' #首先,使用RS进行段分隔,然后使用FS对段进行换行分隔。对ens33的第二列赋值给第一列(第二列将整个段落进行替换,现在只剩下第二列),再次对赋值后的第二列进行分割,通过FS为一个空格进行分隔,此时这里出现$0=$0的原因是awk的机制问题,在awk中,如果使用赋值重构,就必须通过重新赋值就是通过$0=$0这种方式进行重新渲染。此时在打印第二列就是我们所想查到的值
192.168.75.142
[base]
name=os_repo
baseurl=https://xxx/centos/$releasever/os/$basearch
gpgcheck=0
enable=1
[mysql]
name=mysql_repo
baseurl=https://xxx/mysql-repo/yum/mysql-5.7-community/el/$releasever/$basearch
gpgcheck=0
enable=1
[epel]
name=epel_repo
baseurl=https://xxx/epel/$releasever/$basearch
gpgcheck=0
enable=1
[percona]
name=percona_repo
baseurl = https://xxx/percona/release/$releasever/RPMS/$basearch
enabled = 1
gpgcheck = 0查询配置文件中mysql字段的内容
[root@www test]# cat mysql.awk
index($0, "[mysql]"){ #$0是整个文本,找到mysql字段且打印出来。下面是一个判断语句,getline代表的是只要>0就一直往下读,这里是定义了一个变量var,只要var>0就一直往下读,读到出现[.*]的时候就退出,并且打印出var,也就是一直读到的内容
print
while((getline var)>0){
if(var ~/\[.*\]/){exit}
print var
}
}
# getline返回值:>0表示已经读取到数据;=0表示遇到结尾EOF,没有读到的东西;<0读取错误
[root@www test]# awk -f mysql.awk a.txt
[mysql]
name=mysql_repo
baseurl=https://xxx/mysql-repo/yum/mysql-5.7-community/el/$releasever/$basearch
gpgcheck=0
enable=1
[root@www test]# awk 'BEGIN{RS=""}/\[mysql\]/{print;while((getline)>0){if(/\[.*\]/){exit}print}}' a.txt
[mysql]
name=mysql_repo
baseurl=https://xxx/mysql-repo/yum/mysql-5.7-community/el/$releasever/$basearch
gpgcheck=0
enable=1
去掉uid=xxx重复的行
2019-01-13_12:00_index?uid=123
2019-01-13_13:00_index?uid=123
2019-01-13_14:00_index?uid=333
2019-01-13_15:00_index?uid=9710
2019-01-14_12:00_index?uid=123
2019-01-14_13:00_index?uid=123
2019-01-15_14:00_index?uid=333
2019-01-16_15:00_index?uid=9710首先利用uid去重,我们需要利用?进行划分,然后将uid=xxx保存再数组当中,这是判断重复的依据,然后统计uid出现次数,第一次出现统计,第二次不统计
[root@www test]# awk -F"?" '!arr[$2]++{print}' b.txt
2019-01-13_12:00_index?uid=123
2019-01-13_14:00_index?uid=333
2019-01-13_15:00_index?uid=9710[root@www test]# awk -F"?" '{arr[$2]=arr[$2]+1;if(arr[$2]==1){print}}' b.txt
2019-01-13_12:00_index?uid=123
2019-01-13_14:00_index?uid=333
2019-01-13_15:00_index?uid=9710
portmapper
portmapper
portmapper
portmapper
portmapper
portmapper
status
status
mountd
mountd
mountd
mountd
mountd
mountd
nfs
nfs
nfs_acl
nfs
nfs
nfs_acl
nlockmgr
nlockmgr
nlockmgr
nlockmgr
nlockmgr[root@www test]# awk '{arr[$0]++}END{OFS="\t";for(i in arr){print arr[i], i}}' d.txt
4 nfs
2 status
5 nlockmgr
6 portmapper
2 nfs_acl
6 mountd
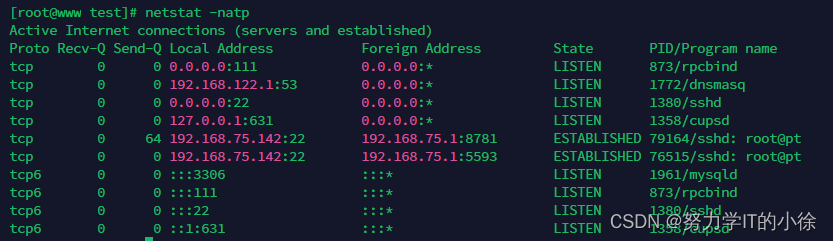
[root@www test]# netstat -antp | awk '/^tcp/{arr[$6]++}END{for(i in arr){print arr[i], i}}'
8 LISTEN
2 ESTABLISHED[root@www test]# netstat -antp | grep 'tcp' | awk '{print $6}' | sort | uniq -c
2 ESTABLISHED
8 LISTEN
日志示例数据:
[root@www logs]# cat access.log
192.168.75.1 - - [22/Mar/2023:17:05:21 +0800] "GET / HTTP/1.1" 200 645 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36" "-"
192.168.75.1 - - [22/Mar/2023:17:05:21 +0800] "GET /favicon.ico HTTP/1.1" 404 555 "http://192.168.75.142/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36" "-"
192.168.75.148 - - [22/Mar/2023:17:09:52 +0800] "GET / HTTP/1.1" 200 645 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76" "-"
192.168.75.148 - - [22/Mar/2023:17:09:52 +0800] "GET /favicon.ico HTTP/1.1" 404 555 "http://192.168.75.142/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76" "-"
统计非200状态码的IP,并且取次数最多的前10个IP
[root@www logs]# awk '$8!=200{arr[$1]++}END{for (i in arr){print arr[i],i}}' access.log | sort -k1nr | head -n 10
176 192.168.75.1
2 192.168.75.148[root@www logs]# awk '$8!=200{arr[$1]++}END{PROCINFO["sorted_in"]="@val_num_desc";for(i in arr){if(cnt++==10){exit}print arr[i],i}}' access.log
176 192.168.75.1
2 192.168.75.148
url 访问IP 访问时间 访问人
a.com.cn|202.109.134.23|2015-11-20 20:34:43|guest
b.com.cn|202.109.134.23|2015-11-20 20:34:48|guest
c.com.cn|202.109.134.24|2015-11-20 20:34:48|guest
a.com.cn|202.109.134.23|2015-11-20 20:34:43|guest
a.com.cn|202.109.134.24|2015-11-20 20:34:43|guest
b.com.cn|202.109.134.25|2015-11-20 20:34:48|guest需求:统计每个URL的独立访问IP有多少个(去重),并且要为每个URL保存一个对应的文件,得到的结果类似:
a.com.cn 2
b.com.cn 2
c.com.cn 1并且有三个对应的文件:
a.com.cn.txt
b.com.cn.txt
c.com.cn.txt
BEGIN{ #命令
FS="|"
}
!arr[$1,$2]++{
arr1[$1]++
}
END{
for(i in arr1){
print i,arr1[i] >(i".txt")
}
}
[root@www test]# cat a.com.cn.txt #查看结果
a.com.cn 2
[root@www test]# cat b.com.cn.txt
b.com.cn 2
[root@www test]# cat c.com.cn.txt
c.com.cn 1
ID name gender age email phone
1 Bob male 28 abc@qq.com 18023394012
2 Alice female 24 def@gmail.com 18084925203
3 Tony male 21 17048792503
4 Kevin male 21 bbb@189.com 17023929033
5 Alex male 18 ccc@xyz.com 18185904230
6 Andy female ddd@139.com 18923902352
7 Jerry female 25 exdsa@189.com 18785234906
8 Peter male 20 bax@qq.com 17729348758
9 Steven 23 bc@sohu.com 15947893212
10 Bruce female 27 bcbd@139.com 13942943905当字段缺失时,直接使用FS划分字段来处理会非常棘手。gawk为了解决这种特殊需求,提供了FIELDWIDTHS变量
FIELDWIDTH可以按照字符数量划分字段
awk '{print $0}' FIELDWIDTHS="2 2:6 2:6 2:3 2:13 2:11" a.txt
1 Bob male 28 abc@qq.com 18023394012
2 Alice female 24 def@gmail.com 18084925203
3 Tony male 21 17048792503
4 Kevin male 21 bbb@189.com 17023929033
5 Alex male 18 ccc@xyz.com 18185904230
6 Andy female ddd@139.com 18923902352
7 Jerry female 25 exdsa@189.com 18785234906
8 Peter male 20 bax@qq.com 17729348758
9 Steven 23 bc@sohu.com 15947893212
10 Bruce female 27 bcbd@139.com 13942943905
下面是CSV文件中的一行,该CSV文件以逗号分隔各个字段
Robbins,Arnold,"1234 A Pretty Street, NE",MyTown,MyState,12345-6789,USA需求:取得第三个字段"1234 A Pretty Street,NE"
当字段中包含了字段分隔符时,直接使用FS划分字段来处理会非常棘手。gawk为了解决这种特殊需求,提供了FPAT变量。
FPAT可以收集正则匹配的结果,并将它们保存在各个字段中。(就像grep匹配成功的部分会加颜色显示,而使用FPAT划分字段,则是将匹配成功的部分保存在字段$1 $2 $3...中)
[root@www test]# awk 'BEGIN{FPAT="[^,]+|\".*\""}{print $3}' 6.txt
"1234 A Pretty Street, NE"
16 001agdcdafasd
16 002agdcxxxxxx
23 001adfadfahoh
23 001fsdadgggggawk字符索引从1开始
[root@www test]# awk '{print $1,substr($2,1,3)}' 7.txt
16 001
16 002
23 001
23 001awk 'BEGIN{FIELDWIDTHS="2 2:3"}{print $1,$2}' 7.txt
16 001
16 002
23 001
23 001
文件内容:
name age
alice 21
ryan 30
[root@www test]# awk '{for(i=1;i<=NF;i++){if(!(i in arr)){arr[i]=$i}else{arr[i]=arr[i]" "$i}}}END{for(i=1;i<=NF;i++){print arr[i]}}' 8.txt
name alice ryan
age 21 30
分析
awk '
{
for(i=1;i<=NF;i++){ #NF代表这字段数量,所以此时的NF为2,因为只有两列
if(!(i in arr)){
arr[i]=$i
}else{
arr[i]=arr[i]" "$i
}
}
}
END{
for(i=1;i<=NF;i++){
print arr[i]
}
}
' 8.txt
文件内容:
74683 1001
74683 1002
74683 1011
74684 1000
74684 1001
74684 1002
74685 1001
74685 1011
74686 1000将文件实现成如下格式
74683 1001 1002 1011
74684 1000 1001 1002
[root@www test]# cat 9.awk
{
if($1 in arr){
arr[$1] = arr[$1]" "$2
}else{
arr[$1] = $2
}
}
END{
for(i in arr){
printf "%s %s\n",i,arr[i]
}
}
[root@www test]# awk -f 9.awk 9.txt #查看结果
74686 1000
74683 1001 1002 1011
74684 1000 1001 1002
74685 1001 1011
grep/sed/awk用正则去筛选日志时,如果要精确到小时、分钟、秒,则非常难以实现。
但是awk提供了mktime()函数,它可以将时间转为epoch(1970年到现在)时间值
# 2019-11-10 03:42:40转换成epoch
$ awk 'BEGIN{print mktime("2019 11 10 03 42 40")}'
1573328560借此。可以取得日志中的时间字符串部分,再将它们的年、月、日、时、分、秒都读取出来,然后放入nktim()构建对应的epoch值。因为epoch值是数值,所以可以比较发小、从而决定时间的大小。
下面strptime1()实现的是将10/Nov/2019:23:53:44+08:00格式的字符串转换为epoch值,然后和which_tinme比较大小即可筛选出精确到秒的日志。
BEGIN{
#要筛选什么时间的日志,将其时间构造成epoch值
which_time = mktime("2023 01 30 17 20 40")
}
{
#取出日志中的日期哦时间字符串部分
match($0,"^.*\\[(.*)\\].*",arr)
#将日期时间字符串转换为epoch值
tmp_time = strptime2(arr[1])
#通过比较epoch值来比较时间大小
if(tmp_time > whixh_time){
arr1[$1]++
}
}
END{
PROCINFO["sorted_in"]="@val_num_dexc";
for(i in arr1){
#设置计数器
if(cnt++==10){exit}
print arr1[i],i
}
}
#构建的时间字符串格式为:"10/Nov/2019:23:53:44+08:00"
function strptime2(str,dt_str,arr,Y,M,D,H,m,S){
dt_str = gensub("[/:+]"," ","g",str)
#gt_str = "10 Nov 2019 23 53 44 08 00"
split(dt_str,arr," ")
Y=arr[3]
M=mon_map(arr[2])
D=arr[1]
H=arr[4]
m=arr[5]
S=arr[6]
return mktime(sprintf("%s %s %s %s %s %s",Y,M,D,H,m,S))
}
function mon_map(str,mons){
mons["Jan"]=1
mons["Feb"]=2
mons["Mar"]=3
mons["Apr"]=4
mons["May"]=5
mons["Jun"]=6
mons["Jul"]=7
mons["Aug"]=8
mons["Sep"]=9
mons["Oct"]=10
mons["Nov"]=11
mons["Dec"]=12
return mons[str]
}嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
有点边缘情况,但知道为什么&&=会这样吗?我正在使用1.9.2。obj=Object.newobj.instance_eval{@bar&&=@bar}#=>nil,expectedobj.instance_variables#=>[],soobjhasno@barinstancevariableobj.instance_eval{@bar=@bar&&@bar}#ostensiblythesameas@bar&&=@barobj.instance_variables#=>[:@bar]#whywouldthisversioninitialize@bar?为了比较,||=将实例变量初始
最近在工作中,看到一些新手测试同学,对接口测试存在很多疑问,甚至包括一些从事软件测试3,5年的同学,在聊到接口时,也是一知半解;今天借着这个机会,对接口测试做个实战教学,顺便总结一下经验,分享给大家。计划拆分成4个模块跟大家做一个分享,(接口测试、接口基础知识、接口自动化、接口进阶)感兴趣的小伙伴记得关注,希望对你的日常工作和求职面试,带来一些帮助。注:文章较长有5000多字,希望小伙伴们认真看完,当然有些内容对小白同学不是太友好,如果你需要详细了解其中的一些概念或者名词,请在文章之后留言,后续我将针对大家的疑问,整理输出一些大家感兴趣的文章。随着开发模式的迭代更新,前后端分离已不是新的概念,
描述恺撒密码是古罗马凯撒大帝用来对军事情报进行加解密的算法,它采用了替换方法对信息中的每一个英文字符循环替换为字母表序列中该字符后面的第三个字符,即,字母表的对应关系如下:原文:ABCDEFGHIJKLMNOPQRSTUVWXYZ
本人是音乐爱好者,从小就特别喜欢那个随着音乐跳动的方框效果,就是这个:arduino上一大把对,我忍你很久了,我就想用mpy做,全网没有,行我自己研究。果然兴趣是最好的老师,我之前有篇博客专门讲音频,有兴趣的可以回顾一下。提到可视化频谱,必然绕不开fft,大学学过这玩意,当时一心玩,老师讲的一个字都么听进去,网上教程简略扫了一下,大该就是把时域转频域的工具,我大mpy居然没有fft函数,奶奶的,先放着。音频信息如何收集?第一种傻瓜式的ADC,模拟转数字,原始粗暴,第二种,I2S库,我之前博客有讲过,数据是PCM编码。然后又去学PCM编码,一学豁然开朗,舒服,以代码为例:audio_in=I2S
在使用Rubyv2.2.2的ElCapitan(MacOSX10.11.1)上安装Rails时,出现以下错误:ERROR:Errorinstallingnokogiri:ERROR:Failedtobuildgemnativeextension./Users/jon/.rvm/rubies/ruby-2.2.2/bin/ruby-r./siteconf20151117-26799-ux15fd.rbextconf.rb--use-system-librariescheckingiftheCcompileraccepts...***extconf.rbfailed***Couldnotc