在软件发开技术管理里有两个永恒经典的问题,适合我们初到一家软件企业或一家公司的科技团队,来判断自己该从哪里入手帮助整个团队提升科技水平和产能。问题一是“在我们团队里,只涉及一行代码的变更需要多久才能上线?”,问题二是“在我们团队里,定位一个线上问题需要多久?流程是什么?”。问题一关注的是“交付”,问题二关注的是“保障”。今天写这边文章跟大家聊聊有关问题二的故事。
不怕大家笑话,我最初的公司每个服务生产上就两台Tomcat。定位生产问题,就是连上一台机器,然后用使用 cd / tail / grep / sed / awk 等 Linux 脚本去日志里查找故障原因。如果发现不在这台机器上,就去另一台机器上查日志。(如果你现在的公司还是这样干,记住出去面试的时候也不要说是这样干,不然很容易由于你之前的公司的整体技术水平太low而把你pass掉)
但在应用服务器规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
以搜索引擎闻名世界的开源软件提供商-Elastic为我们大家提供了一套完整的日志收集以及展示的解决方案——ELK。是三个产品的首字母缩写,分别是ElasticSearch、Logstash 和 Kibana。
Logstash主要是用来负责搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
ElasticSearch用来负责存储最终数据、建立索引和对外提供搜索日志的功能。它是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Kibana是一个优秀的前端日志展示框架,它可以非常详细的将日志转化为各种图表,为用户提供强大的数据可视化支持。


这是最简单的ELK架构,这种架构下我们把 Logstash实例与Elasticsearch实例直接相连,主要就是图一个简单。我们的程序App将日志写入Log,然后Logstash将Log读出,进行过滤,写入Elasticsearch。最后浏览器访问Kibana,提供一个可视化输出。
入门级版本的缺点主要是两个
于是我们作为公司最牛的架构师,提出了一个升级版的ELK架构,解决如上两个问题。
在这版中,加入一个缓冲中间件(消息队列)。另外对Logstash拆分为Shipper和Indexer。先说一下,LogStash自身没有什么角色,只是根据不同的功能、不同的配置给出不同的称呼而已。Shipper来进行日志收集,Indexer从缓冲中间件接收日志,过滤输出到Elasticsearch。具体如下图所示
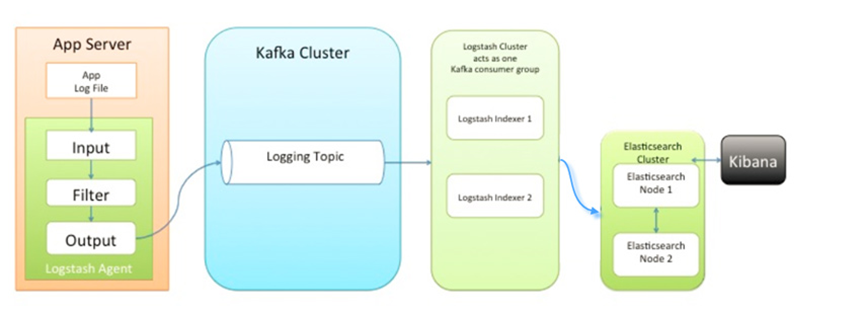
大家会发现,早期的博客,都是推荐使用redis。因为这是ELK Stack 官网建议使用 Redis 来做消息队列,但是很多大佬已经通过实践证明使用Kafka更加优秀。原因如下:
但这个升级版仍然存在缺陷:
于是我们给我们在Elastic公司的朋友打了个电话,说明了他们这个集中型日志解决方案的弊端——太费CPU也就太费电。Elastic公司的朋友电话中告诉我们最近新研发了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
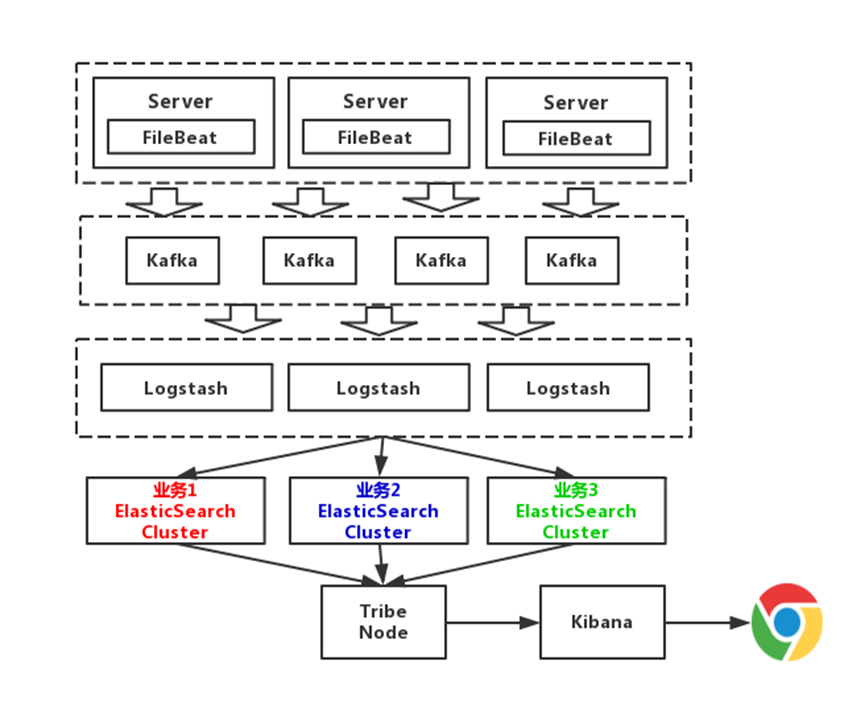
从上图可以看到,Elasticsearch根据业务部了3个集群,他们之间相互独立。避免出现,一个业务拖垮了Elasticsearch集群,整个日志系统就一起宕机的情况。而且,从运维角度来说,这种架构运维起来也更加方便。
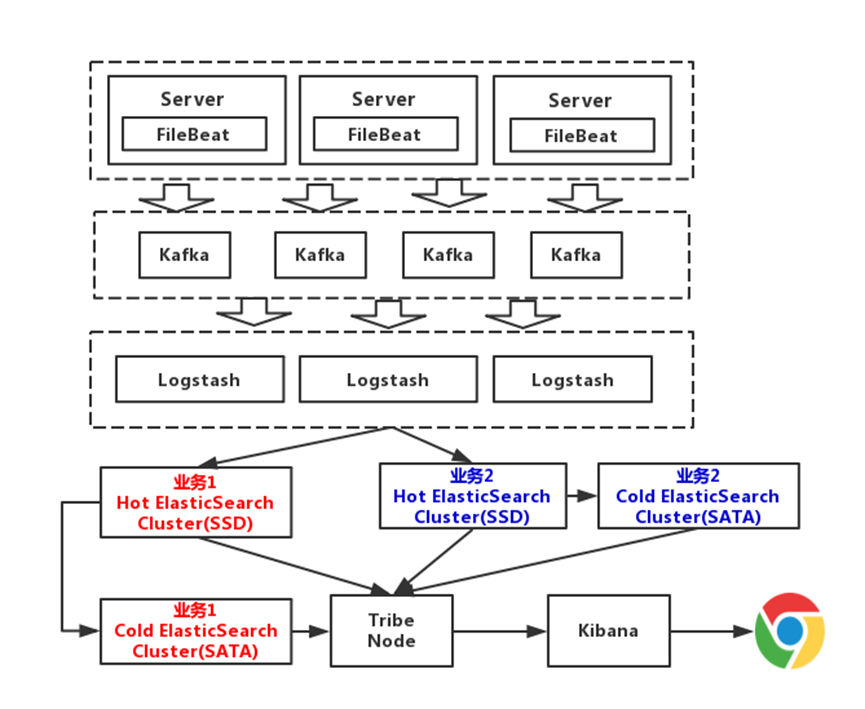
这套架构的缺点在于对日志没有进行冷热分离。因为我们一般来说,一个月之内不排查的错误日志,那都是不重要的错误。以30天作为界限,区分冷热数据,可以大大的优化查询速度。
这一版,我们对数据进行冷热分离。每个业务准备两个Elasticsearch集群,可以理解为冷热集群。7天以内的数据,存入热集群,以SSD存储索引。超过7天,就进入冷集群,以SATA存储索引。这么一改动,性能又得到提升
Filebeat由两个主要组件组成:prospectors 和 harvesters。这两个组件协同工作将文件变动发送到指定的输出中。
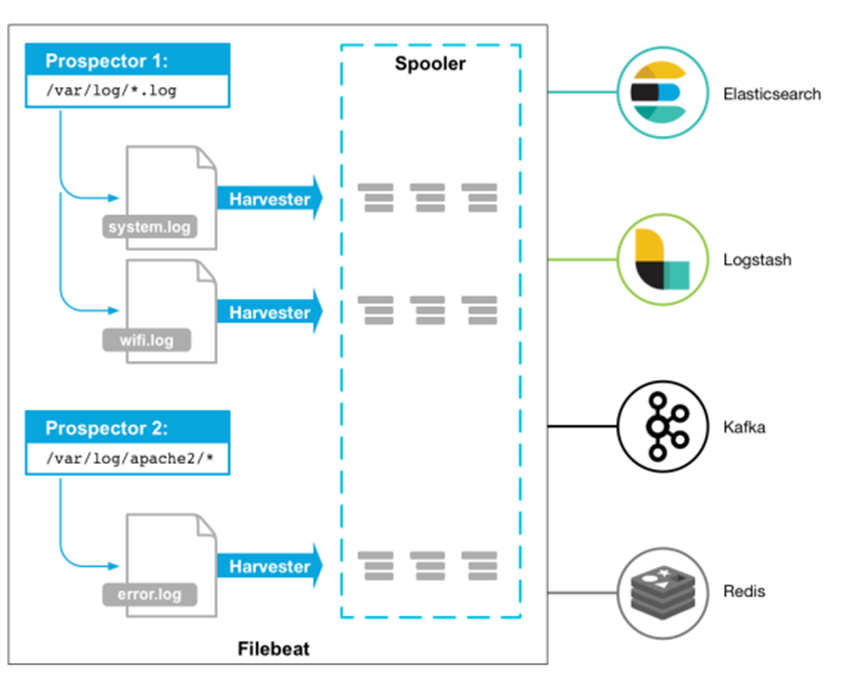
Harvester(收割机):负责读取单个文件内容。每个文件会启动一个Harvester,每个Harvester会逐行读取各个文件,并将文件内容发送到制定输出中。Harvester负责打开和关闭文件,意味在Harvester运行的时候,文件描述符处于打开状态,如果文件在收集中被重命名或者被删除,Filebeat会继续读取此文件。所以在Harvester关闭之前,磁盘不会被释放。默认情况filebeat会保持文件打开的状态,直到达到close_inactive(如果此选项开启,filebeat会在指定时间内将不再更新的文件句柄关闭,时间从harvester读取最后一行的时间开始计时。若文件句柄被关闭后,文件发生变化,则会启动一个新的harvester。关闭文件句柄的时间不取决于文件的修改时间,若此参数配置不当,则可能发生日志不实时的情况,由scan_frequency参数决定,默认10s。Harvester使用内部时间戳来记录文件最后被收集的时间。例如:设置5m,则在Harvester读取文件的最后一行之后,开始倒计时5分钟,若5分钟内文件无变化,则关闭文件句柄。默认5m)。
Prospector(勘测者):负责管理Harvester并找到所有读取源。
Prospector会找到/apps/logs/*目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
Filebeat如何记录文件状态:
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
Filebeat如何保证事件至少被输出一次:
Filebeat之所以能保证事件至少被传递到配置的输出一次,没有数据丢失,是因为filebeat将每个事件的传递状态保存在文件中。在未得到输出方确认时,filebeat会尝试一直发送,直到得到回应。若filebeat在传输过程中被关闭,则不会再关闭之前确认所有时事件。任何在filebeat关闭之前为确认的时间,都会在filebeat重启之后重新发送。这可确保至少发送一次,但有可能会重复。可通过设置shutdown_timeout 参数来设置关闭之前的等待事件回应的时间(默认禁用)。
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
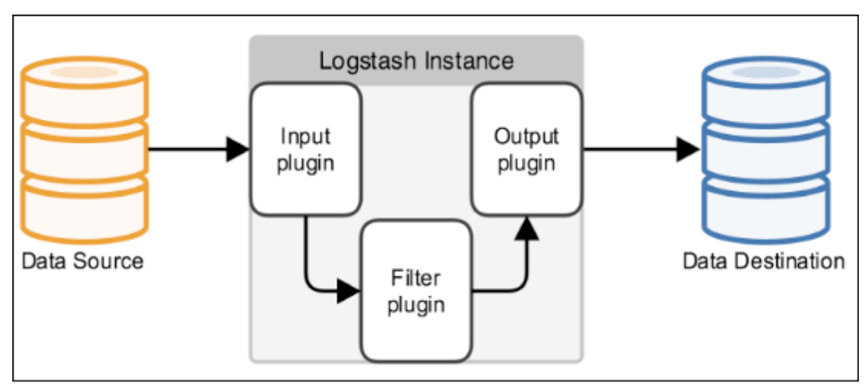
Input:输入数据到logstash,一些常用的输入为:
file:从文件系统的文件中读取,类似于tail -f命令
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
redis:从redis service中读取
beats:从filebeat中读取
Filters:数据中间处理,对数据进行操作。
一些常用的过滤器为:
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。内置120多个解析语法。(官方提供的grok表达式:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
grok在线调试:https://grokdebug.herokuapp.com/)
mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
Outputs:outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。一些常见的outputs为:
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
举个例子,现在我们要保存唐宋诗词,关系型数据库中我们们会怎么设计?诗词表我们可能的设计如下:
|
朝代 |
作者 |
标题 |
诗词全文 |
|
唐 |
李白 |
静夜思 |
床前明月光,疑是地上霜。举头望明月,低头思故乡。 |
|
宋 |
李清照 |
如梦令 |
常记溪亭日暮,沉醉不知归路,兴尽晚回舟,误入藕花深处。争渡,争渡,惊起一滩鸥鹭。 |
要根据朝代或者作者寻找诗,都很简单,比如“select 诗词全文 from 诗词表where作者=‘李白’”,如果数据很多,查询速度很慢,怎么办?我们可以在对应的查询字段上建立索引加速查询。
但是如果我们现在有个需求:要求找到包含“望”字的诗词怎么办?用
“select 诗词全文 from 诗词表 where 诗词全文 like‘%望%’”,这个意味着
要扫描库中的诗词全文字段,逐条比对,找出所有包含关键词“望”字的记录,。
基本上,数据库中一般的 SQL 优化手段都是用不上的。数量少,大概性能还能接受,如果数据量稍微大点,就完全无法接受了,更何况在互联网这种海量数据的情况下呢?
怎么解决这个问题呢,用倒排索引Inverted index
比如现在有:
蜀道难(唐)李白 蜀道之难难于上青天,侧身西望长咨嗟。
静夜思(唐)李白 举头望明月,低头思故乡。
春台望(唐)李隆基 暇景属三春,高台聊四望。
鹤冲天(宋)柳永 黄金榜上,偶失龙头望。明代暂遗贤,如何向?未遂风云便,争不恣狂荡。何须论得丧?才子词人,自是白衣卿相。烟花巷陌,依约丹青屏障。
幸有意中人,堪寻访。且恁偎红翠,风流事,平生畅。青春都一饷。忍把浮名,换了浅斟低唱!
这些诗词都有望字,于是我们可以这么保存
|
序号 |
关键字 |
蜀道难 |
静夜思 |
春台望 |
鹤冲天 |
|
1 |
望 |
有 |
有 |
有 |
有 |
|
|
|
|
|
|
|
其实,上述诗词的中每个字都可以作为关键字,然后建立关键字和文档之间的对应关系,也就是标识关键字被哪些文档包含。
所以,倒排索引就是,将文档中包含的关键字全部提取处理,然后再将关键字和文档之间的对应关系保存起来,最后再对关键字本身做索引排序。用户在检索某一个关键字是,先对关键字的索引进行查找,再通过关键字与文档的对应关系找到所在文档。
Elasticsearch 索引是映射类型的容器。一个 Elasticsearch 索引非常像关系型世界的数据库,是独立的大量文档集合。
当然在底层,肯定用到了倒排索引,最基本的结构就是“keyword”和“PostingList”,Posting list就是一个 int的数组,存储了所有符合某个 term的文档 id。
另外,这个倒排索引相比特定词项出现过的文档列表,会包含更多其它信息。
它会保存每一个词项出现过的文档总数,在对应的文档中一个具体词项出现的总次数,词项在文档中的顺序,每个文档的长度,所有文档的平均长度等等相关信息。
作者:谭文涛 2021-12-31
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
我正在使用此代码在我的Sinatra应用程序中启用日志记录:log_file=File.new('my_log_file.log',"a")$stdout.reopen(log_file)$stderr.reopen(log_file)$stdout.sync=true$stderr.sync=true实际的日志记录是使用:logger.debug("Startingcall.Params=#{params.inspect}")事实证明,只有INFO或更高级别的日志消息被记录,而DEBUG消息没有被记录。我正在寻找一种将日志级别设置为DEBUG的方法。 最佳
我有这段代码来跟踪远程日志文件:defdo_tail(session,file)session.open_channeldo|channel|channel.on_datado|ch,data|puts"[#{file}]->#{data}"endchannel.exec"tail-f#{file}"endNet::SSH.start("host","user",:password=>"passwd")do|session|do_tailsession,"/path_to_log/file.log"session.loop我只想在file.log中检索带有ERROR字符串的行,我正在尝
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion我想知道是否有人知道Ruby的rubyzip替代品,它可以处理各种格式,特别是zip/rar/7z?我知道libarchive,但它对我的目的来说并不完整(它是一个很好的gem)。(澄清一下,libarchive-对我不起作用-因为