大家好,我是小哈。
本小节中,我们将学习如何通过 Mybatis Plus 框架给数据库表新增数据,主要内容思维导图如下:
 Mybatis Plus 新增数据思维导图
Mybatis Plus 新增数据思维导图
为了演示新增数据,在前面小节中,我们已经定义好了一个用于测试的用户表, 执行脚本如下:
DROP TABLE IF EXISTS t_user;
CREATE TABLE `t_user` ( `id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID', `name` varchar(30) NOT NULL DEFAULT '' COMMENT '姓名', `age` int(11) NULL DEFAULT NULL COMMENT '年龄', `gender` tinyint(2) NOT NULL DEFAULT 0 COMMENT '性别,0:女 1:男', PRIMARY KEY (`id`) ) COMMENT = '用户表'; 定义一个名为 User 实体类:
@Data
@TableName("t_user")
public class User {
/**
* 主键 ID, @TableId 注解定义字段为表的主键,type 表示主键类型,IdType.AUTO 表示随着数据库 ID 自增
*/
@TableId(type = IdType.AUTO) private Long id; /** * 姓名 */ private String name; /** * 年龄 */ private Integer age; /** * 性别 */ private Integer gender; } 讲解一下实体类中用到的注解:
作用:标识实体类对应的表。
TIP :
- 当实体类名称和实际表名一致时,如实体名为
User, 表名为user,可不用添加该注解,Mybatis Plus 会自动识别并映射到该表。- 当实体类名称和实际表名不一致时,如实体名为
User, 表名为t_user,需手动添加该注解,并填写实际表名称。
作用:声明实体类中的主键对应的字段。
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 主键字段名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(默认) |
| INPUT | 插入数据前,需自行设置主键的值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID (默认 default 方法) |
分布式全局唯一 ID 长整型类型 (推荐使用 ASSIGN_ID) | |
32 位 UUID 字符串 (推荐使用 ASSIGN_UUID) | |
分布式全局唯一 ID 字符串类型 (推荐使用 ASSIGN_ID) |
测试表准备好后,我们准备开始演示新增数据。实际上,Mybatis Plus 对 Mapper 层和 Service 层都将常见的增删改查操作都封装好了,只需简单的继承,即可轻松搞定对数据的增删改查,本文重点讲解新增数据这块。
定义一个 UserMapper , 让其继承 BaseMapper :
public interface UserMapper extends BaseMapper<User> { } 然后,注入 Mapper :
@Autowired
private UserMapper userMapper;
BaseMapper 提供的新增方法仅一个 insert() 方法:

我们通过它测试一下添加数据,并获取主键 ID :
User user =new User();
user.setName("犬小哈");
user.setAge(30);
user.setGender(1);
userMapper.insert(user);
// 获取插入数据的主键 ID Long id = user.getId(); System.out.println("id:" + id); 怎么样,是不是非常简单呢!
Mybatis Plus 同样也封装了通用的 Service 层 CRUD 操作,并且提供了更丰富的方法。接下来,我们上手看 Service 层的代码结构,如下图:
 定义 Service 层
定义 Service 层
先定义 UserService 接口 ,让其继承自 IService:
public interface UserService extends IService<User> { } 再定义实现类 UserServiceImpl,让其继承自 ServiceImpl, 同时实现 UserService 接口,这样就可以让 UserService 拥有了基础通用的 CRUD 功能,当然,实际开发中,业务会更加复杂,就需要向 IService 接口自定义方法并实现:
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService { } 注入 UserService :
@Autowired
private UserService userService;
与 Mapper 层不同的是,Service 层的新增方法均以 save 开头,并且功能更丰富,来看看都提供了哪些方法:
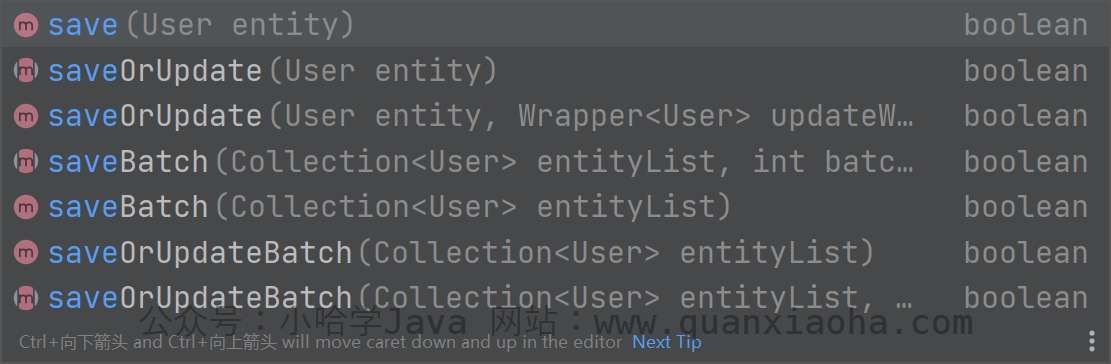 新增数据共有 6 个方法
新增数据共有 6 个方法
简单解释下每个方法的作用,以作了解:
// 新增数据
sava(T) : boolean
// 伪批量插入,实际上是通过 for 循环一条一条的插入
savaBatch(Collection<T>) : boolean
// 伪批量插入,int 表示批量提交数,默认为 1000 savaBatch(Collection<T>, int) : boolean // 新增或更新(单条数据) saveOrUpdate(T) : boolean // 批量新增或更新 saveOrUpdateBatch(Collection<T>) : boolean // 批量新增或更新(可指定批量提交数) saveOrUpdateBatch(Collection<T>, int) : boolean 大致看完后,上手测试一下。
简单的新增数据,示例代码如下:
// 新增数据
// 实际执行 SQL :INSERT INTO user ( name, age, gender ) VALUES ( '小哈 111', 30, 1 ) User user = new User(); user.setName("小哈 111"); user.setAge(30); user.setGender(1); boolean isSuccess = userService.save(user); // 返回主键ID Long id = user.getId(); System.out.println("isSuccess:" + isSuccess); System.out.println("主键 ID: " + id); 伪批量插入,注意,命名虽然包含了批量的意思,但这不是真的批量插入,不信的话,我们来实际测试一下:
// 批量插入
List<User> users = new ArrayList<>();
for (int i = 0; i < 5; i++) { User user = new User(); user.setName("犬小哈" + i); user.setAge(i); user.setGender(1); users.add(user); } boolean isSuccess = userService.saveBatch(users); System.out.println("isSuccess:" + isSuccess); 执行代码,实际执行的 SQL 如下:
TIP : 如何打印实际执行的 SQL, 可参考之前小节的 《Mybatis Plus 打印 SQL 语句(包含执行耗时)》 。
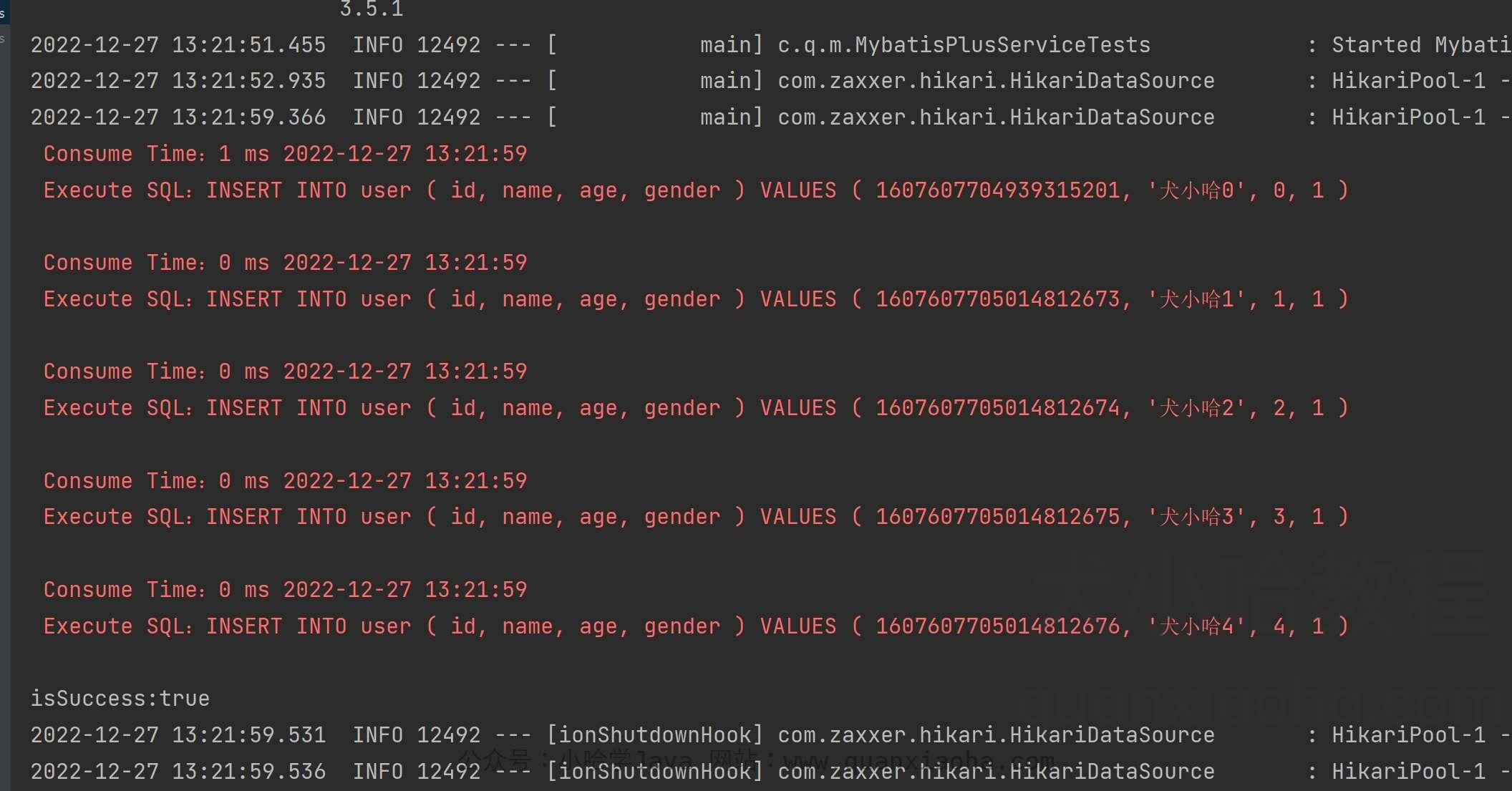 批量插入输入 SQL 打印
批量插入输入 SQL 打印
可以看到,并不是 insert into user (xxx) values (xxx),(xxx),(xxx) 这种批量形式,还是一条一条插入的。
我们来看下源码, 内部的saveBatch() 方法默认的批量提交阀值参数,数值为 1000, 即达到 1000 条批量提交一次,继续点进去看::

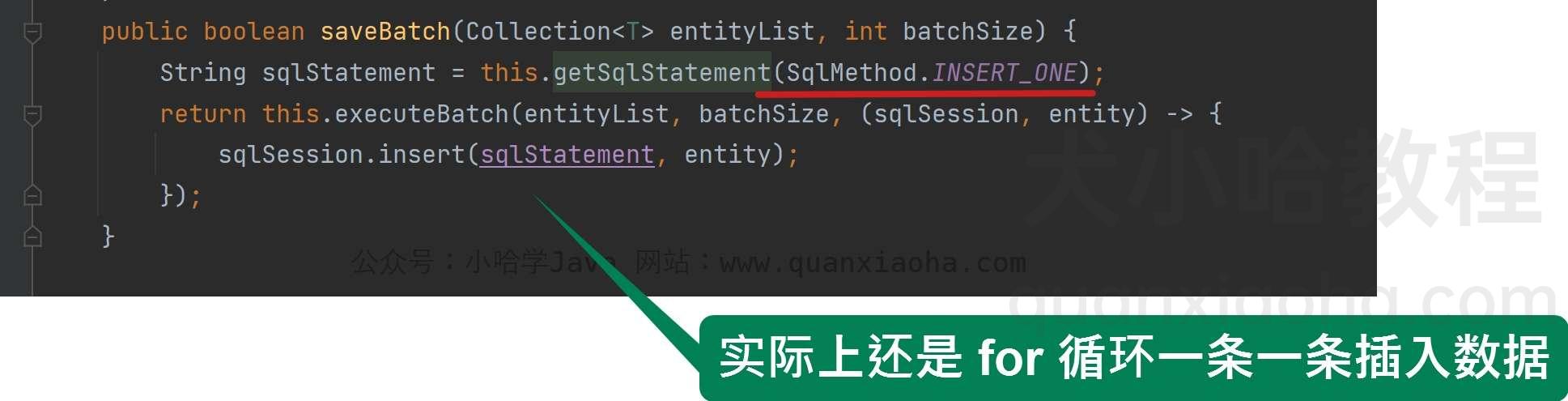 源码分析
源码分析
public boolean saveBatch(Collection<T> entityList, int batchSize) { // 获取预编译的插入 SQL String sqlStatement = this.getSqlStatement(SqlMethod.INSERT_ONE); // for 循环执行 insert return this.executeBatch(entityList, batchSize, (sqlSession, entity) -> { sqlSession.insert(sqlStatement, entity); }); } 再看下 SqlMethod.INSERT_ONE 这个枚举,描述信息为插入一条数据:

继续往 executeBatch() 方法里看,瞅瞅它这个批量到底是怎么处理的,具体每行代码的意思,小哈都加了注释:
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) { // 断言需要批处理数据集大小不等于1 Assert.isFalse(batchSize < 1, "batchSize must not be less than one", new Object[0]); // 判空数据集,若不为空,则开始执行批量处理 return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, (sqlSession) -> { int size = list.size(); // 将批处理大小与传入的操作集合大小进行比较,取最小的那个 int idxLimit = Math.min(batchSize, size); int i = 1; // 迭代器循环 for(Iterator var7 = list.iterator(); var7.hasNext(); ++i) { // 获取当前需要执行的数据库操作 E element = var7.next(); // 回调 sqlSession.insert() 方法 consumer.accept(sqlSession, element); // 判断是否达到需要批处理的阀值 if (i == idxLimit) { // 开始批处理,此方法执行并清除缓存在 JDBC 驱动类中的执行语句 sqlSession.flushStatements(); idxLimit = Math.min(idxLimit + batchSize, size); } } }); } 看完就明白了,相比较自己手动 for 循环执行插入,Mybatis Plus 这个伪批量插入性能会更好些,内部会将每次的插入语句缓存起来,等到达到 1000 条的时候,才会统一推给数据库,虽然最终在数据库那边还是一条一条的执行 INSERT,但还是在和数据库交互的 IO 上做了优化。
多了个 batchSize 参数,可以手动指定批处理的大小,即多少 SQL 操作执行一次,默认为 1000。
保存或者更新。即当你需要执行的数据,数据库中不存在时,就执行插入操作:
// 实际执行 SQL :INSERT INTO user ( name, age, gender ) VALUES ( '小小哈', 60, 1 ) User user = new User(); user.setName("小小哈"); user.setAge(60); user.setGender(1); userService.saveOrUpdate(user); 当你需要执行的数据,数据库中已存在时,就执行更新操作。框架是如何判断该记录是否存在呢? 如设置了主键 ID,因为主键 ID 必须是唯一的,Mybatis Plus 会先执行查询操作,判断数据是否存在,存在即执行更新,否则,执行插入操作:
User user =new User();
// 设置了主键字段
user.setId(21L);
user.setName("小小哈");
user.setAge(60); user.setGender(1); userService.saveOrUpdate(user); 具体执行 SQL 如下:

批量保存或者更新,示例代码如下:
List<User> users =new ArrayList<>();
for (int i = 0; i < 5; i++) { User user = new User(); user.setId(Long.valueOf(i)); user.setName("犬小哈" + i); user.setAge(i+1); user.setGender(1); users.add(user); } userService.saveOrUpdateBatch(users); 批量保存或者更新(可手动指定批量大小),示例代码如下:
List<User> users =new ArrayList<>();
for (int i = 0; i < 5; i++) { User user = new User(); user.setId(Long.valueOf(i)); user.setName("犬小哈" + i); user.setAge(i+1); user.setGender(1); users.add(user); } userService.saveOrUpdateBatch(users, 100);我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
我有一个包含多个键的散列和一个字符串,该字符串不包含散列中的任何键或包含一个键。h={"k1"=>"v1","k2"=>"v2","k3"=>"v3"}s="thisisanexamplestringthatmightoccurwithakeysomewhereinthestringk1(withspecialcharacterslike(^&*$#@!^&&*))"检查s是否包含h中的任何键的最佳方法是什么,如果包含,则返回它包含的键的值?例如,对于上面的h和s的例子,输出应该是v1。编辑:只有字符串是用户定义的。哈希将始终相同。 最佳答案
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我一直很高兴地使用DelayedJob习惯用法:foo.send_later(:bar)这会调用DelayedJob进程中对象foo的方法bar。我一直在使用DaemonSpawn在我的服务器上启动DelayedJob进程。但是...如果foo抛出异常,Hoptoad不会捕获它。这是任何这些包中的错误...还是我需要更改某些配置...或者我是否需要在DS或DJ中插入一些异常处理来调用Hoptoad通知程序?回应下面的第一条评论。classDelayedJobWorker 最佳答案 尝试monkeypatchingDelayed::W
所以我开始关注ruby,很多东西看起来不错,但我对隐式return语句很反感。我理解默认情况下让所有内容返回self或nil但不是语句的最后一个值。对我来说,它看起来非常脆弱(尤其是)如果你正在使用一个不打算返回某些东西的方法(尤其是一个改变状态/破坏性方法的函数!),其他人可能最终依赖于一个返回对方法的目的并不重要,并且有很大的改变机会。隐式返回有什么意义?有没有办法让事情变得更简单?总是有返回以防止隐含返回被认为是好的做法吗?我是不是太担心这个了?附言当人们想要从方法中返回特定的东西时,他们是否经常使用隐式返回,这不是让你组中的其他人更容易破坏彼此的代码吗?当然,记录一切并给出
为什么以下不同?Time.now.end_of_day==Time.now.end_of_day-0.days#falseTime.now.end_of_day.to_s==Time.now.end_of_day-0.days.to_s#true 最佳答案 因为纳秒数不同:ruby-1.9.2-p180:014>(Time.now.end_of_day-0.days).nsec=>999999000ruby-1.9.2-p180:015>Time.now.end_of_day.nsec=>999999998
在Ruby1.9.3(可能还有更早的版本,不确定)中,我试图弄清楚为什么Ruby的String#split方法会给我某些结果。我得到的结果似乎与我的预期相反。这是一个例子:"abcabc".split("b")#=>["a","ca","c"]"abcabc".split("a")#=>["","bc","bc"]"abcabc".split("c")#=>["ab","ab"]在这里,第一个示例返回的正是我所期望的。但在第二个示例中,我很困惑为什么#split返回零长度字符串作为返回数组的第一个值。这是什么原因呢?这是我所期望的:"abcabc".split("a")#=>["bc"
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_