目录
es下载地址
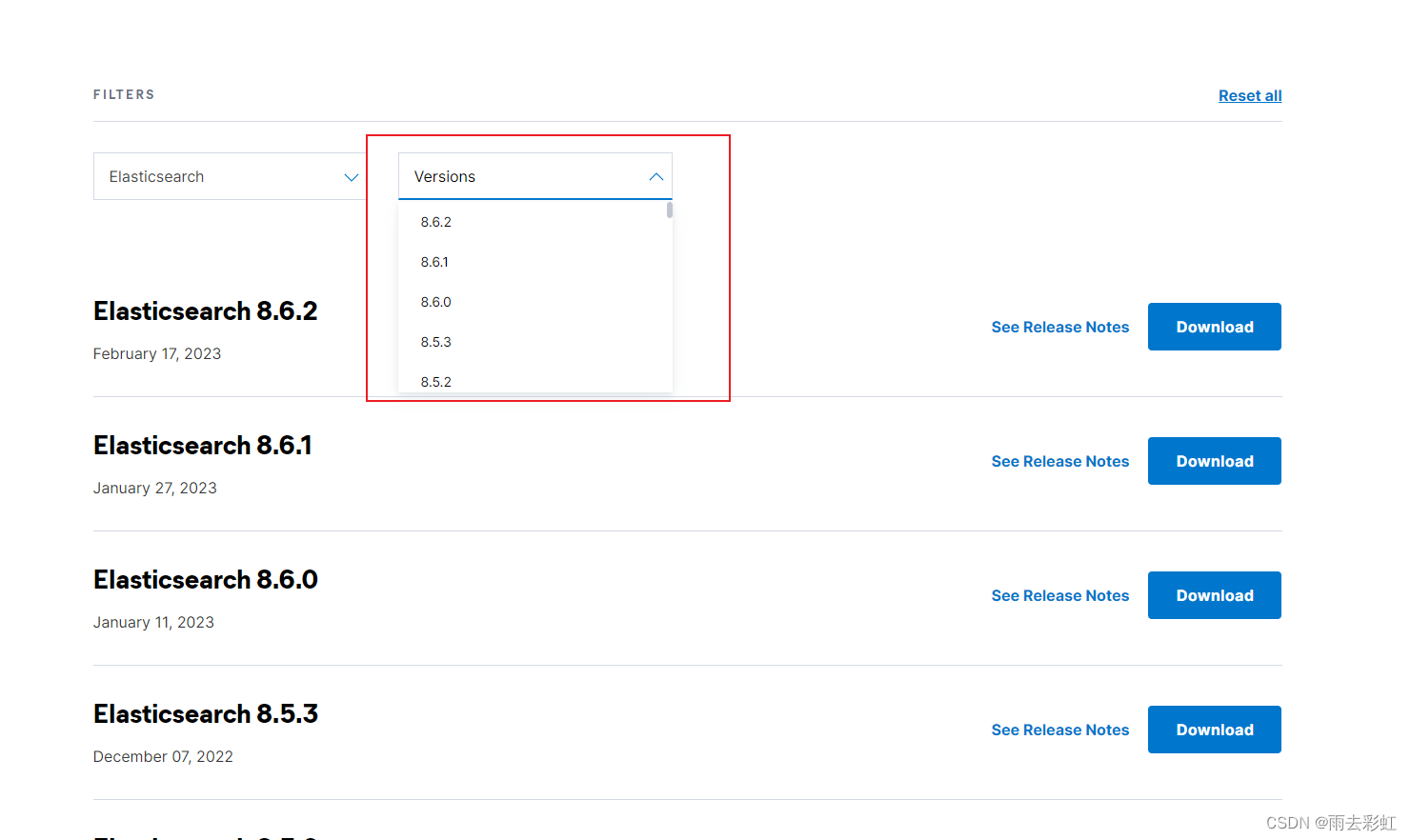
这里我下载的是
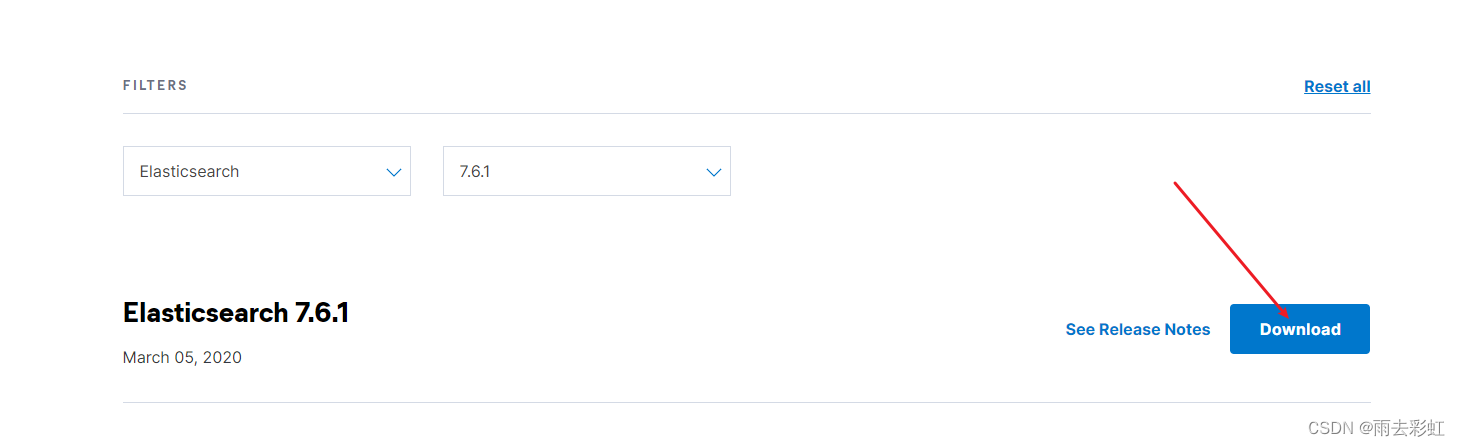
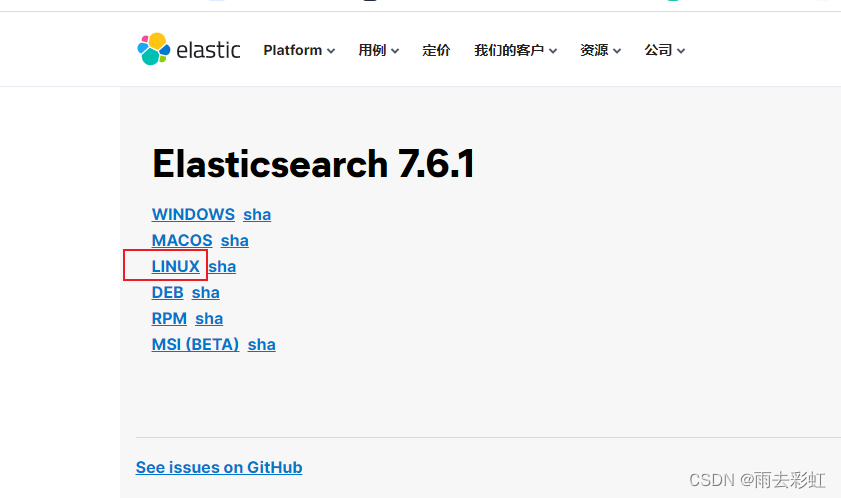
上传方式有两种
第一种:使用xftp上传
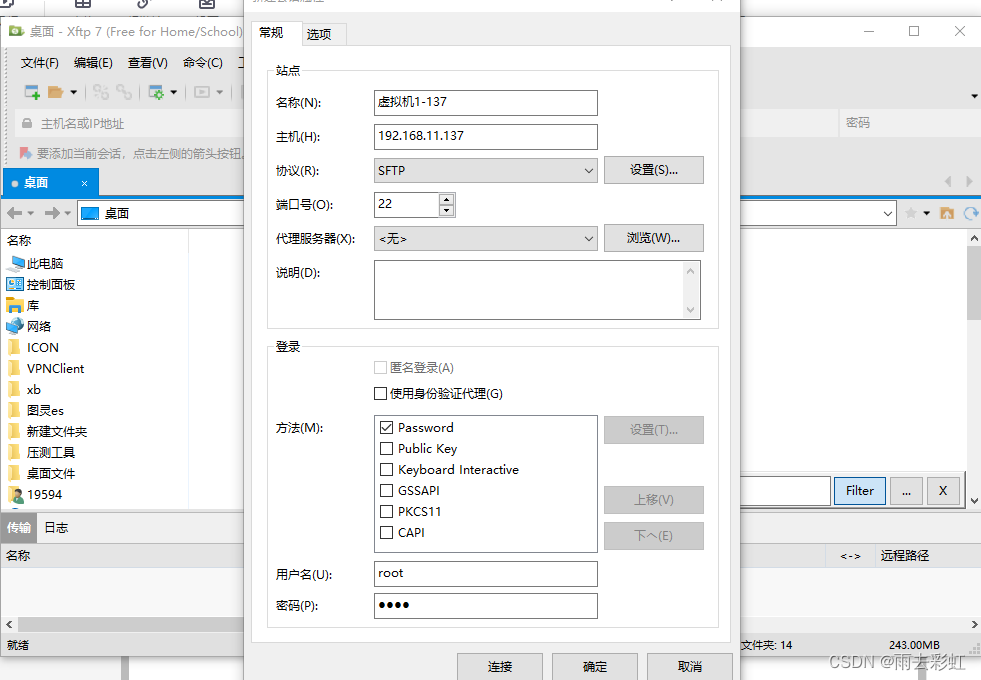
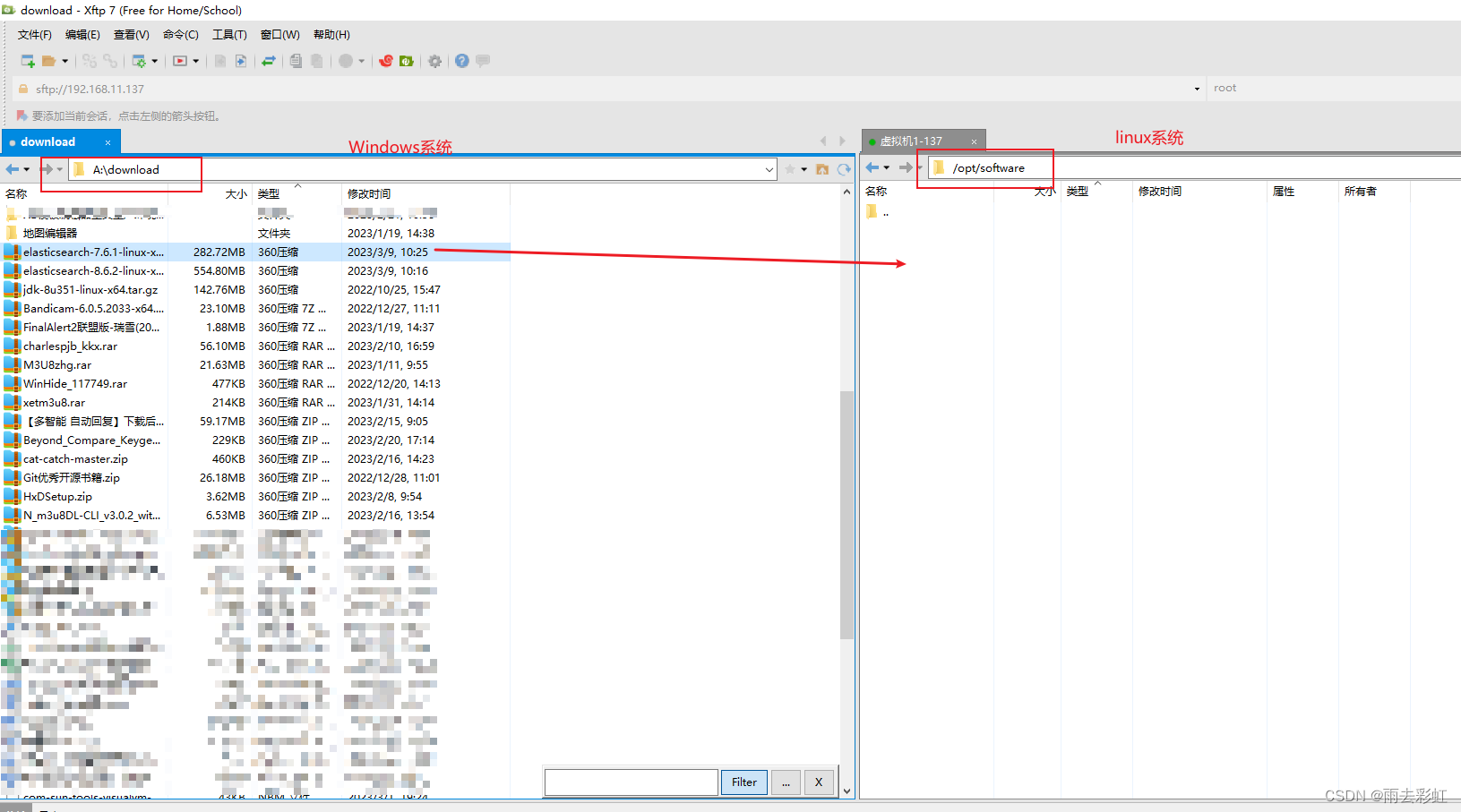
直接拖动过去就可以了。
第二种:使用lrzsz
先安装
yum -y install lrzsz
切换到要上传的位置
cd /opt/module
输入命令
rz
选择你要上传的文件
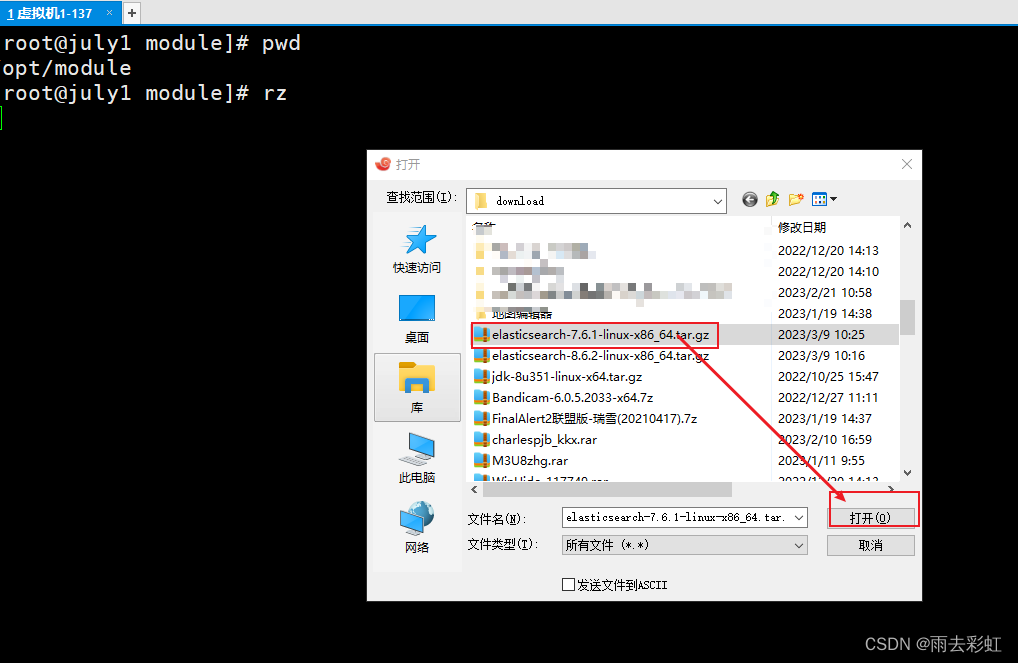
等待上传完成即可
①解压到指定目录下
tar -zxvf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /opt/software/
②修改/config下的elasticsearch.yml
cd /opt/software/elasticsearch-7.6.1/config/
vim elasticsearch.yml
加入如下配置
cluster.name: elasticsearch
node.name: node-1
network.host: 192.168.11.137 #虚拟机的IP地址
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
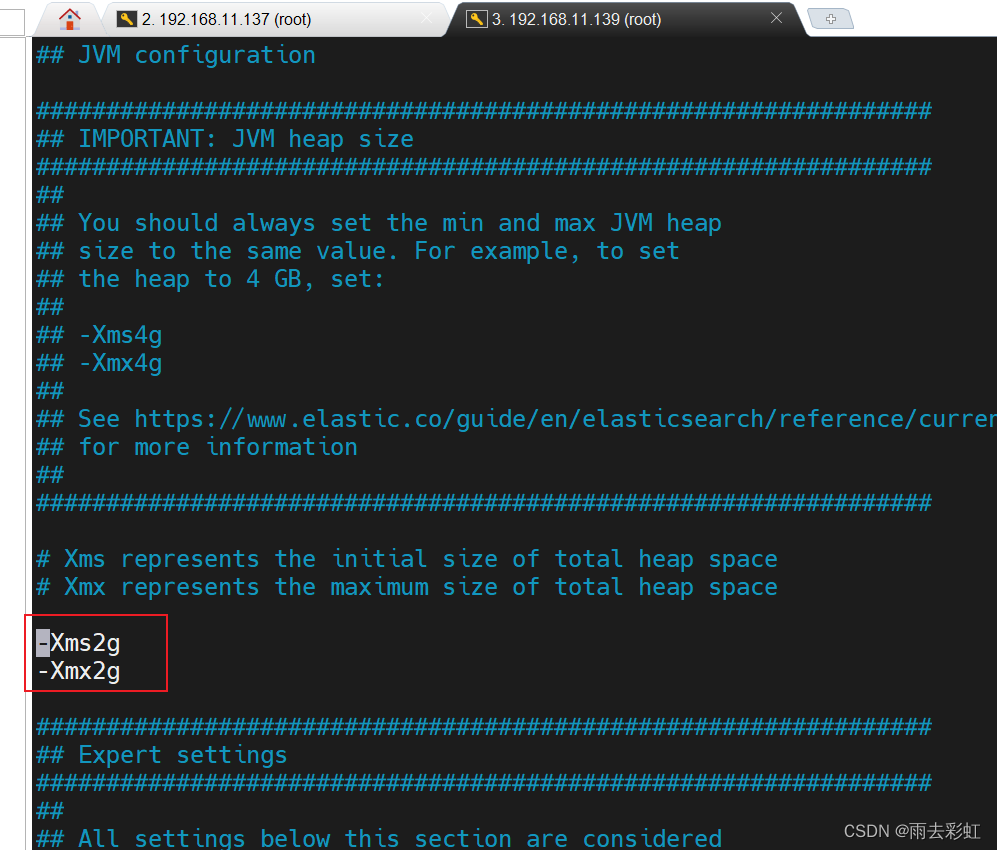
vim jvm.options
原来内容
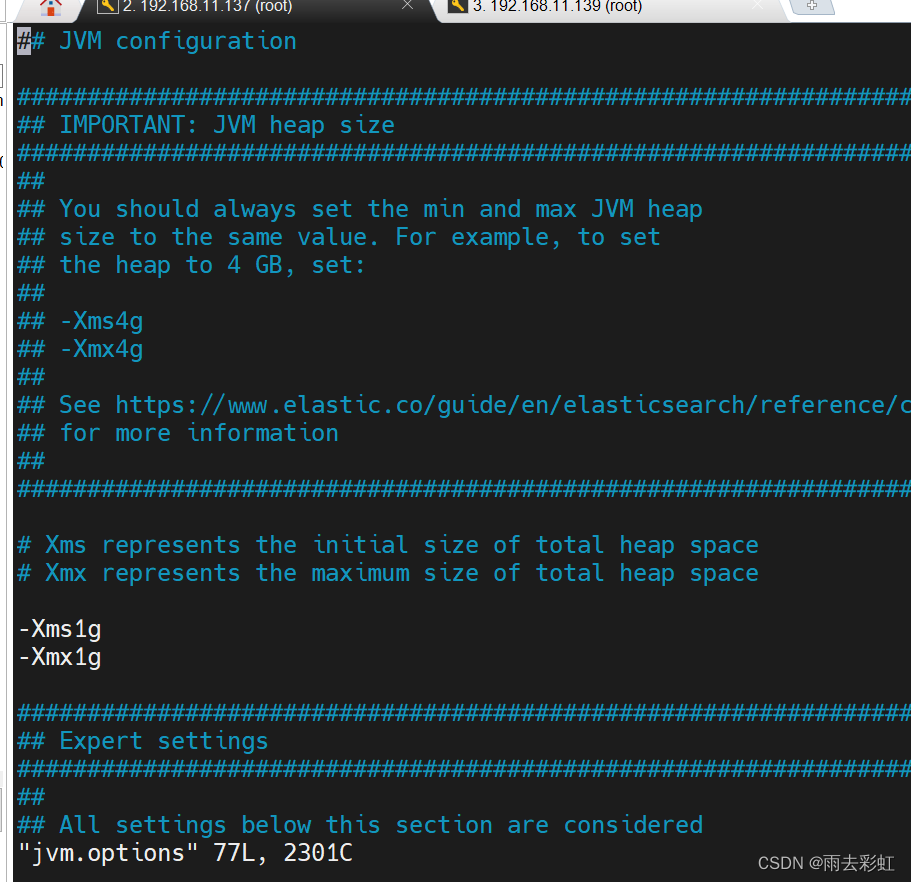 改为:
改为:
-Xms2g
-Xmx2g
③修改系统的配置文件
修改/etc/security/limits.conf
末尾追加
vim /etc/security/limits.conf
july soft nofile 65536
july hard nofile 65536
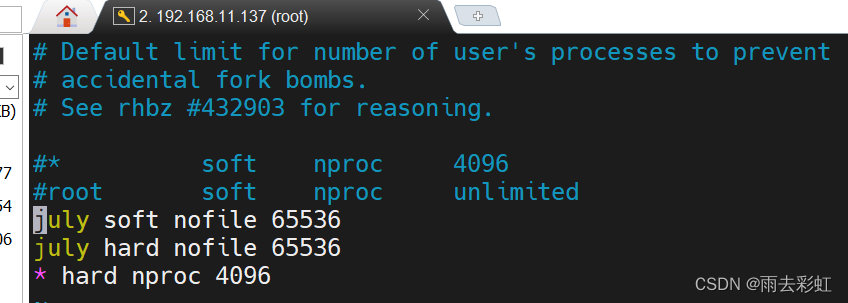
修改/etc/security/limits.d/20-nproc.conf
vim /etc/security/limits.d/20-nproc.conf
july soft nofile 65536
july hard nofile 65536
* hard nproc 4096
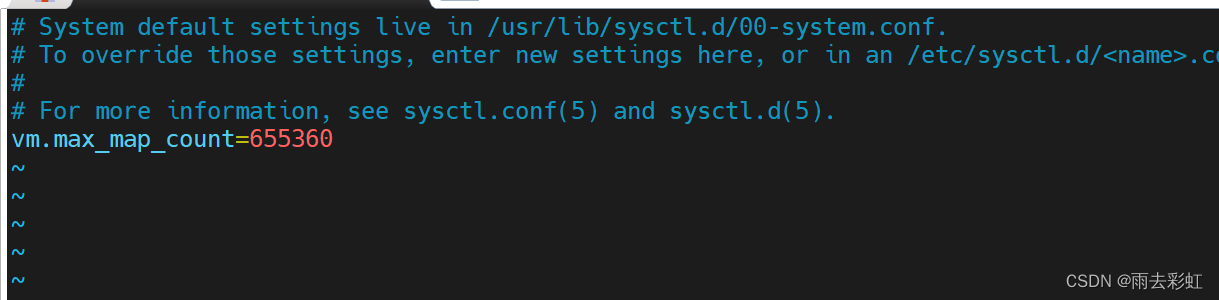
修改/etc/sysctl.conf
vim /etc/sysctl.conf
追加内容
vm.max_map_count=655360
重新加载
sysctl -p
④启动es
cd /opt/software/elasticsearch-7.6.1
bin/elasticsearch
如果出现如下报错
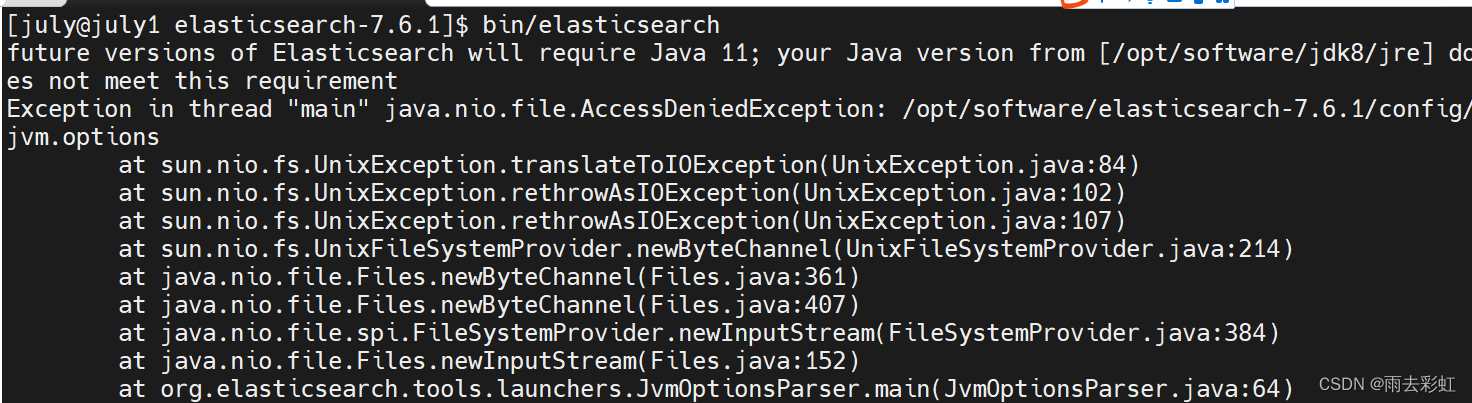
检查你当前的用户是不是root用户
如果是请执行
su july
检查es这个文件夹是不是july所有者
cd /opt/software
ll
我都是root
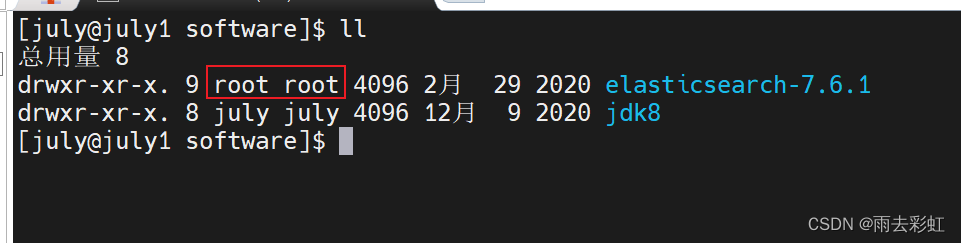
修改为july用户(要在root用户下执行该操作)
chown -R july:july /opt/software/elasticsearch-7.6.1
修改完成后在elasticsearch-7.6.1目录下再次执行
bin/elasticsearch
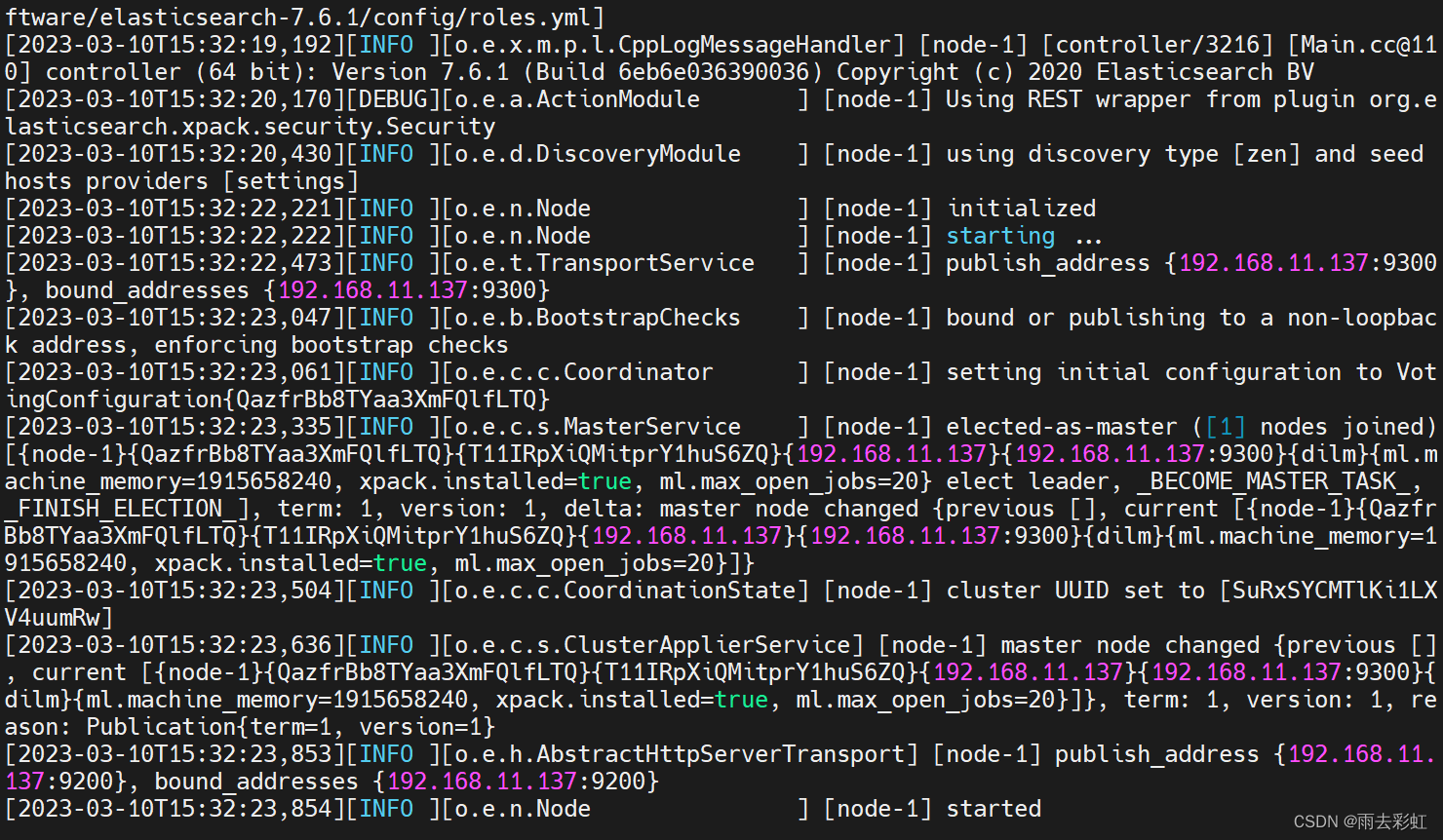
测试是否启动成
浏览器访问地址,你的虚拟机地址加端口号
http://192.168.11.137:9200/
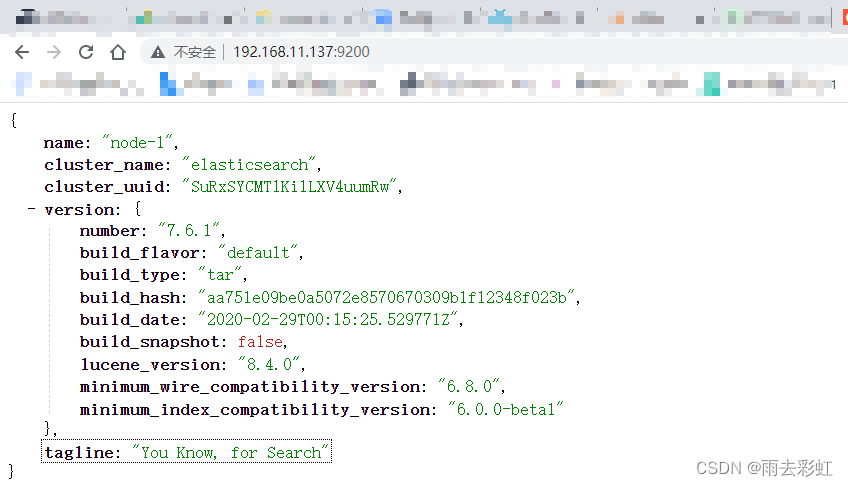
至此,单机的es已经搭建完成。
ctrl+C退出es
首先在第一台的基础上
修改es配置文件
cd /opt/software/elasticsearch-7.6.1/config/
vim elasticsearch.yml
原来配置的
#集群名称
cluster.name: cluster-es
#节点名称,每个节点的名称不能重复
node.name: node-1
#ip地址,每个节点的地址不能重复
network.host: july1
#是不是有资格主节点
node.master: true
node.data: true
http.port: 9200
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-1"]
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["july1:9300","july2:9300","july3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
使用分发脚本,把es这个文件夹分发到其他虚拟机
xsync /opt/software/
分发完成之后需要删除/data/目录下删除nodes文件!!!!这一点非常重要,不然后后续启动的时候发现不到其他节点信息,三台都要删除!!!
cd /opt/software/elasticsearch-7.6.1/data
rm -rf nodes/
使用分发脚本把修改系统文件的那些内容分发到其他虚拟机(如果在july用户下不行,切换到root进行分发)
xsync /etc/security/limits.conf
xsync /etc/security/limits.d/20-nproc.conf
xsync /etc/sysctl.conf
然后同步修改其他几台虚拟机
只需要把特定名称和ip地址修改成对应虚拟机名称即可
#集群名称
cluster.name: cluster-es
#节点名称,每个节点的名称不能重复
node.name: node-2
#ip地址,每个节点的地址不能重复
network.host: july2
#是不是有资格主节点
node.master: true
node.data: true
http.port: 9200
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-2"]
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["july1:9300","july2:9300","july3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
#集群名称
cluster.name: cluster-es
#节点名称,每个节点的名称不能重复
node.name: node-3
#ip地址,每个节点的地址不能重复
network.host: july3
#是不是有资格主节点
node.master: true
node.data: true
http.port: 9200
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-3"]
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["july1:9300","july2:9300","july3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
分别启动每台虚拟机,每台执行如下命令
bin/elasticsearch
其余两台启动报错
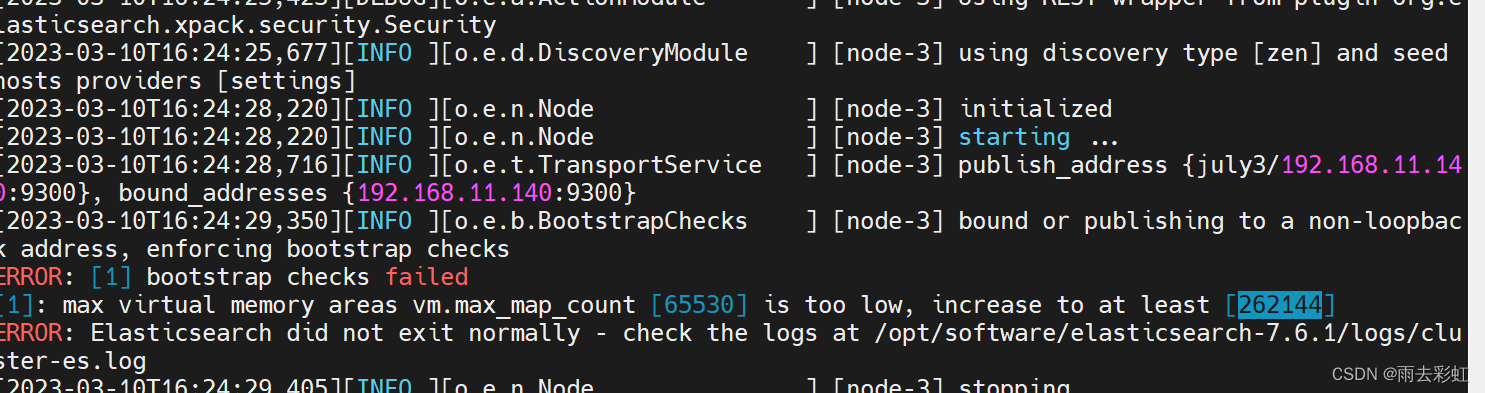
从报错可以看出
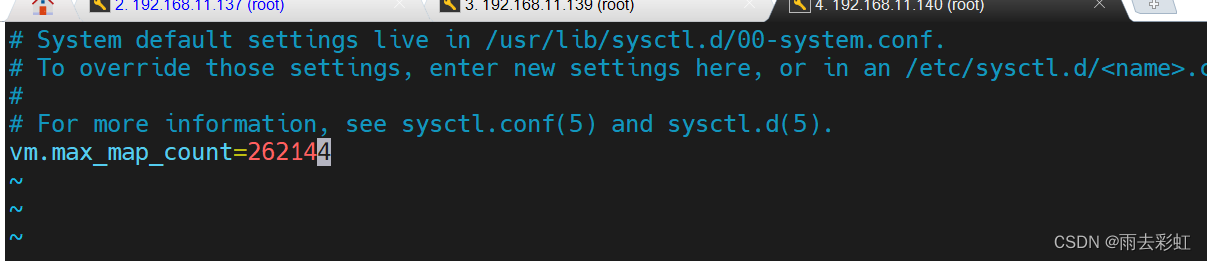
vm.max_map_count = 65530这个还是配置小了
修改配置为(在root用户下修改,然后在july用户下再次启动即可)
vm.max_map_count = 262144
重新加载
sysctl -p
查询集群状态
http://192.168.11.137:9200/_cat/nodes
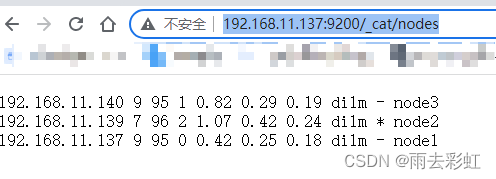
集群搭建结束。
root用户下
cd /etc/init.d
vim elasticsearch
因为脚本需要使用非root用户,所以指定为july用户。还有es安装的地址
前三行内容

#!/bin/sh
# chkconfig: - 85 15
#description: elasticsearch
export ES_HOME=/opt/software/elasticsearch-7.6.1
case "$1" in
start)
su july<<!
cd $ES_HOME
./bin/elasticsearch -d -p pid
!
echo "elasticsearch startup"
;;
stop)
kill -9 `cat $ES_HOME/pid`
echo "elasticsearch stopped"
;;
restart)
kill -9 `cat $ES_HOME/pid`
echo "elasticsearch stopped"
su july<<!
cd $ES_HOME
./bin/elasticsearch -d -p pid
!
echo "elasticsearch startup"
;;
*)
echo "start|stop|restart"
;;
esac
exit $?
①设置可执行
chmod 777 elasticsearch
配置开机启动相关
②添加系统服务
chkconfig --add elasticsearch
③启动服务
systemctl start elasticsearch
④设置开机自启
chkconfig elasticsearch on
systemctl enable elasticsearch
root用户下分发脚本到其他两台虚拟机,然后执行①-④步即可
xsync elasticsearch
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
我有一个关于配置elasticsearch以连接AWSelasticsearch服务以在生产环境中运行项目的问题。我的gem文件:gem'searchkick'gem'faraday_middleware-aws-signers-v4'gem'aws-sdk','~>2'gem"elasticsearch",">=1.0.15"引用:https://github.com/ankane/searchkick我的config/initializers/elasticsearch.rb文件:require"faraday_middleware/aws_signers_v4"ENV["ELAS
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表