MinIO基于Apache License 2.0开源协议的对象存储服务。它兼容Amazon S3云存储接口。适合存储非结构化数据,如图片,音频,视频,日志等。对象文件最大可以达到5TB
官网:https://min.io/ 中文 http://minio.org.cn/
MiniO 使用纠删码机制来保证高可靠性,使用highwayhash来处理数据损坏(Bit Rot Protection)。关于纠删码,简单来说就是可以通过数学计算,把丢失的数据进行还原,它可以将n份原始数据,增加m份数据,并能通过n+m份中的任意n份数据,还原为原始数据。即如果有任意小于等于m份的数据失效,仍然能通过剩下的数据还原出来。
文件对象上传到Minio,会在对应的数据存储磁盘中,以Bucket名称为目录,文件名称为下一级目录,文件下是part.1(超过10M时候才会有此文件)和xl.meta,前者是编码数据块以及检验块,后者是元数据文件
安装路径 /usr/local/soft
wget https://dl.min.io/server/minio/release/darwin-amd64/minio
chmod +x minio
./minio server /mnt/data 
访问 http://192.168.150.129:41922 用户名密码:minioadmin
发现图中有警告:WARNING: Console endpoint is listening on a dynamic port (41922), please use --console-address ":PORT" to choose a static port.
目前启动的时候端口是动态的,只要在启动命令后加上 --console-address ":PORT" ,就变成静态端口
再次启动
./minio server /mnt/data --console-address ":9001"
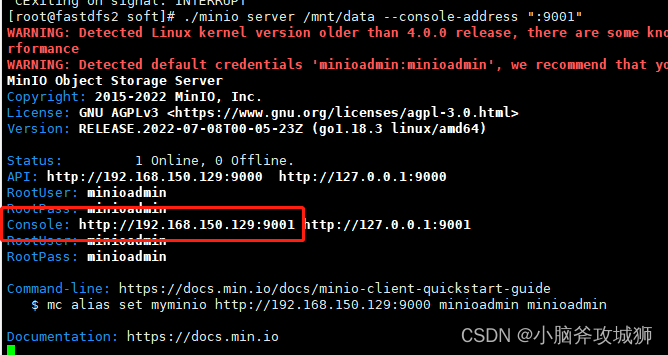
图中还有警告:WARNING: Detected default credentials 'minioadmin:minioadmin', we recommend that you change these values with 'MINIO_ROOT_USER' and 'MINIO_ROOT_PASSWORD' environment variables
意思是我们在启动的时候可以通过MINIO_ROOT_USER和MINIO_ROOT_PASSWORD设置用户密码访问
完整启动命令:
MINIO_ROOT_USER=admin MINIO_ROOT_PASSWORD=12345678 ./minio server /mnt/data --console-address ":9001"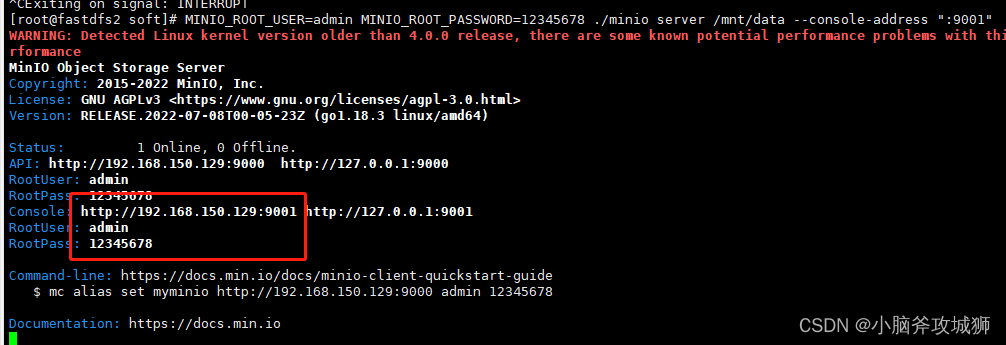
访问 http://192.168.150.129:9001 账号:admin 密码:12345678
安装docker命令(如果已经安装就跳过此步骤)
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install docker-ce
启动docker
systemctl start docker
部署命令以及自定义用户名密码
docker run -d -p 9000:9000 -p 9001:9001 --name minio \
-e "MINIO_ROOT_USER=admin" \
-e "MINIO_ROOT_PASSWORD=12345678" \
-v /mnt/data:/data \
-v /mnt/config:/root/.minio \
minio/minio server /data --console-address ":9001"获取容器ID
在容器中使用Docker命令, 你需要知道这个容器的 容器ID 。 为了获取 Container ID, 运行docker ps -a
-a flag 确保你获取所有的容器(创建的,正在运行的,退出的),然后从输出中识别Container ID。
启动和停止容器
启动容器,你可以使用 docker start 命令。docker start <container_id>
停止一下正在运行的容器, 使用 docker stop 命令。docker stop <container_id>
MinIO容器日志
获取MinIO日志,使用 docker logs 命令。docker logs <container_id>
监控MinioDocker容器
监控MinIO容器使用的资源,使用 docker stats 命令.docker stats <container_id>
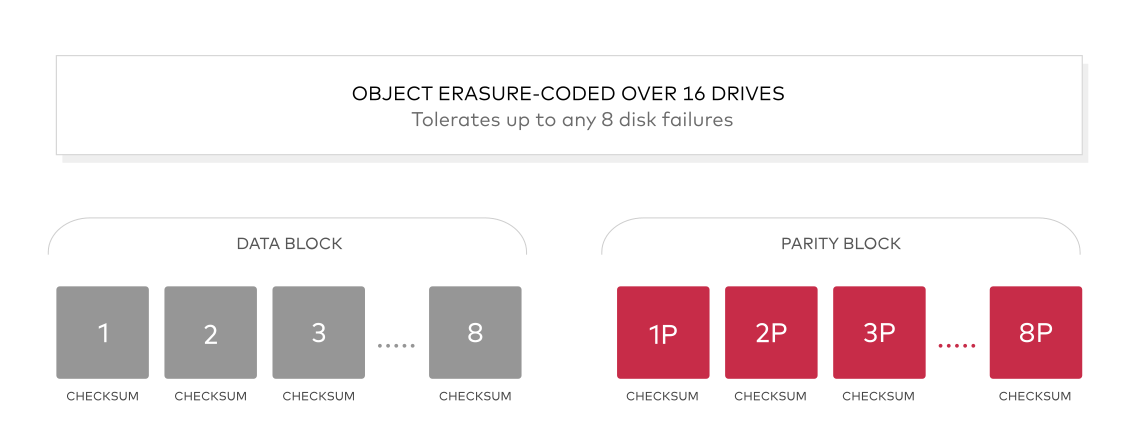
Minio使用纠删码erasure code和校验和checksum来保护数据免受硬件故障和无声数据损坏。 即便您丢失一半数量(N/2)的硬盘,您仍然可以恢复数据。
纠删码是一种恢复丢失和损坏数据的数学算法, Minio采用Reed-Solomon code将对象拆分成N/2数据和N/2 奇偶校验块。 这就意味着如果是12块盘,一个对象会被分成6个数据块、6个奇
偶校验块,你可以丢失任意6块盘(不管其是存放的数据块还是奇偶校验块)
docker run -d -p 9000:9000 -p 9001:9001 --name minio-ec \
-v /mnt/data1:/data1 \
-v /mnt/data2:/data2 \
-v /mnt/data3:/data3 \
-v /mnt/data4:/data4 \
-v /mnt/data5:/data5 \
-v /mnt/data6:/data6 \
-v /mnt/data7:/data7 \
-v /mnt/data8:/data8 \
minio/minio server /data{1...8} --console-address ":9001"分布式Minio可以让你将多块硬盘(甚至在不同的机器上)组成一个对象存储服务。由于硬盘分布在不同的节点上,分布式Minio避免了单点故障。
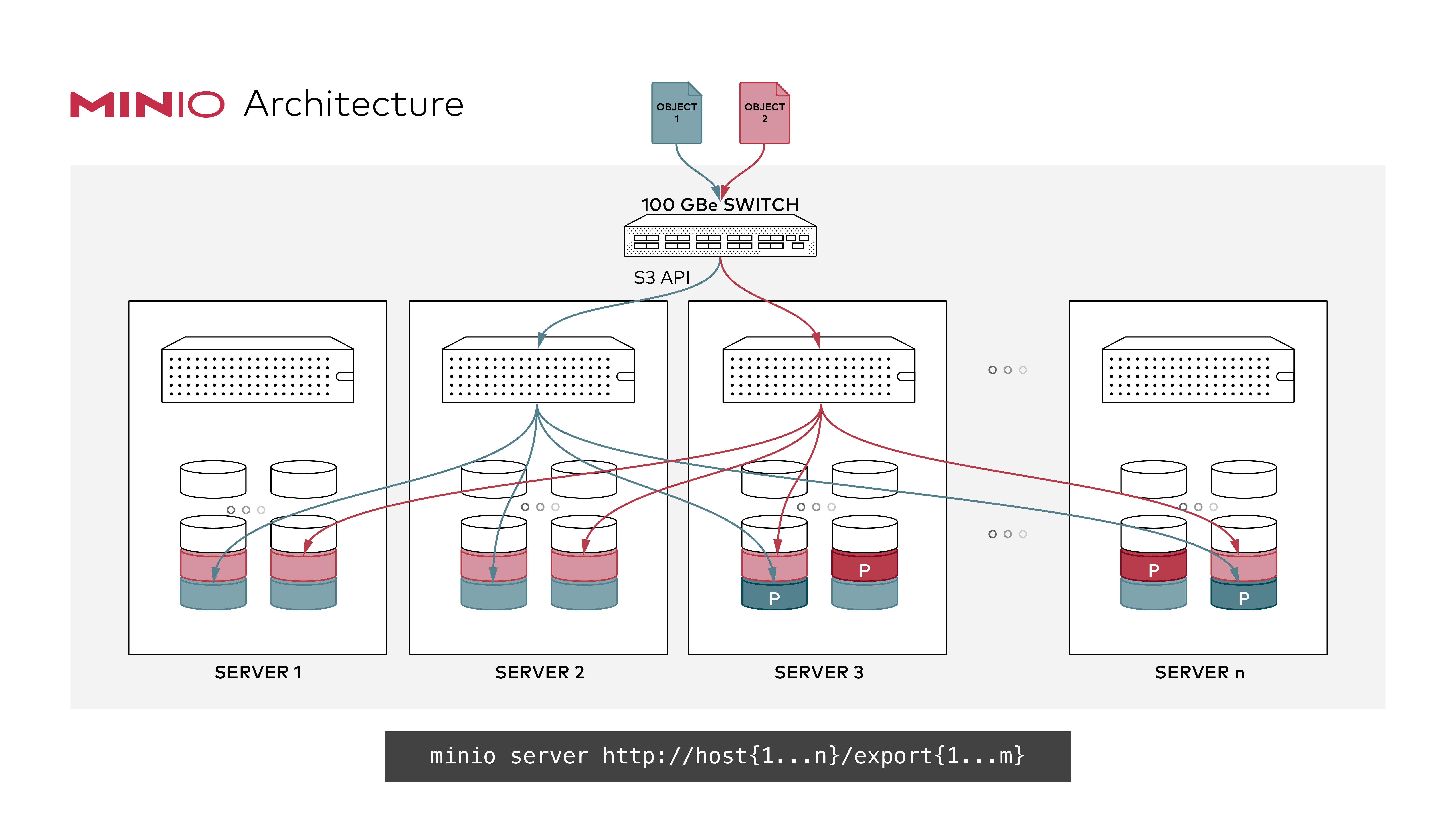
分布式存储,很关键的点在于数据的可靠性,即保证数据的完整,不丢失,不损坏。只有在可靠性实现的前提下,才有了追求一致性、高可用、高性能的基础。而对于在存储领域,一般对于保证数据可靠性的方法主要有两类,一类是冗余法,一类是校验法。
冗余
冗余法最简单直接,即对存储的数据进行副本备份,当数据出现丢失,损坏,即可使用备份内容进行恢复,而副本备份的多少,决定了数据可靠性的高低。这其中会有成本的考量,副本数据越多,数据越可靠,但需要的设备就越多,成本就越高。可靠性是允许丢失其中-份数据。当前已有很多分布式系统是采用此种方式实现,如Hadoop的文件系统(3个副本),Redis的集群,MvSOL的主备模式等。
校险
校验法即通过校验码的数学计算的方式,对出现丢失、损坏的数据进行校验,还原。注意,这里有两个作用,一个校验,通过对数据进行校验和(checksum)进行计算,可以检查数据是否完整,有无损坏或更改,在数据传输和保存时经常用到,如TCP协议:二是恢复还原通过对数据结合校验码,通过数学计算,还原丢失或损坏的数据,可以在保证数据可章的前提下,降低冗余,如单机硬盘存储中的RAID技术,纠删码(ErasureCode)技术等。Minlo采用的就是纠删码技术。
分布式Minio采用 纠删码来防范多个节点宕机和位衰减bit rot。
分布式Minio至少需要4个硬盘,使用分布式Minio自动引入了纠删码功能。
单机Minio服务存在单点故障,相反,如果是一个有N块硬盘的分布式Minio,只要有N/2硬盘在线,你的数据就是安全的。不过你需要至少有N/2+1个硬盘来创建新的对象。
例如,一个16节点的Minio集群,每个节点16块硬盘,就算8台服務器宕机,这个集群仍然是可读的,不过你需要9台服務器才能写数据。
注意,只要遵守分布式Minio的限制,你可以组合不同的节点和每个节点几块硬盘。比如,你可以使用2个节点,每个节点4块硬盘,也可以使用4个节点,每个节点两块硬盘,诸如此类。
Minio在分布式和单机模式下,所有读写操作都严格遵守read-after-write一致性模型。
启动一个分布式Minio实例,你只需要把硬盘位置做为参数传给minio server命令即可,然后,你需要在所有其它节点运行同样的命令。
MINIO_ROOT_USER并在所有节点上导出。MINIO_ROOT_PASSWORD如果未导出,minioadmin/minioadmin则应使用默认凭据。/export,则将其作为参数传递/export/data给 MinIO 服务器。MINIO_DOMAIN应为桶 DNS 样式支持定义和导出环境变量。四台服务器开启时间同步,命令:
yum -y install ntp
systemctl enable ntpd
systemctl start ntpd
timedatectl set-ntp yes
ntpdate -u cn.pool.ntp.org
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
watch -n 1 'date'关闭防火墙
1.首先查看防火墙状态:
service iptables status
2.永久性生效,重启后不会复原
开启:
chkconfig iptables on
关闭:
chkconfig iptables off
3.即时生效,重启后复原
开启:
service iptables start
关闭:
service iptables stop
4.设置后重启:
reboot
每台服务器中都要配置如下hostname
| 服务器 IP | hostname | 说明 |
| 192.168.150.128 | minio1.com | Minio节点 |
| 192.168.150.129 | minio2.com | Minio节点 |
| 192.168.150.130 | minio3.com | Minio节点 |
| 192.168.150.131 | minio4.com | Minio节点 |
| 192.168.150.132 | minio5.com | Nginx负载均衡 |
启动分布式Minio实例,4个节点,每节点4块盘,需要在4个节点上都运行下面的命令。
1、给每台服务器新增一块硬盘,这里使用的10G(这里使用的是虚拟机,自行百度怎么添加,不使用新硬盘部署集群会报错)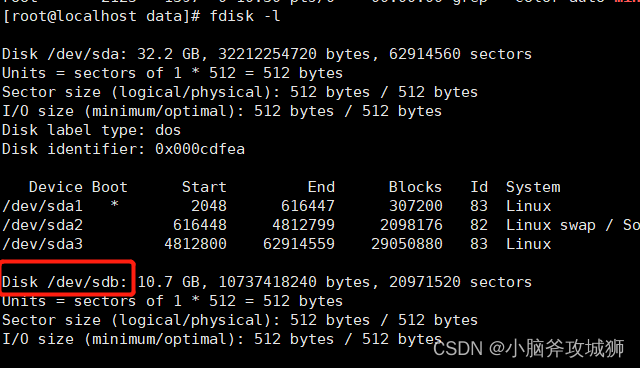
2、格式化硬盘 (不格式化会提示只读模式)
mkfs.ext4 /dev/sdb
3、创建minio数据目录,挂载数据磁盘到数据目录
mkdir -p /data/minio{1..4} // 模拟四块硬盘
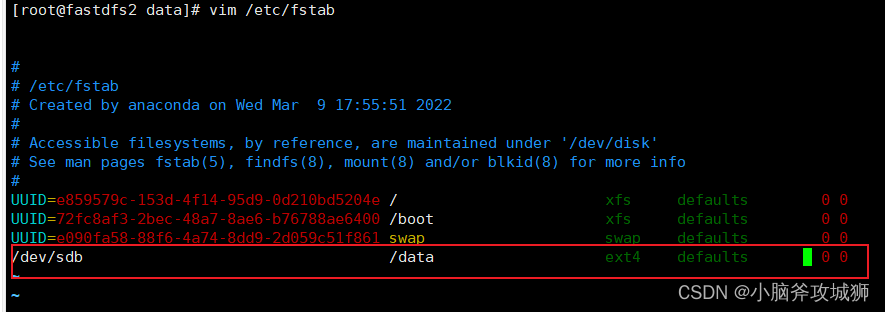
mount /dev/sdb /data
实现永久挂载需要配置 vim /etc/fstab
4、minio-cluster.sh脚本
4.1 第一中写法
#!/bin/bash
export MINIO_ROOT_USER=admin
export MINIO_ROOT_PASSWORD=12345678
nohup /usr/local/soft/minio server --address ":9000" --console-address ":9001" \
http://192.168.150.128:9000/data/minio1 \
http://192.168.150.128:9000/data/minio2 \
http://192.168.150.128:9000/data/minio3 \
http://192.168.150.128:9000/data/minio4 \
http://192.168.150.129:9000/data/minio1 \
http://192.168.150.129:9000/data/minio2 \
http://192.168.150.129:9000/data/minio3 \
http://192.168.150.129:9000/data/minio4 \
http://192.168.150.130:9000/data/minio1 \
http://192.168.150.130:9000/data/minio2 \
http://192.168.150.130:9000/data/minio3 \
http://192.168.150.130:9000/data/minio4 \
http://192.168.150.131:9000/data/minio1 \
http://192.168.150.131:9000/data/minio2 \
http://192.168.150.131:9000/data/minio3 \
http://192.168.150.131:9000/data/minio4 >/data/minio.log 2>&1 &4.2 第二中写法
#!/bin/bash
export MINIO_ROOT_USER=admin
export MINIO_ROOT_PASSWORD=12345678
nohup /usr/local/soft/minio server --address ":9000" --console-address ":9001" http://minio{1...4}.com:9000/data/minio{1...4} >/data/minio-data.log 2>&1 &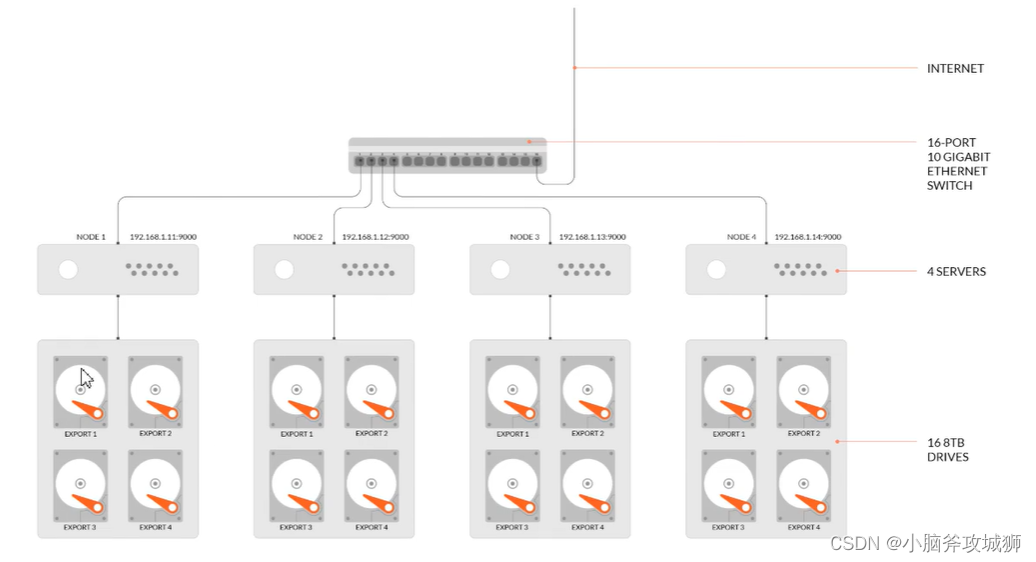
5、Nginx负载均衡配置
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
# Minio配置---开始
upstream minio_console {
server 192.168.150.128:9001 max_fails=3 fail_timeout=5s;
server 192.168.150.129:9001 max_fails=3 fail_timeout=5s;
server 192.168.150.130:9001 max_fails=3 fail_timeout=5s;
server 192.168.150.131:9001 max_fails=3 fail_timeout=5s;
}
upstream minio_api {
server 192.168.150.128:9000 max_fails=3 fail_timeout=5s;
server 192.168.150.129:9000 max_fails=3 fail_timeout=5s;
server 192.168.150.130:9000 max_fails=3 fail_timeout=5s;
server 192.168.150.131:9000 max_fails=3 fail_timeout=5s;
}
server {
listen 9001; #或者用80端口也可以
server_name 192.168.150.132; #可以用域名
location / {
#Nginx默认是上传一个不能超过1M大小的文件
#client_body_buffer_size 配置请求体缓存区大小, 不配的话,
#client_body_temp_path 设置临时文件存放路径。只有当上传的请求体超出缓存区大小时,才会写到临时文件中
#client_max_body_size 设置上传文件的最大值
client_max_body_size 600M;
client_body_buffer_size 600M;
proxy_next_upstream http_500 http_502 http_503 http_504 error timeout invalid_header;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://minio_console;
expires 0;
}
}
server {
listen 9000;
server_name 192.168.150.132; #可以用域名
location / {
#Nginx默认是上传一个不能超过1M大小的文件
#client_body_buffer_size 配置请求体缓存区大小, 不配的话,
#client_body_temp_path 设置临时文件存放路径。只有当上传的请求体超出缓存区大小时,才会写到临时文件中
#client_max_body_size 设置上传文件的最大值
client_max_body_size 600M;
client_body_buffer_size 600M;
proxy_next_upstream http_500 http_502 http_503 http_504 error timeout invalid_header;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://minio_api;
expires 0;
}
}
# Minio配置---结束
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
# another virtual host using mix of IP-, name-, and port-based configuration
#
#server {
# listen 8000;
# listen somename:8080;
# server_name somename alias another.alias;
# location / {
# root html;
# index index.html index.htm;
# }
#}
# HTTPS server
#
#server {
# listen 443 ssl;
# server_name localhost;
# ssl_certificate cert.pem;
# ssl_certificate_key cert.key;
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 5m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
# location / {
# root html;
# index index.html index.htm;
# }
#}
}
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A